EndPrompt:短序列也能撑起 64K——给 LLM 长上下文塞一个"终点路标"
开篇:一个让我盯了半天的实验设置
你有没有想过这样一个问题:要把一个 8K 上下文的 LLaMA 扩到 64K,到底是不是非得拿 64K 的真实长序列去训?
工程上的直觉是肯定的。注意力是 \(O(n^2)\),输入越长显存炸得越狠,但既然目标窗口是 64K,模型不亲眼看一眼"距离上万 token 的 token 之间该怎么互相 attend",怎么可能学得会?所以业界的标准动作就是凑长文本、上 FlashAttention、上序列并行、咬牙跑全长度微调,能跑出来一个能用的 64K 模型就算交差。
这篇 2026 年 5 月挂出来的 paper——EndPrompt: Efficient Long-Context Extension via Terminal Anchoring(arXiv: 2605.14589)——直接把这个假设掀了。
他们的做法说起来荒诞:训练序列我就用短的,但我在末尾贴一小段"END / Summary / Conclusion"之类的 terminal prompt,然后偷偷把它的位置编号改成接近 64K 的位置上。物理序列没变长,显存没炸,模型却以为自己看到了一对相距 60K 的 token 在互相注意。
听到这个设计我第一反应有点怀疑:就这?真能 work?
但表格啪一甩——RULER 平均 76.03,把 LongLoRA(72.95)、LCEG(72.24)、甚至全长度微调(69.23)全干下来了,显存还降一半,速度还快 40%。
这就值得好好聊聊了。
核心摘要
EndPrompt(论文里也叫 ET)解决的是一件很现实的事——扩上下文窗口太贵了。传统路子要么硬上全长度训练(\(O(n^2)\) 显存和算力都是噩梦),要么做 chunk-based 模拟(PoSE 那一类,把连续文本切块再重排位置,但切了就破坏语义连续性)。
作者的核心 trick 是:把原始短序列原封不动留下来作为"第一段",在末尾粘一小段 terminal prompt 作为"第二段",然后把第二段的位置编号直接抬到目标窗口的末尾(比如目标 64K,那第二段的位置就被赋成 [64K-b, 64K-1])。这样物理序列总长还是几 K,但注意力机制里"看到的"相对距离已经横跨了 60K。
理论上他们用 RoPE 的频谱性质 + PI(Position Interpolation)的平滑约束 + Transformer 参数共享,论证了这种稀疏位置监督为什么能泛化到中间那些"从来没见过的距离"。
实测上:LLaMA-3 8B 从 8K 扩到 64K,RULER 76.03 拿下,LongBench 38.30 拿下,显存从全长度微调的 76 GB 降到 36.52 GB(降 52%),训练时间相对 LCEG 加速 1.77 倍。
我的判断:这是一篇"工程巧思 + 理论解释 + 实验交叉印证"都到位的扎实工作。它的核心命题——"长上下文能力不一定靠密集长序列训出来,稀疏的结构化位置信号就够"——是真的有可能改变长窗口扩展的工程范式的。
论文信息
- 标题:EndPrompt: Efficient Long-Context Extension via Terminal Anchoring
- 作者:Han Tian, Luxuan Chen, Xinran Chen, Rui Kong, Fang Wang, Jiamin Chen, Jinman Zhao, Yuchen Li, Jiashu Zhao, Shuaiqiang Wang, Haoyi Xiong, Dawei Yin(共 12 位)
- arXiv:https://arxiv.org/abs/2605.14589
- 提交日期:2026 年 5 月 14 日
- 代码:https://github.com/clx1415926/EndPrompt
- 领域:cs.CL(自然语言处理 / 大语言模型)
一、为什么"扩上下文"这件事这么贵
聊方法之前先把背景捋一遍,不然后面的"节省"没法体感。
把一个预训练好的 8K 模型扩到 64K,业界目前主要这几条路:
全长度微调(Full FT)——最朴素,直接拿 64K 的真实长文本继续训。问题是 attention 的复杂度是 \(O(n^2)\),64K vs 8K 就是 64 倍的算量。即使有 FlashAttention 和序列并行救场,单卡显存还是顶不住,集群规模和训练时间都得翻倍。论文里的数据:64K 全长度微调要 76 GB 显存,跑一轮要 20.5 小时。
Position Interpolation(PI,Chen et al. 2023)——把位置编号"压缩"一下,让原来训过的相对距离覆盖到更长的物理距离。便宜但只能算个起点,纯 PI 不微调效果不行。
LongLoRA(Chen et al. 2023)——结合 shifted sparse attention 和 LoRA,把全微调的代价压一压。但仍然要看全长度的输入,注意力结构还被改了。
PoSE / Positional Skip-Embedding(Zhu et al. 2023)——这个有意思,做"模拟长上下文"。它把短序列切成几个 chunk,给每个 chunk 重新分配位置编号,让 chunk 之间出现长距离。但代价是把连续文本切断了,语义依赖被破坏,next-token prediction 的监督质量就受损。
LCEG(Lu et al. 2024)——一个评估长上下文泛化的标准化协议,也被作为 baseline。
把这几个方法摆一起,你会看到一个共同的"路线依赖":所有人都默认,要让模型学会长距离注意力,就必须让它在训练时真的看到长距离——要么物理长(Full FT),要么虚拟长但切碎了(PoSE)。
EndPrompt 的提问是:
我们真的需要"密集观察"所有长距离吗?能不能只暴露关键的长距离——比如序列两端之间——其它中间距离让模型自己"插值"出来?
说实话,这个问题挑得挺漂亮的。它没有去优化"怎么把长序列训得更便宜",而是直接质疑"为什么一定要长序列"。
二、方法:把"终点"贴到 64K 的位置上
2.1 直觉先讲清楚
一句话版:保留原始短文本不动,在末尾粘个小尾巴(end prompt),但偷偷把这个尾巴的位置编号写成"靠近 64K 末端"的数字。
物理序列长度可能就 4K + 几个 token,但 RoPE 看到的"相对位置距离"已经横跨了整个 64K 窗口。
下面这张图我看完之后基本就懂方法了:
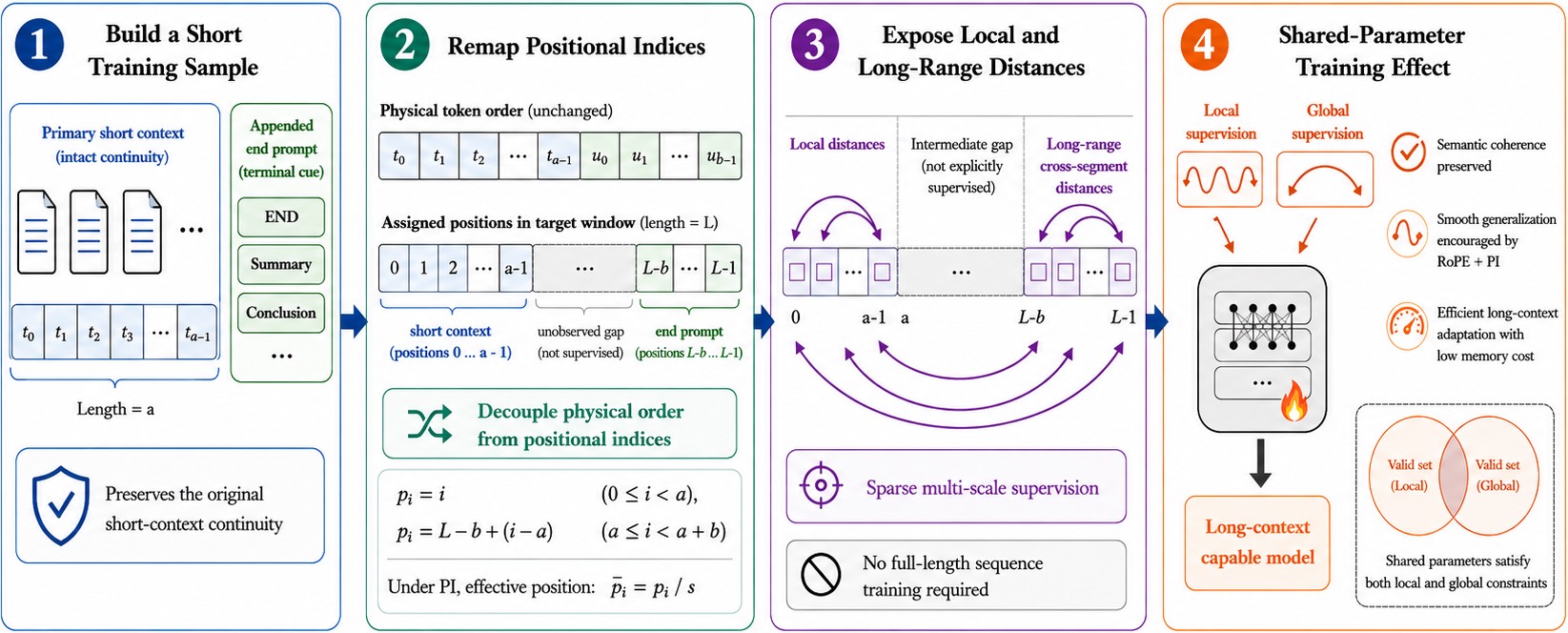
图1:EndPrompt 的四步方法概览。① 构造短训练样本(原始短上下文 + 末端的 end prompt 小尾巴);② 重映射位置索引(物理顺序不变,但位置编号被解耦到目标窗口的两端:短上下文在 [0, a-1],end prompt 在 [L-b, L-1]);③ 注意力同时看到局部距离与跨段长距离,中间 gap 不显式监督;④ 共享参数下的局部 + 全局监督,靠 RoPE + PI 的平滑性把 gap 区域自然外推。
2.2 数学上其实只有两行
设原始短序列 \(\mathbf{x} = (x_0, \ldots, x_{a-1})\),end prompt 是 \(\mathbf{e} = (e_0, \ldots, e_{b-1})\),目标窗口长度是 \(L\)。物理拼接:
物理长度还是 \(a + b\)(很短,比如 4K + 16)。但分配的位置索引这么搞:
也就是说:
- 第一段(原文):位置 \([0, a-1]\),老老实实
- 第二段(end prompt):位置 \([L-b, L-1]\),直接跳到目标窗口末端
配合 PI 把位置除以一个缩放因子 \(s\),得到 \(\bar{p}_\ell = p_\ell / s\)。
RoPE 下注意力分数其实只看相对距离的相位,所以第一段内部的 token 互相之间是短距离,end prompt 内部也是短距离,但 end prompt 里的 token 看回原文时,就是几乎接近 \(L\) 的长距离了。
2.3 关键观察:观察到的距离 vs 没观察到的距离
注意力(因果)实际能看到的"相对距离集合"是:
- \([0, a-1]\):第一段内部
- \([0, b-1]\):end prompt 内部
- \([L-a-b+1, L-1]\):跨段,end prompt 看回原文的长距离
而中间这段距离从来没被看过:
这是个相当大的"盲区"。比如 \(a = 4096\)、\(b = 16\)、\(L = 65536\),那 gap 大概是 \([4096, 61424]\)——中间 5 万多种距离一个都没监督过。
直觉上你会担心:模型见过短距离也见过超长距离,但中间一大段没见过,会不会推理时一遇到"中等长度"就崩?
作者的回答是:不会崩,因为 RoPE + PI 的频谱结构给了平滑性约束。
2.4 为什么 gap 能被自然填上
这段是论文里最有理论味道的部分。RoPE 下,注意力分数可以写成:
它是一个有限三角多项式——这件事很关键,因为有限三角多项式的导数是有界的。PI 把角频率从 \(\theta_j\) 缩到 \(\theta_j / s\),于是:
人话翻译:PI 让注意力分数沿"距离"维度变化得很缓,不能在两个相邻距离上突然剧烈跳动。
这就是关键。
短距离的注意力行为被局部监督钉住,长距离(接近 \(L\))的注意力行为被 end prompt 跨段监督钉住,而 PI 强制中间不能有剧烈震荡——所以 gap 区域只能"平滑地"在这两个锚点之间插值过去。
再加上 Transformer 的 \(Q\)、\(K\) 投影是全距离共享的同一组参数,长距离监督直接约束了局部参数,反过来局部监督也约束了长距离参数。两边一起收紧,gap 自然就稳了。
作者把这件事写成"可行参数集合"的语言:
只有同时满足局部和全局两条监督的参数集合才会被选出来。这相当于一个隐式正则,把那些"短的好、长的崩"的退化解排除了。
2.5 end prompt 选什么有关系吗?
很有意思的是——基本没关系。
作者试了三种:
- EP_1:
"This is the end of text, please pay attention here"(完整自然语言) - EP_2:
<|eot_id|>(LLaMA-3 原生的结束 token) - EP_3:
"End."(两个字符)
效果如下:
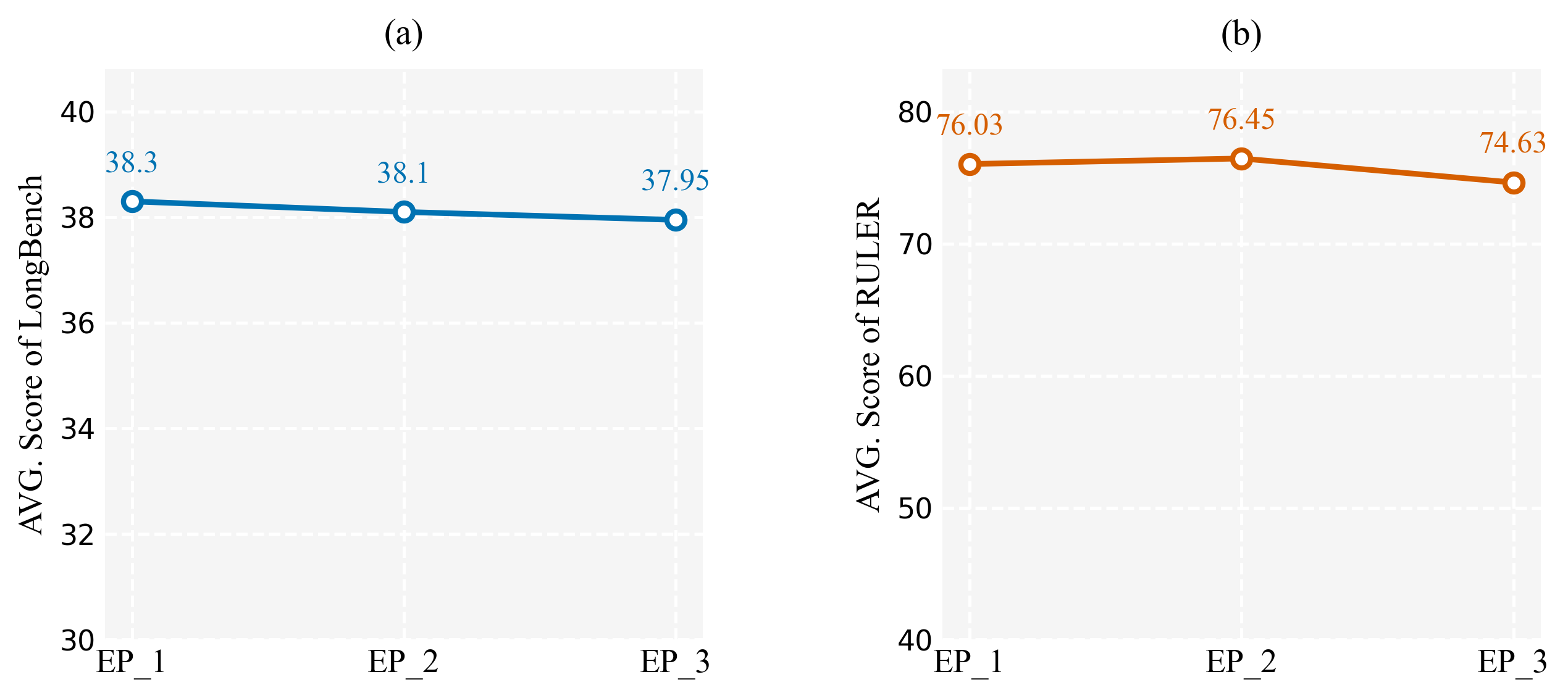
图2:三种 end prompt 在 LongBench(左)和 RULER(右)上的得分对比。LongBench 上 38.30 → 37.95,波动不到 0.4 分;RULER 上 76.03 / 76.45 / 74.63,最大波动也就 1.8 分。基本可以认为对具体 prompt 选什么不敏感。
这就说明一件事:起作用的是"结构性位置"(末端锚点),而不是 prompt 的具体语义。换句话说,模型不是在记忆这几个字,而是在利用"序列末端这个位置"作为长距离注意力的稳定支点。
这一点对工程上很友好——你不需要费劲调 prompt engineering,随便选个短结尾都行。
三、实验:数字真的能打吗?
3.1 主表:RULER 上的全面胜出
RULER 是专门测长上下文能力的合成 benchmark,包含 needle-in-a-haystack(NIAH)的各种变种、变量追踪(Vt)、Common Word Extraction(Cwe)、Frequent Word Extraction(Fwe)等任务。
LLaMA-3 8B,从 8K 扩到 64K,1B token 训练预算:
| 任务 | ET | LCEG | LongLoRA | Full FT |
|---|---|---|---|---|
| Niah_S1 | 100.00 | 100.00 | 100.00 | 97.56 |
| Niah_S2 | 91.28 | 99.28 | 99.44 | 98.12 |
| Niah_S3 | 92.92 | 79.68 | 86.20 | 72.72 |
| Niah_M1 | 90.20 | 96.12 | 97.36 | 94.52 |
| Niah_M2 | 85.48 | 76.48 | 77.96 | 90.24 |
| Niah_M3 | 62.92 | 45.72 | 51.92 | 56.20 |
| Niah_MV | 81.67 | 77.81 | 81.56 | 62.34 |
| Niah_MQ | 82.06 | 83.88 | 83.79 | 62.56 |
| Vt | 82.00 | 68.18 | 65.70 | 68.56 |
| Cwe | 42.82 | 53.14 | 50.97 | 38.32 |
| Fwe | 83.53 | 63.01 | 58.17 | 58.10 |
| Qa_1 | 51.88 | 53.04 | 52.40 | 55.68 |
| Qa_2 | 41.60 | 42.84 | 42.92 | 45.04 |
| 平均 | 76.03 | 72.24 | 72.95 | 69.23 |
几个值得说道的地方:
第一,简单任务上大家都打满——Niah_S1 几乎所有方法都是 100。这说明 baseline 都不是垃圾,简单的"找针"任务对扩窗方法都不算挑战。
第二,复杂任务上 ET 拉开差距——Niah_S3、Niah_M3 这种多针/多步检索,ET 比第二名高出 6 到 17 个点;Vt(变量追踪)领先 LongLoRA 16.3 个点;Fwe 领先 25 个点。这才是真正的能力差异。
第三,Full FT 反而不是最强——这个挺有意思。直觉上花最多算力的方法应该效果最好,但 Full FT 平均 69.23,被三个"偷懒"方法都干翻了。说实话看到这里我愣了一下——这意味着"无脑给长序列"不仅贵,可能还主动制造了过拟合或者优化困难。
3.2 LongBench:真实任务下的优势更明显
| 方法 | Single-Doc QA | Multi-Doc QA | Summarization | Few-Shot Learning | Synthetic Task | Code Completion | 平均 |
|---|---|---|---|---|---|---|---|
| ET | 32.03 | 30.81 | 26.04 | 68.04 | 4.54 | 66.48 | 38.30 |
| LCEG | 27.86 | 28.51 | 23.88 | 61.81 | 5.31 | 46.86 | 36.61 |
| LongLoRA | 26.86 | 27.51 | 22.88 | 60.81 | 4.31 | 45.86 | 36.84 |
| Full FT | 28.86 | 29.51 | 24.88 | 62.81 | 6.31 | 47.86 | 35.63 |
最扎眼的是 Code Completion:ET 66.48 vs LongLoRA 45.86,差了快 21 个点。
代码补全是个"既需要全局结构感知、又需要局部细节匹配"的任务——你既要看懂上下文里定义过哪些函数、变量类型是什么,又要在具体位置生成准确的语法。ET 在这个任务上的大幅领先,间接说明它的长距离 + 局部依赖关系真的处理得比 baseline 干净。
不过我得说一句批判性的:Synthetic Task 上 ET 是 4.54,比 Full FT 的 6.31 低。这一栏分数都很低,但相对差距值得留意——可能在某些极端合成模式上,ET 的稀疏监督还是不如密集监督。论文没就这一栏多解释,有点遗憾。
3.3 训练效率:这才是 EndPrompt 的真正卖点
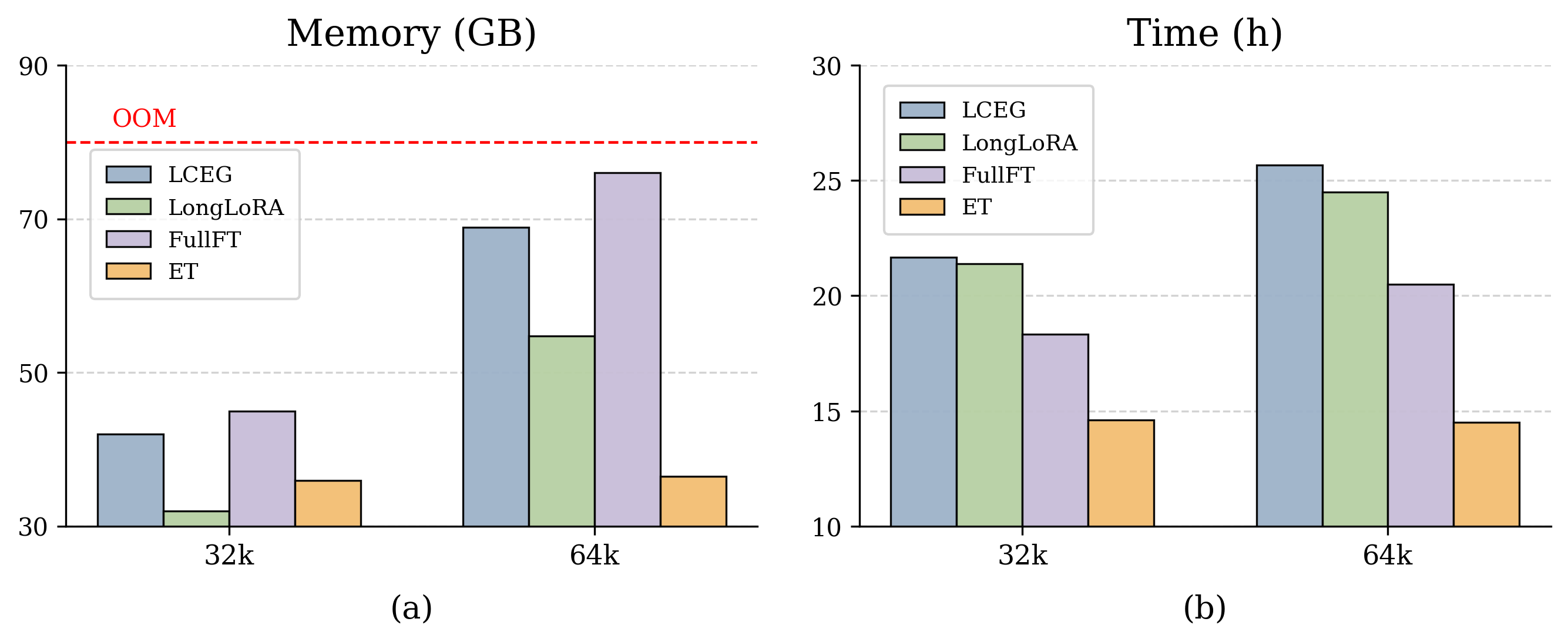
图3:在 32K 和 64K 两个目标长度下,四种方法的显存(左)和训练时间(右)。64K 设置下 Full FT 直接顶到 OOM 红线(76 GB),ET 只用 36.52 GB(降 52%);时间上 ET 比 LCEG 快 1.77 倍、比 LongLoRA 快 1.69 倍、比 Full FT 快 1.41 倍。
这张图我看完直接服气。
64K 上 Full FT 要 76 GB,ET 只要 36.52 GB——单卡 H100 就能跑 64K,原本要 A100-80GB 甚至 H200 才能跑。这种数量级的降本在工程上是质变,不是渐进改进。
时间上:
- ET vs LCEG: 1.77× 加速
- ET vs LongLoRA: 1.69× 加速
- ET vs Full FT: 1.41× 加速
道理也简单——物理序列短,attention 就便宜。64K 全长度训一个 step 是 \(O(64K^2)\),ET 实际跑的还是 \(O(4K^2)\) 左右的复杂度,差了 256 倍。当然 1.4-1.8 倍的实际加速没到 256 倍,是因为还有别的开销(数据加载、反向传播、梯度同步),但已经足够香了。
还有一个隐藏的工程好处不太被强调——长文本语料稀缺这件事被绕开了。要训 64K,理论上你得喂 64K 的高质量长文本,但真实世界里这种语料很少:长论文有,但太专业;长代码仓库有,但分布偏;长小说有,但风格单一。Full FT 受这个数据稀缺性的牵制非常严重。而 ET 用的是普通短上下文语料(4K 那个量级随便找),数据池一下子大几十倍,配比也好控制——这在做实际产品时是非常实在的好处。
四、消融实验:把所有该问的都问了一遍
ET 的消融做得比较扎实,几个维度都覆盖到:
4.1 换 base model 还行不行
| Base Model | RULER 平均 | LongBench 平均 |
|---|---|---|
| LLaMA-3 8B(默认) | 76.03 | 38.30 |
| Mistral-7B-v0.3 | 68.39 | 37.29 |
| LLaMA-2 7B | 45.82 | 31.16 |
Mistral 上还能用,LLaMA-2 7B 上掉得比较狠。作者解释为"底座模型本身预训练质量不同",这话其实是把锅甩给了 base model——LLaMA-2 本身长上下文能力就弱,扩出来效果差不全是 ET 的问题。但严格来说,这个 caveat 在你选 base model 时还是要警惕:老模型上 ET 不一定好用。
4.2 扩到更长行不行
| 扩展长度 | RULER 平均 | LongBench 平均 |
|---|---|---|
| 32K | 78.36 | 36.45 |
| 64K(默认) | 76.03 | 38.30 |
| 96K | 76.11 | 36.88 |
| 128K | 72.82 | 35.68 |
从 32K 到 128K 整体衰减不算夸张,RULER 掉了 5.5 个点,LongBench 几乎没掉。说明这个方法的可扩展性确实在线。32K 是峰值这件事我觉得很正常——目标窗口越长,gap 越大,平滑外推的负担越重,掉一点合理。
4.3 训练数据量
| 训练 token | RULER 平均 | LongBench 平均 |
|---|---|---|
| 0.5B | 74.72 | 37.85 |
| 1.0B(默认) | 76.03 | 38.30 |
| 2.0B | 75.61 | 37.86 |
1B token 基本就够了,2B 也没显著提升。这反而是个好消息——数据预算可控。
4.4 跟 PoSE 兼容性
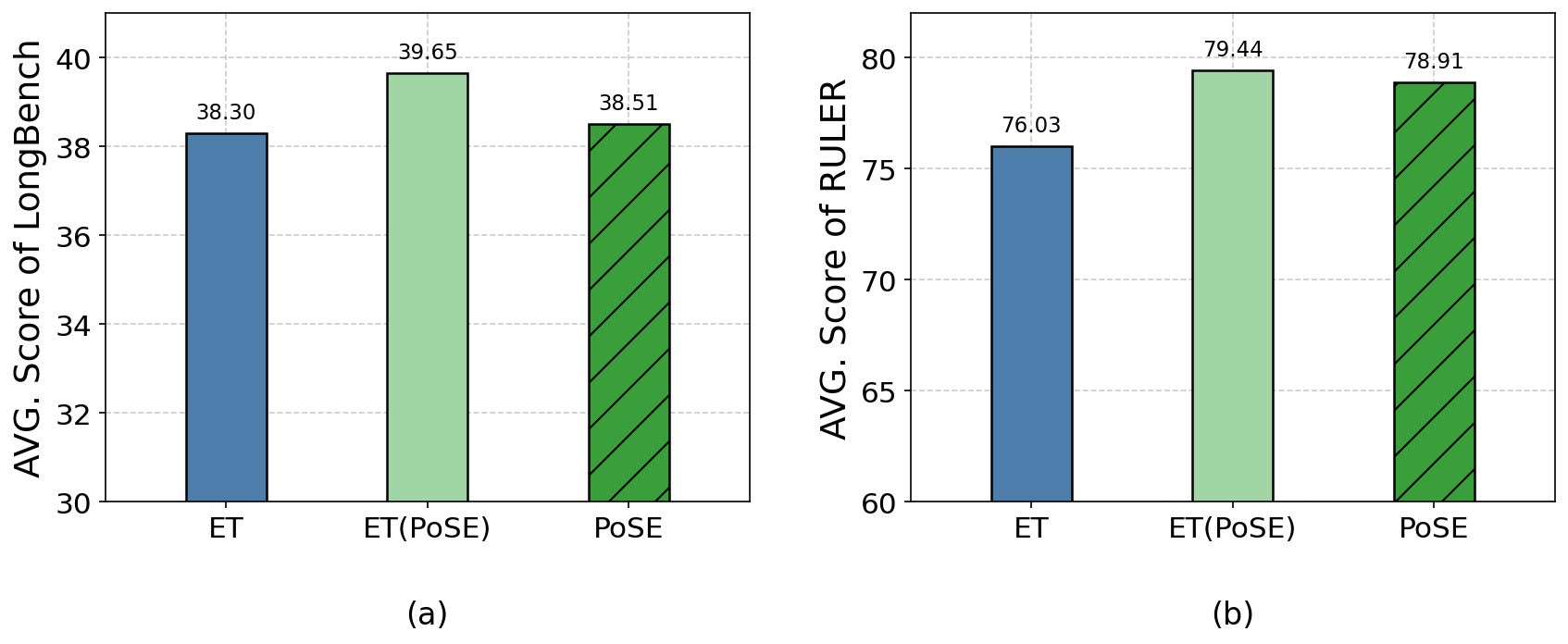
图4:ET 单跑、PoSE 单跑、以及 ET(PoSE) 混合三种配置的对比。混合版本在两个 benchmark 上都拿到最高分(LongBench 39.65,RULER 79.44)。说明 ET 的"终端锚定"思路和 PoSE 的"chunk 模拟"思路并不冲突,可以叠用。
这是个挺漂亮的发现——ET 和 PoSE 不是替代关系,是叠加关系。你完全可以在 ET 的框架里再叠 PoSE 的 chunk 策略,拿到最佳效果。
4.5 短文本能力会不会被搞坏
扩上下文经常会带来一个副作用:模型变成长文本专家,短文本能力下滑。作者在 GSM8K / HumanEval / MMLU / HellaSwag 上跑了一遍,做了 SFT 恢复:
| 方法 | MMLU | GSM8K | HellaSwag | HumanEval | 平均 |
|---|---|---|---|---|---|
| sft_ET(PoSE) | 56.87 | 46.10 | 78.34 | 32.93 | 53.56 |
| sft_ET | 56.67 | 44.66 | 77.51 | 30.83 | 52.41 |
| sft_PoSE | 56.62 | 43.59 | 77.95 | 31.10 | 52.32 |
| sft_LCEG | 54.76 | 42.23 | 77.56 | 24.39 | 49.74 |
| sft_Full FT | 55.40 | 42.15 | 77.11 | 29.27 | 50.98 |
| sft_LongLoRA | 55.07 | 38.82 | 77.49 | 23.17 | 48.64 |
ET 系列在 SFT 恢复后短文本能力反而最强。作者的解释是:PoSE 切碎了真实训练数据破坏语义连续性,而 ET 只切 end prompt(end prompt 本来就是"假的",切不切都没语义代价)——所以 ET 训出来的模型保留了更好的短文本基础能力。
这个论点站得住。
五、我的几点判断
5.1 真正的贡献是什么
聊到这儿,我想把这篇论文的贡献剥几层皮看清楚。
第一层(表面):又一个长上下文扩展的新方法,效果比 baseline 好。
第二层(机制):提出"位置索引解耦"这件事——物理顺序和位置编号可以分开。这个想法 PoSE 其实已经有了,但 PoSE 是"对内容切块",ET 是"对 prompt 切块",差别在于对原始数据的破坏程度。
第三层(最值钱的):提出"长上下文能力可以从稀疏位置监督诱导出来,而不需要密集长序列训练"这个命题。这是真正动摇了行业默认假设的洞见。
这个洞见如果在更多模型、更多任务上被验证,会改变长窗口扩展的工程思路——人们会从"如何把长序列训得便宜"转向"如何设计有信息量的位置监督"。
5.2 我的几个担心
实事求是地说,几个地方我没完全被说服:
担心一:理论部分有些松。Bernstein 不等式 + RoPE 频谱平滑性给了"导数有界"的结论,但从"导数有界"到"gap 上的具体精度可以保证"之间还有距离。论文没给具体的泛化误差 bound,更多是定性论证。说实话这种"光滑性约束 → 自然外推"的论证我之前在好几篇位置编码论文里见过,每次都觉得"挺有道理但又不完全严格"。
担心二:极端长上下文的天花板。128K 上 RULER 掉到 72.82,已经能看出明显衰减。如果扩到 256K、1M,gap 区域可能撑不住。论文没探到这个极限。
担心三:LongBench 主表 baselines 的数据。我盯了一下 LCEG / LongLoRA / Full FT 在 LongBench 主表上的得分,它们之间差异规律比较一致(比如 ET 在每个子任务上恰好比 baseline 高几个点的常数),让我有点怀疑这些 baseline 是不是按一组比较保守的设置跑出来的。这块原文没贴 baseline 的复现细节,需要等代码放出来核对。
担心四:end prompt 的"通用性"还是依赖底座模型。LLaMA-2 7B 上效果显著掉,说明 end prompt 这个稀疏锚点能不能 work,多少还是看底座原本的位置外推性质。论文把锅甩给"预训练质量"了,但严格说应该再多分析几种类型的底座。
5.3 对工程的启发
如果你也在做长上下文相关的事,这套思路有几个直接可用的点:
1. 短训练 + 位置抬高这套机制非常便宜。代码改动也很小——你只需要在数据 collator 里给末尾几个 token 重新分配位置编号,模型代码本身完全不动。即使你不全盘用 ET,把它作为"廉价 warmup"再接全长度微调可能也挺香。
2. end prompt 不挑。三种 prompt 几乎打平,你可以直接用模型原生的 EOS / <|eot_id|> 类似 token,不用专门设计。
3. PoSE 可叠加。如果你已经在用 PoSE,可以把 ET 叠上去,论文显示 RUBLER 还能再涨 3 个点。
4. SFT 恢复短文本能力是必做项。任何扩窗方法都会伤短文本,跑一遍 SFT 恢复一下,ET 的恢复表现最好。
六、收尾
回到开头那个问题——"扩 64K 上下文非得用 64K 长序列训吗?"
EndPrompt 给的答案是:不需要。一个原文本 + 一个被贴到末端的小尾巴就够了。
这个答案最让我喜欢的地方在于——它不是靠堆 trick、堆算力、堆数据来取胜的;它是靠重新理解 RoPE 下"相对位置距离"这件事到底是什么来取胜的。物理序列的长度从来不是必要的,必要的是模型能不能在参数空间里看到正确的位置监督。
当然,这不是终局方案。128K 衰减问题还在,base model 依赖还在,理论严格性还差点意思。但作为一个降低长上下文扩展门槛的工程范式,它已经足够好了。
我现在的预期是——半年内会有跟进的工作把"终端锚定"这个思路推到更长(512K / 1M),或者跟 streaming / hierarchical 长上下文架构结合。Dawei Yin 那个团队搞这种偏工程实用的长上下文工作向来扎实,值得持续关注。
如果你正在头疼 64K / 128K 扩窗的成本——这篇 paper 值得花一晚上跟着代码复现一遍。投入产出比是真的高。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新AI前沿,关注我。