三个推理模型轮流接力解一道题,蒸出来的学生反超老师
核心摘要
蒸馏 Long-CoT 推理这件事,过去一年的主流玩法基本都是 S1、LIMO 那一套——多个教师各自把完整推理写完,再用某个评分器从里面挑一条最好的,扔给学生学。问题很直接:教师之间彼此根本不通气,几条轨迹里 90% 的 token 都被丢掉了,丢的还都是真金白银的 GPU 时间。来自 KAIST 和 UNIST 的这篇 ACL 2026 Findings 提出 CoRD,把整件事的范式翻了过来——别让教师各写各的,让它们一步一步接力,每写完一步用预测困惑度打个分,配合束搜索保留 top-B 条轨迹继续走。结果是:异构三教师(R1-Qwen-32B、QwQ-32B、Phi4-Reasoning-Plus)协作蒸馏出来的 R1-Qwen-32B 学生,在 AIME24 上拿到 79.6 分,在 AIME25 上 70.2 分,全面反超三位教师里最强的 Phi4-Reasoning-Plus(78.9 和 67.9)。判断在前:思路漂亮、消融做得扎实,但论文里有一个非常显眼的实验结果作者自己也没完全圆回来——Integration 基线的学生准确率直接崩到个位数,这个现象很值得单独聊。
论文信息
- 标题:Distilling Long-CoT Reasoning through Collaborative Step-wise Multi-Teacher Decoding
- 作者:Taewon Yun、Jisu Shin、Jeonghwan Choi、Seunghwan Bang、Hwanjun Song
- 机构:KAIST(1、2、3、5 作者),UNIST(第 4 作者)
- 录用:ACL 2026 Findings (long)
- arXiv:2605.02290
- 代码与数据:https://github.com/DISL-Lab/CoRD
一上来先聊一个老问题:长思维链怎么蒸
你做过推理蒸馏就会知道,这件事的难点其实不在训练,在数据。
DeepSeek-R1 出来之后,大家都在拼命把它的推理能力往小模型里塞。最朴素的做法叫 SFT on rationales,找一批难题,让一个大教师生成完整的长 CoT 答案,然后 fine-tune 一个小学生。S1、LIMO 这些方向上的代表作都是这个套路,区别只是怎么选题、怎么选 trace。
但 Long-CoT 这个东西有几个特点让事情没那么简单。一是轨迹长,AIME 这种题动辄几千 token 的思考过程;二是中间有大量的 "Aha moments"——模型先走错一条路,然后回头自我纠正。这两个特点叠在一起,会让传统的 PRM(过程奖励模型)和 MCTS 全部失灵。
为什么 PRM 失灵?因为 PRM 是按步打分的,如果它过早判定某一步\"质量低\",就会把后面那条会自我纠正的路径直接砍掉。但偏偏长思维链里的精华,恰恰就在\"看似走偏然后绕回来\"的过程中。
为什么 MCTS 失灵?搜索空间太大了。每往前走一步都要 rollout 完整轨迹估值,长 CoT 下这个计算量根本撑不住。
所以 S1 和 LIMO 干脆放弃这种 step-level 的精细化,回退到\"先生成完整轨迹再 post-hoc 选\"的策略。简单粗暴。
但 CoRD 这篇论文指出了一个让人挺不舒服的事实:你用 K 个异构教师,每个生成完整轨迹,最后只挑一条——浪费了 (K-1) 份算力不说,更要命的是,那些被丢掉的轨迹里可能有教师 A 写得好的开头、教师 B 写得好的中段、教师 C 写得好的收尾。这些互补的信号你完全没有利用起来。
这就是 CoRD 想解决的问题。
CoRD 的核心思路:把推理蒸馏当成一次解码
论文里那句最关键的话是这样写的:
与其让多个教师独立生成完整轨迹再 post-hoc 选择,不如把每一步推理当成一个\"token\",把不同教师提出的候选步当成\"解码词表\",用 step-wise auto-regressive decoding 的方式拼出一条最优轨迹。
这个抽象其实非常漂亮。一旦你把多教师协作映射成解码问题,所有解码领域的工具(greedy、beam search、各种打分器)就都能直接复用了。
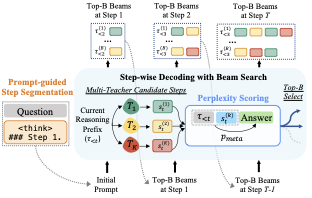
图 1:CoRD 的整体流程。左边是 prompt-guided 步骤切分,每条轨迹用 ### Step 1. ### Step 2. 这样的显式标记切开。中间是核心 step-wise decoding 过程——在第 t 步,每个教师基于当前 prefix τ_<t 提一个候选步 s_t^(k),三个候选合起来形成本步的\"解码词表\"。右边是预测困惑度打分,把候选拼到 prefix 后面,让 meta-prover 看看在这个新 prefix 下生成 ground-truth 答案的概率有多高。结合束搜索保留 top-B 条最优 partial trajectory,继续往下走。
整套机制拆开看有三个核心组件,每个都解决一个具体问题。
组件一:怎么定义\"一步\"——Prompt-guided 步骤切分
这是个不起眼但实际上非常关键的问题。你要让多教师在同一个 step level 上比较,前提是大家对\"一步\"的定义得对齐。
之前主要有两种切法:
- Line-break 切分:按
\n\n这种换行符切。问题是粒度太碎,一步可能只有一句话,没有完整的语义。 - Prefix 切分:识别
WaitHmm这种过渡词作为新步开始。问题是不同 LRM 用这些过渡词的频率差别巨大,QwQ 可能每两步就 Wait 一次,Phi4 可能整段才 Wait 一下,根本没法比。
CoRD 的做法朴素到让人惊讶——在 prompt 里塞一个显式指令:
直接告诉模型用 ### Step N. 这种格式分步。所有教师都用同一个 prompt 起手,输出就被强行对齐到统一的步骤结构。简单粗暴,但很有效。后面消融数据会说明,这一个小改动带来了实打实的提升。
组件二:怎么给一步打分——预测困惑度
这是 CoRD 论文里最有创意的设计。
打分函数 S(·) 要回答一个问题:在第 t 步,三个候选步里哪个最有可能让接下来的推理走向正确答案?
传统做法有几种:PRM 给步骤打质量分、Binary Judgment 让 LLM 二分类判断对错、Random、Max-length 等等。但论文指出这些都有问题——PRM 训练数据稀缺、Binary Judgment 信号太稀疏、其他干脆是 baseline 凑数。
CoRD 引入了一个叫 meta-prover(实验里用的是 QwQ-32B)的额外模型。它不直接给步骤打质量分,而是干这么一件事:
把候选步 s_t^(k) 拼到当前 prefix τ_<t 后面,让 meta-prover 在这个新 prefix 的条件下,计算它生成 ground-truth 答案 A 的概率。这个概率越高,说明加上这一步之后,到达正确答案的路径越\"顺畅\"。
公式上:
其中 A = (a_1, ..., a_M) 是 ground-truth 答案的 token 序列,M 是答案长度,p_meta 是 meta-prover 模型。归一化之后这个分数被压在 [0, 1] 区间。
注意几个关键点:
- 这个打分需要 ground-truth 答案——所以 CoRD 训练数据天然要求带标准答案。这是它的局限,也是它能 work 的关键。
- 因为有了 ground-truth 这根\"锚\",meta-prover 不需要自己有完美的判断力,它只需要会算条件概率。这比训练一个好的 PRM 容易多了。
- 这个设计其实是把\"评估某一步好不好\"转化成\"评估这一步让答案更接近还是更远\",逻辑上比 PRM 更直接。
组件三:怎么不被局部最优困住——束搜索
如果每一步都贪心选当前最高分的候选,问题来了:长 CoT 推理里经常有那种\"先走一段看起来不太对的路,然后突然 Aha 一下绕回来\"的情况。贪心解码会在第一步就把这种路径干掉。
MCTS 能解决这个问题,但前面说过它对长 CoT 算不动。
CoRD 选了一个折中:束搜索。每一步保留 top-B 条 partial trajectory(实验里 B=4),下一步每条 partial trajectory 都用 K 个教师扩展,总共 B×K 个候选,然后取 top-B 继续。
整个流程的复杂度是 O(T·K·M·B),T 是步数,K 是教师数,M 是 meta-prover 单次评估开销,B 是束宽。论文里跟 MCTS 比,CoRD 大约只用了 49% 的 wall-clock time,跟 Curation 比开销稍高但产出的推理质量碾压。
实验:先看数据质量,再看学生表现
CoRD 的实验设计有一个值得点赞的地方——它把\"生成的推理数据质量\"和\"蒸馏后学生模型表现\"分开评估了。这两个虽然相关,但绝不是同一回事。
推理数据质量对比
教师配置分两种:
- 同构(Homogeneous):三个 teacher 都是 QwQ-32B,靠 temperature 0.5/0.6/0.7 拉差异
- 异构(Heterogeneous):三个完全不同的模型——R1-Qwen-32B、QwQ-32B、Phi4-Reasoning-Plus
数据质量看两个指标:答案准确率(Answer Acc.)和预测困惑度(Predictive Perplexity, PP,越高越好)。
| 教师配置 | 蒸馏管线 | Answer Acc. | Pred. Perplexity |
|---|---|---|---|
| 同构 | Curation | 77.4 | 0.664 |
| 同构 | Integration | 88.6 | 0.215 |
| 同构 | CoRD | 90.0 | 0.726 |
| 异构 | Curation | 84.8 | 0.652 |
| 异构 | Integration | 91.2 | 0.223 |
| 异构 | CoRD | 93.1 | 0.774 |
几个非常值得拆开看的现象:
第一,CoRD 在两种配置下都拿了双料第一。异构配置下 CoRD 的 Answer Acc. 比 Curation 高了 8.3 个点(93.1 对 84.8),比 Integration 高 1.9 个点。
第二,Integration 这个基线非常诡异。它是用 GPT-5-mini 把三个教师的完整轨迹\"融合\"成一条,准确率拉到了 91.2——比 Curation 高很多。但它的预测困惑度只有 0.223,是 CoRD 的不到三分之一。
这个数据很反直觉。准确率高但预测困惑度低,到底说明了什么?答案在下一张表里。
学生模型表现:Integration 的崩盘
| 蒸馏管线 | AIME24 7B | 14B | 32B | AIME25 7B | 14B | 32B |
|---|---|---|---|---|---|---|
| 无蒸馏 | 51.3 | 68.1 | 71.6 | 37.5 | 50.6 | 53.8 |
| Curation-Homo | 55.8 | 72.5 | 74.2 | 40.2 | 54.7 | 62.7 |
| Integration-Homo | 7.9 | 7.1 | 11.9 | 5.4 | 6.3 | 6.9 |
| CoRD-Homo | 58.5 | 73.7 | 75.8 | 42.9 | 59.3 | 64.4 |
| Curation-Hetero | 56.6 | 68.1 | 75.0 | 42.1 | 54.6 | 62.1 |
| Integration-Hetero | 8.3 | 7.5 | 12.7 | 3.8 | 4.0 | 9.0 |
| CoRD-Hetero | 60.8 | 74.8 | 79.6 | 45.6 | 62.3 | 70.2 |
教师模型在 AIME24 / AIME25 上的表现:R1-Qwen-32B 71.6 / 53.8,QwQ-32B 77.9 / 66.7,Phi4-Reasoning-Plus 78.9 / 67.9。
我看到这张表的第一反应是\"等一下\"。
Integration 的学生准确率只有个位数到十几位数?比不蒸馏(51.3 / 37.5)还差了 5 倍以上?这个数字摆在那里像是一个 bug,但作者明显是认真的。
论文给的解释是:Integration 用 GPT-5-mini 做事后融合,会把多条 Long-CoT 压缩成更短的总结型 CoT,丢失了大量\"中间反思和自我纠正\"的细节,导致预测困惑度极低(0.215)。学生学到的不是怎么推理,而是怎么给出最终答案——长度不够、深度不够、模式不对。
这个解释其实挺关键。它说明了一件事:Long-CoT 蒸馏的核心信号不在最终答案,而在中间那一长串的思考过程。Integration 把思考过程压扁了,准确率上去了,但拿来训学生反而是毒药。
第二个有意思的点:32B 学生反超教师。CoRD-Hetero 训练的 R1-Qwen-32B 学生在 AIME24 拿 79.6,AIME25 拿 70.2,全面高于三位教师里最强的 Phi4-Reasoning-Plus(78.9 / 67.9)。
说实话,我看到 70.2 这个数的时候愣了一下。学生超教师在蒸馏里并不算罕见(数据筛选+ensemble 的双重作用),但 CoRD 这里超得不算夸张但很扎实——这其实更值得相信,比那种动辄超教师 10 个点的结果靠谱多了。
三个组件的消融:到底哪一块最关键
CoRD 三个核心组件——步骤切分、打分准则、解码策略——论文都做了消融。一项一项看。
步骤切分的影响
| 切分方式 | Acc. | PP. | AIME24 | AIME25 |
|---|---|---|---|---|
| Line-break | 88.4 | 0.734 | 76.7 | 67.7 |
| Prefix | 91.3 | 0.747 | 77.1 | 67.3 |
| Prompt-guide | 93.1 | 0.774 | 79.6 | 70.2 |
Prompt-guide 在所有指标上都赢。Line-break 太碎、Prefix 不一致,二者都比不过显式 ### Step N. 标记。这个增益看着不大(2-3 个点),但 AIME 这种榜单上 2-3 个点就是天壤之别。
更有意思的是这张图——它解释了为什么 Prompt-guide 能赢。
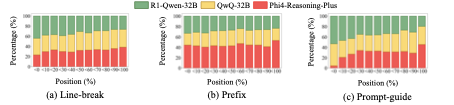
图 2:三种切分方式下,每个教师在不同推理进度位置上被选中的比例。横轴是推理进度(0% 到 100% 的归一化位置),纵轴是各教师被选中的占比。a 是 Line-break,b 是 Prefix,c 是 Prompt-guide。可以看到 Prompt-guide 下三个教师的角色分工最清晰——QwQ 和 R1-Qwen 主导早期(问题分析),Phi4-Reasoning-Plus 在末尾(结论综合)的占比明显上升。前两种切分方式下三个教师的占比一直比较均匀,说明并没有形成有效的\"分工协作\"。
这张图传递的核心信息是:好的步骤切分能让异构教师自动浮现专业化分工。Phi4 擅长收尾,CoRD 的打分机制就会在末尾倾向于选 Phi4 的候选;R1-Qwen 和 QwQ 擅长开头的问题分解,前期就更多被选中。这种 emergent specialization 是 CoRD 协作机制的核心价值。
打分准则的影响
| 选择方法 | Acc. | PP. | AIME24 | AIME25 |
|---|---|---|---|---|
| Random Selection | 80.4 | 0.494 | 69.0 | 61.9 |
| Max-length Selection | 80.0 | 0.502 | 68.8 | 59.0 |
| PRMs | 82.6 | 0.591 | 75.0 | 64.6 |
| Binary Judgment | 91.7 | 0.626 | 77.7 | 66.3 |
| Predictive Perplexity | 93.1 | 0.774 | 79.6 | 70.2 |
Predictive Perplexity 在所有维度全面领先。PRM 表现比 Binary Judgment 还差,作者解释是 PRM 会过早干掉那些后来能自我纠正的轨迹——这跟前面说的\"长 CoT 蒸馏不能太早砍路径\"完美呼应。
Binary Judgment 是个有意思的对照——它的做法是让 LLM 当裁判,0/1 给答案。Acc. 上比 PP 只低 1.4 个点,但学生蒸馏分差了 2-4 个点。说明连续打分比离散打分更适合做蒸馏数据筛选,因为它能捕捉细微的质量差异。
解码策略的影响
| 解码 | Acc. | PP. | AIME24 | AIME25 |
|---|---|---|---|---|
| Greedy | 81.6 | 0.719 | 76.7 | 66.5 |
| MCTS | 89.6 | 0.755 | 75.8 | 66.3 |
| Beam Search | 93.1 | 0.774 | 79.6 | 70.2 |
这个对比挺有说服力。MCTS 看似强大,但在长 CoT 上反而比 beam search 差——而且差得不只是计算开销,连推理质量都差了 3.5 个点。
论文给的解释:MCTS 给的是 trajectory-level reward(要 rollout 完整轨迹才能算),这种粗粒度信号会让搜索 bias 向\"整体看起来更稳的教师\",弱化每一步的互补性。Beam Search 因为每步都做选择,能更精细地利用 step-level 的互补信号。
这个论点配合上面那张教师命中率图基本能闭环——MCTS 下教师分工不清晰,Beam Search 下分工才能浮现。
泛化能力:换数据集还行不行
光在 LIMO-v1 + AIME 上 work 不够说服力。论文做了三个方向的泛化测试。
换数据集
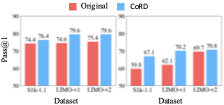
图 3:在三个不同的基础数据集(S1k-1.1 1000 题、LIMO-v1 817 题、LIMO-v2 800 题)上,用 CoRD 重新生成推理数据后训练同一个学生(R1-Qwen-32B),与原始 curated 数据集训练结果对比。左图 AIME24,右图 AIME25。CoRD(蓝色)在所有六个对比里都赢,AIME25 上的提升尤其明显——LIMO-v2 上从 67.1 提到 76.2,提了 9.1 个点。
这张图的信息量很大。它说明 CoRD 不是某个特定题集上的 overfitting,而是一种通用的数据生成 pipeline——只要给问题和参考答案,就能把任意 curated 数据集的质量再提一截。
跨域和开放式任务
| 蒸馏管线 | MATH500 | TaTQA | PubMedQA |
|---|---|---|---|
| 无蒸馏 | 92.1 | 87.3 | 86.0 |
| Curation-Homo | 93.5 | 80.5 | 86.1 |
| Integration-Homo | 74.1 | 73.3 | 84.0 |
| CoRD-Homo | 93.9 | 90.0 | 90.6 |
| Curation-Hetero | 93.4 | 88.2 | 88.4 |
| Integration-Hetero | 72.3 | 73.1 | 83.0 |
| CoRD-Hetero | 94.8 | 95.2 | 91.8 |
MATH500 in-domain 提升不大(baseline 已经 92.1 了,天花板效应)。TaTQA 是表格推理,out-of-domain,CoRD-Hetero 拉到 95.2,比 baseline 高了将近 8 个点——这个跨域迁移挺扎实。
PubMedQA 是开放式医学问答,答案是 free-form 长文本。这里 CoRD 把它当成有\"参考答案\"的任务来处理——用单个 reference answer 算 predictive perplexity。CoRD-Hetero 拿 91.8,比 baseline 高 5.8 个点。
这里有个点要提一下。CoRD 在底层依赖 ground-truth answer 算 predictive perplexity,所以它的应用场景被限定在\"至少有一个参考答案\"的任务上。完全开放、无标准答案的任务(比如开放式写作)它就不太能直接用了。这是它的硬约束,论文里也坦诚承认。
教师命中率分析:协作到底长什么样
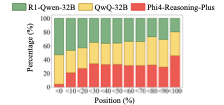
图 4:CoRD 异构配置下,三位教师在归一化推理进度(0-100%)的各阶段被选中的比例。早期(≤40%,对应问题理解和约束分析阶段)R1-Qwen-32B 和 QwQ-32B 是主力;后期(≥80%,对应结论综合阶段)Phi4-Reasoning-Plus 占比明显上升。这种分工不是人为指定的,而是 predictive perplexity 在每一步打分后自然涌现的结果。
我觉得这张图是整篇论文最值钱的一张。
它直观地告诉你:异构多教师协作不是\"民主投票\",而是\"按擅长领域分工\"。Phi4-Reasoning-Plus 之所以在结论阶段更多被选中,不是因为它整体最强,而是因为它在那个阶段的候选步对\"接下来生成正确答案\"贡献最大。
这种分工模式说明了 CoRD 比 Curation 强在哪。Curation 是\"选一个整体最好的教师\",而 CoRD 是\"每一步选最适合这一步的教师\"。前者是粗粒度选择,后者是细粒度组合——后者能拼出任何单一教师都拼不出来的最优轨迹。
我的判断:哪里强,哪里弱
强在哪
第一,问题定位准确。把 Long-CoT 蒸馏的核心问题(异构教师协作 + step-level 评估 + 长轨迹搜索)抽象成一个解码问题,整个框架一下子清晰起来。这种\"换视角\"的工作有时候比新算法更值钱。
第二,实验做得很全。教师配置(同构/异构)、数据集(LIMO/S1/in-domain/out-of-domain/open-ended)、组件消融(切分/打分/搜索)、效率对比(vs Curation/vs MCTS)都覆盖了。学生模型还测了 7B/14B/32B 三档,趋势一致。这种工作量在 ACL Findings 里属于头部。
第三,predictive perplexity 这个设计是真的巧。它绕开了\"需要训好的 PRM\"这个大麻烦,转而用任何强 LRM 都能直接当 meta-prover——只要它能算条件概率就行。门槛降了一大截。
弱在哪
第一,依赖 ground-truth answer。这个约束论文承认了,但还是会限制 CoRD 的应用场景。完全开放式任务(创意写作、对话)它就用不了。
第二,meta-prover 用 QwQ-32B 这件事有点循环。QwQ-32B 既是教师之一,又是 meta-prover。虽然附录里报告了换其他 meta-prover 的结果,但主表用最强教师当 meta-prover 这个设置多少有点优势倾斜——meta-prover 自己的候选步会不会被它自己更倾向地打高分?论文里没看到针对这一点的严格控制实验。
第三,Integration 基线崩盘的解释还可以更深。\"GPT-5-mini 把 Long-CoT 压成了 Short-CoT\"这个说法直觉上能讲通,但 91.2 的高准确率和 7-9 分的学生表现之间这么大的反差,我个人觉得作者应该再多挖一层——比如对比 Integration 输出和 CoRD 输出的实际 token 长度分布、推理结构差异。现在的解释偏定性。
第四,束宽 B=4 是怎么定的没特别多讨论。是不是 B=8 会更好?计算开销和质量的 trade-off 曲线在哪?论文里没看到完整扫描。
工程上的启发
如果你也在做推理蒸馏,CoRD 这套思路其实可以拆解使用:
- 不一定要异构多教师。同构多 temperature 一样能用(论文里 Homo 配置 CoRD 也比 Curation 强)。
- 不一定要束搜索。如果算力紧张,greedy + 多 teacher + predictive perplexity 也能拿到不错的效果(Greedy 在 AIME24 上 76.7,已经超过单教师 Curation)。
- predictive perplexity 这个评估方式可以独立用。哪怕你不做协作解码,光用它来给 Curation 选 trace 也比传统的答案匹配更准。
我自己的判断是,CoRD 这一类\"step-level 多教师协作 + 用条件答案概率打分\"的范式,会在未来一两年的推理蒸馏方向里成为标配。简单、有效、门槛不高,工程上完全可以复现。
收尾
CoRD 这篇论文好就好在它没有发明什么花哨的新算法——束搜索是几十年前的东西,预测困惑度其实就是 perplexity 的一个变体。但它把这些老东西组合到一个新位置上,解决了一个真实存在的问题。
ACL Findings 录得不冤。
跑一句不那么客观的判断:未来一年里,做推理蒸馏的人不去试一下 CoRD 这套思路是亏的。代码和数据都开源了,门槛不高,照着论文复现一遍学到的东西比啃十篇综述都多。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新 AI 前沿,关注我