答对了题,却抄错了出处——CiteVQA 把多模态大模型的"归因幻觉"摆上了台面
一个让人后背发凉的小场景
先讲个事。
假设你在一家律所做合规,手里是一份 80 多页的招股说明书。你把它丢给一个挺能打的多模态大模型,问:"这家公司去年的营收增长是多少?"模型秒回:"23.5%。来源见第 42 页第三段。"
你松了口气,顺手翻到第 42 页验一下——结果那一段在讲员工福利。再翻到第 11 页,才找到真正的财报数字。
答案是对的,引用却是错的。
放在闲聊里,这只是个笑话;放在法律、金融、医疗这种"每句话都要溯源"的场景里,这就是事故。比"答错"还危险,因为它穿着"我有依据"的外套,骗过了你的第二次检查。
CiteVQA 这篇论文,干的就是把这件事按到桌面上,逼着评测体系正视它——他们给它起了个名字,叫归因幻觉(Attribution Hallucination)。
核心摘要
CiteVQA 是一个面向"可信文档智能"的新基准,针对的是目前 Doc-VQA 评测的一个老毛病:只看答案对不对,不看证据指得准不准。作者构建了 1897 道题、711 份 PDF、平均 40.6 页、跨 7 个领域和中英双语的数据集,要求模型在回答问题的同时给出元素级的 bounding box 引用,并提出 SAA(Strict Attributed Accuracy)作为核心指标——答案和证据必须同时对,才算这道题做对了。
对 20 个主流多模态大模型审了一遍,结果挺刺眼:最强的 Gemini-3.1-Pro-Preview 的 SAA 只有 76.0,最强的开源 MLLM(Qwen3-VL-235B)只有 22.5。GPT-5.4 答案准确率 87.1,但 SAA 直接掉到 59.0——27 个点的鸿沟,就是归因幻觉的代价。
我的判断:这是一个迟到但必要的工作。它没在模型方法上"创新",而是在评测维度上戳了一刀很关键的洞——这一刀的价值,可能比再训一个 SOTA 还要大。
论文信息
- 标题:CiteVQA: Benchmarking Evidence Attribution for Trustworthy Document Intelligence
- 作者:Dongsheng Ma, Jiayu Li, Zhengren Wang, Yijie Wang, Jiahao Kong, Weijun Zeng, Jutao Xiao, Jie Yang, Wentao Zhang, Bin Wang, Conghui He
- 提交时间:2026 年 5 月 13 日
- arXiv:https://arxiv.org/abs/2605.12882
- 代码与数据:https://github.com/opendatalab/CiteVQA
为什么这事值得专门做一个 benchmark
先说一个我自己工程里栽过的跟头。
之前做过一个企业级的文档问答系统,针对的就是那种几十上百页的合同 + 财报混合 PDF。上线之前我们用 DocVQA、MP-DocVQA 这些公开榜的指标自测,分数都挺漂亮的。结果上线两周,业务那边反馈说"模型回答看着对,但引用的页码经常翻过去对不上"。
我当时第一反应是 RAG 召回器的问题,去查检索链路,没毛病。后来才意识到一件事:现有评测里压根没人管"引用得准不准"。所有公开榜的评分逻辑都是——把模型答案和标准答案做语义对齐,对得上就给分。至于模型回答时说的"我看了第几页第几段",没人去校验。
这就是 CiteVQA 想堵的那个洞。
来看一下他们整理的对比表,把现有的几个主流 Doc-VQA 基准放在一起,归因粒度的差距一目了然:
| 基准 | 文档数 | 平均页数 | 证据粒度 | 是否联合评分 |
|---|---|---|---|---|
| DocVQA | 12,767 | 1.0 | 页 | 否 |
| InfoVQA | 5,485 | 1.0 | 页 | 否 |
| MP-DocVQA | 6,000 | 8.3 | 页 | 否 |
| MMLongBench-Doc | 135 | 47.5 | 页 | 否 |
| SlideVQA | 2,619 | 20.0 | bbox | 否 |
| ViDoRe V3 | 190 | 137.0 | bbox | 否 |
| CiteVQA | 711 | 40.6 | 元素级 | 是 |
注意最后两列。在 CiteVQA 之前,要么没有 bbox 标注,要么有但粒度停在页级,再要么有 bbox 但答案和证据是分开评分的——也就是说,你可以拿一个答案对但证据全错的预测,照样得高分。这种"分而治之"的评分方式,恰恰让归因幻觉藏得严严实实。
CiteVQA 把粒度推到了元素级——一个表格单元、一个段落、一张图,都有独立的 bbox。然后用一个统一的指标 SAA 把答案和证据捆在一起评:你必须同时对,才算这一题做对。
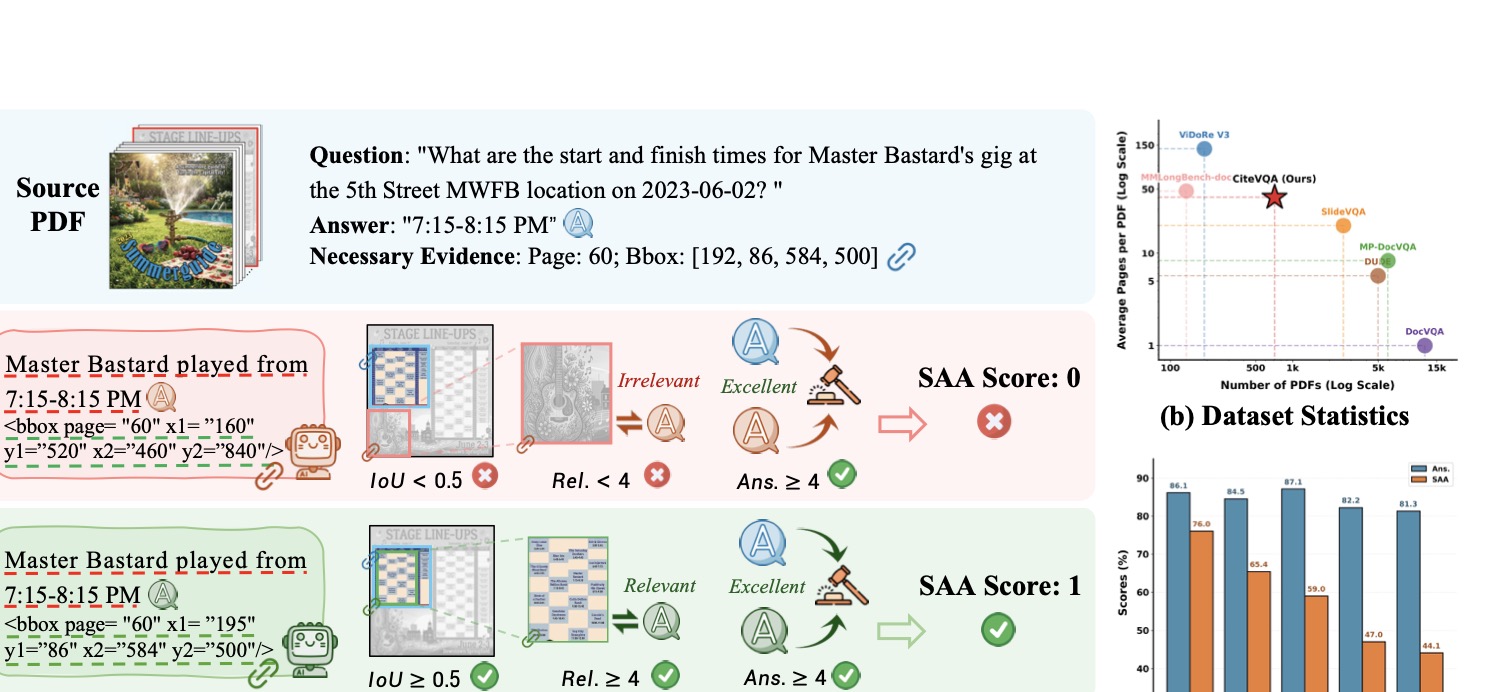 图1:CiteVQA 任务概览。(a) 一个示例任务:模型必须同时给出正确答案和精确的证据引用,才能拿到 SAA 分;(b) 数据集规模 vs 平均页数对比,CiteVQA 在文档量和页数之间做了平衡;(c) 各家 MLLM 的答案准确率和 SAA 之间普遍存在巨大差距——这就是归因幻觉。
图1:CiteVQA 任务概览。(a) 一个示例任务:模型必须同时给出正确答案和精确的证据引用,才能拿到 SAA 分;(b) 数据集规模 vs 平均页数对比,CiteVQA 在文档量和页数之间做了平衡;(c) 各家 MLLM 的答案准确率和 SAA 之间普遍存在巨大差距——这就是归因幻觉。
数据集是怎么造出来的——一条不靠人肉的流水线
到这里你可能要问:1897 道题、711 份多页 PDF、元素级 bbox 标注——这套数据是怎么标出来的?纯人工的话,按以往经验,光这个量级的精标,至少几十人月。
CiteVQA 作者的做法是把整条标注链路自动化,只在关键节点做人工校验。整个 pipeline 分几个阶段,逻辑挺清晰的:
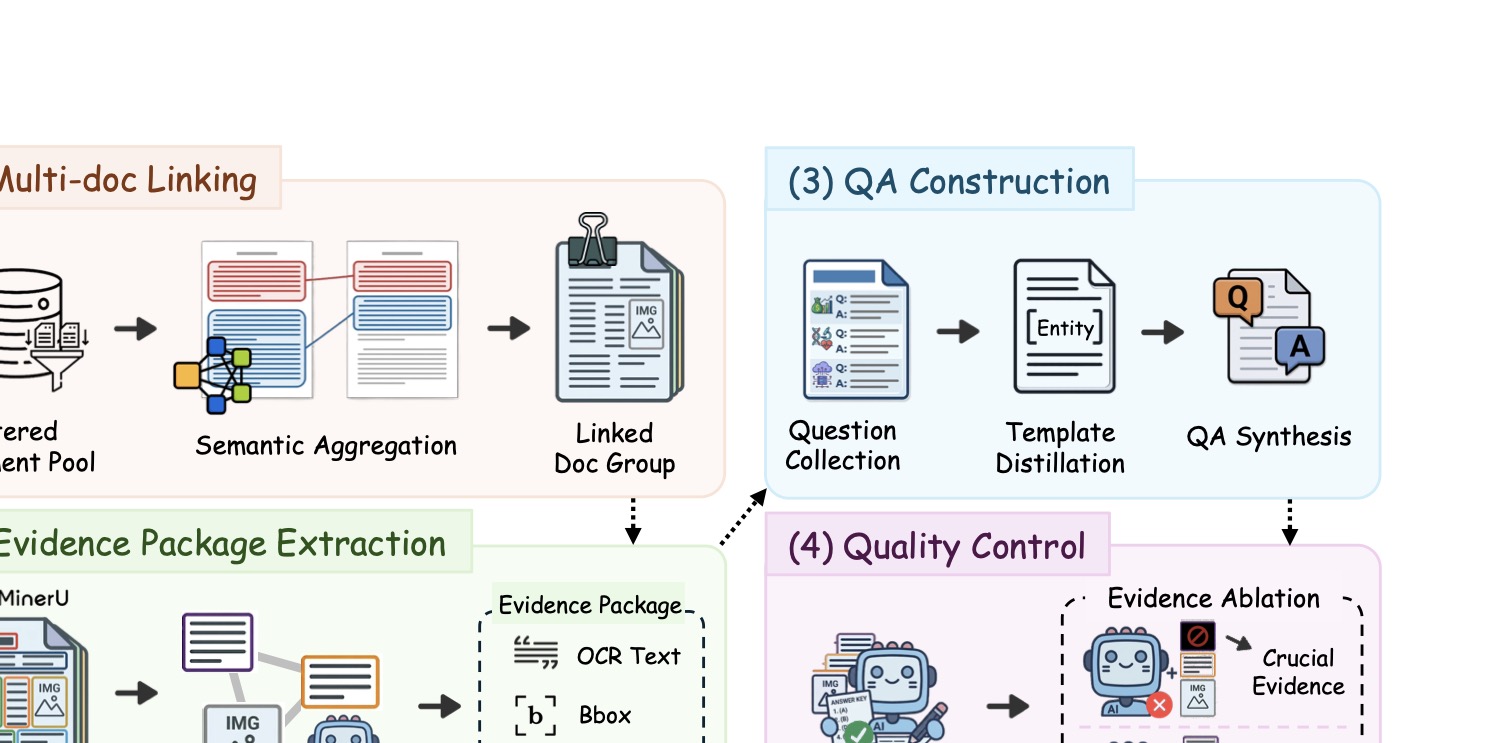 图2:CiteVQA 的自动化标注流水线。从多文档语义关联开始,经过证据包提取、模板蒸馏式 QA 合成,最后做基于 mask 消融的关键证据识别。整条链路尽量靠 MLLM 自动跑,关键节点配人工抽检。
图2:CiteVQA 的自动化标注流水线。从多文档语义关联开始,经过证据包提取、模板蒸馏式 QA 合成,最后做基于 mask 消融的关键证据识别。整条链路尽量靠 MLLM 自动跑,关键节点配人工抽检。
第一步:从 1 亿份 PDF 里挑出 711 份
源数据来自 Common Crawl,作者从 1 亿份原始 PDF 里分层采样出 25 万份候选,再用 MLLM 做两阶段标注——先粗分到领域和语言,再细分到子类。最后从 25 万份里筛出 711 份,覆盖 7 大领域、30 个子类,中英双语,平均 40.6 页。
为什么不直接用更小的样本?因为他们要保证领域分布平衡——金融、法律、医疗、学术、政府公报、商业报告、教材等都要有。这个平衡靠抽样不容易做出来,必须先打标签再分层挑。
第二步:多文档关联 + 证据包提取
这一步挺有意思。真实场景里,一个问题往往要跨多份文档拿证据——比如"对比 A 公司 2023 和 B 公司 2023 的研发投入占比",得跨两份年报。
作者用 dense retrieval 找候选相关文档对,再用 LLM 做章节级元数据对齐,把孤立的 PDF 串成"语义关联组"。如果实在串不起来,就保留为单文档。
证据提取阶段,他们用 MinerU2.5 做深度文档解析,拿到每个元素的 bbox、OCR 内容、页码。然后让一个 MLLM 当 agent,在解析出来的 bbox 空间里"漫游"——把散落在不同页、不同文档里的相关证据拼成一个证据包(Evidence Package)。
这一步借鉴了 DocDancer 和 WebSailor 的 agentic navigation 思路。说实话,这种"用 MLLM 当 agent 找证据"的做法我以前也试过,弱点很明显——agent 容易漏掉间接相关的证据,导致最终评分时模型如果找到了一个没被标的"补充证据",会被冤枉判错。作者在这里做了一个补救,引入了"crucial evidence vs supplemental evidence"两层标签,后面讲指标的时候会回到这点。
第三步:模板蒸馏式 QA 合成
这一步是我觉得设计上最讨巧的地方。
作者没有让 MLLM 自由发挥编问题(自由生成的问题很容易跑偏,要么太简单要么不符合真实业务),而是先从一堆开源的公开 QA 数据集里收集真实问题,把它们蒸馏成问题模板。生成阶段,MLLM 先根据证据包的特征选最合适的模板,再按模板约束往里填具体内容。
这种"模板 + 填充"的玩法,说到底是用真实业务问题的结构来约束生成,再用 MLLM 来保证内容贴合具体文档。比纯生成稳很多。
第四步:质量控制——可答性 + 关键证据消融
数据造出来不能直接用,得过两道关。
第一道叫可答性验证:把候选 QA 对 + 对应的证据截图喂给一个强 MLLM,只有模型在只看截图的情况下能答对,这道题才保留。这一步实际上是在确认"证据包确实够回答问题"。
第二道叫关键证据识别——这个设计我觉得是整个 pipeline 里最关键的一笔。作者注意到一个问题:一个证据包里可能有 5 个 bbox,但其中只有 2 个是回答问题真正不可或缺的,另外 3 个只是补充信息。如果评分时把 5 个全当成"必须命中",就会误伤模型——模型找到 2 个关键证据本来该满分,结果因为没找到那 3 个补充证据,被扣分。
他们的做法是消融式判定:把证据包里的 bbox 一个一个分别 mask 掉,看模型还能不能答对。如果某个 bbox 被 mask 后模型答错了,那它就是 Crucial Evidence;否则就是补充证据。后续 Recall 指标只在 Crucial Evidence 上算。
这种"用 LLM 自己来定义 ground truth 的关键程度"的思路,是这两年评测设计的一个新趋势。它不完美——比如严重依赖判定模型的能力上限——但比纯人工标注便宜得多,可复现性也更高。
另外作者还做了zero-document self-test:用 Qwen3-VL-235B 在不给任何文档的情况下试着答题,能答出来的题就视为"常识题"扔掉。这一步是为了排除那些模型靠预训练知识就能猜对的伪文档题——挺关键的一步,因为很多公开 Doc-VQA 数据里都掺了这种"伪文档依赖"的题。
指标设计:SAA 是怎么把答案和证据捆在一起的
数据有了,下一个问题是怎么打分。CiteVQA 提出了一套指标,核心是 SAA,配套还有 Recall 和 Relevance。
形式化地说,每个样本是 \((D, Q, A_{gt}, \mathcal{B}_{gt})\),其中 \(\mathcal{B}_{gt}\) 是 ground-truth bbox 集合,进一步分成关键证据 \(\mathcal{B}_{crucial}\) 和补充证据 \(\mathcal{B}_{other}\)。模型输出 \(\hat{Y} = \{(A_1, b_1), \dots, (A_n, b_n)\}\),每个答案片段配一个 bbox。
Recall(召回):以 IoU@0.5 为阈值,衡量预测 bbox 对关键证据的覆盖率:
Relevance(相关性):让 LLM judge 给每对 (答案片段, 引用 bbox) 打 0 到 5 分,衡量"这个 bbox 是不是真的支撑了这一句答案"。
Answer Correctness(答案正确性):让 LLM judge 在 0 到 5 分尺度上判断预测答案是否在语义上匹配 ground truth。
SAA(Strict Attributed Accuracy):样本级二值指标,必须答案对且证据对:
注意 SAA 里证据维度是个"或":要么 Relevance 高(你引用的 bbox 在 LLM 看来确实支撑了答案),要么 Recall 高(你引用的 bbox 在空间上确实覆盖了关键证据)。这是一个挺务实的妥协——模型可能没正好命中标注的那个 bbox(比如标的是整段,模型只引了其中一句),但只要语义上能撑住答案,就给分。
这个 SAA 我看完之后第一反应是有点严但不算苛刻。严的是"答案 + 证据都对"的硬约束,不严的是证据维度给了两个可替代条件。如果两边都用 IoU 卡死,估计前 20 个模型里没几个能上 50 分了。
实验结果:那个 27 分的鸿沟
20 个 MLLM 跑下来的主表数据挺有意思。我把核心几行摘出来:
| 模型 | Rec. | Rel. | Ans. | SAA |
|---|---|---|---|---|
| Gemini-3.1-Pro-Preview | 66.0 | 83.6 | 86.1 | 76.0 |
| Gemini-3-Flash-Preview | 45.4 | 75.7 | 84.5 | 65.4 |
| GPT-5.4 | 31.0 | 67.5 | 87.1 | 59.0 |
| Gemini-2.5-Pro | 27.4 | 59.8 | 82.2 | 47.0 |
| Seed2.0-Pro | 28.5 | 54.9 | 81.3 | 44.1 |
| GPT-5.2 | 18.2 | 56.6 | 71.5 | 33.7 |
| Qwen3-VL-235B-A22B(开源最强) | 11.3 | 35.3 | 72.3 | 22.5 |
| Qwen3-VL-32B | 6.6 | 30.5 | 72.3 | 17.3 |
| Qwen3-VL-8B | 1.0 | 14.7 | 61.2 | 7.5 |
几个观察。
第一,归因幻觉是普遍现象,不是个别模型的问题。
看 GPT-5.4 那一行:答案准确率 87.1,SAA 只有 59.0。中间差了 28 个点——这意味着模型在差不多三分之一的题上"答对了,但引用错了"。Gemini-3-Flash 也类似:Ans. 84.5,SAA 65.4,差 19 个点。哪怕是综合最强的 Gemini-3.1-Pro,Ans. 86.1,SAA 76.0,也差了 10 个点。
这个现象在所有 20 个被测模型里无一例外。模型越强,幻觉的绝对差距越小(10 到 28 个点),但都还在。模型越弱,差距越触目惊心——Qwen3-VL-235B 答案能拿 72.3,SAA 只有 22.5,差了 50 个点。Qwen3-VL-8B 那一行更夸张,Ans. 61.2,SAA 只有 7.5——可以理解为,它几乎完全不知道自己在用哪段证据回答问题。
第二,闭源开源差距是断崖式的。
闭源那一档,最强 Gemini-3.1-Pro 在 76.0,最弱的 Qwen3.6-Plus 也有 17.5。开源那一档,最强 Qwen3-VL-235B 只有 22.5,比闭源最弱的还差。
这个差距比 MMLU、GSM8K 那种主流榜的差距大得多。原因我猜跟训练数据有关——闭源模型显然在"看 PDF + 给出可视化引用"这种任务上有专门的数据训练(特别是 Gemini 系列),而开源 MLLM 的训练数据里这类格式可能不多。
第三,Gemini 比 GPT 强在哪里?
注意一个细节:GPT-5.4 的 Ans. 87.1 是全场最高,但 SAA 只有 59.0,被 Gemini 系列甩开。这说明 GPT-5.4 答题强,但在"准确指出引用 bbox"这件事上不如 Gemini。
我的猜测是 Gemini 在原生 API 层就支持图像区域 bbox 的输出,训练数据里大概率有大量"图像 + bbox 描述"的对齐对,而 GPT 这一代对坐标输出的训练似乎没这么直接。这是个工程细节,但对评测结果影响很大。
进一步分析:归因不是"答完之后补的",可能本身就帮答题
主表之外,作者还做了两个挺值得看的分析。
题型差距:定量推理最容易,多模态解析最难
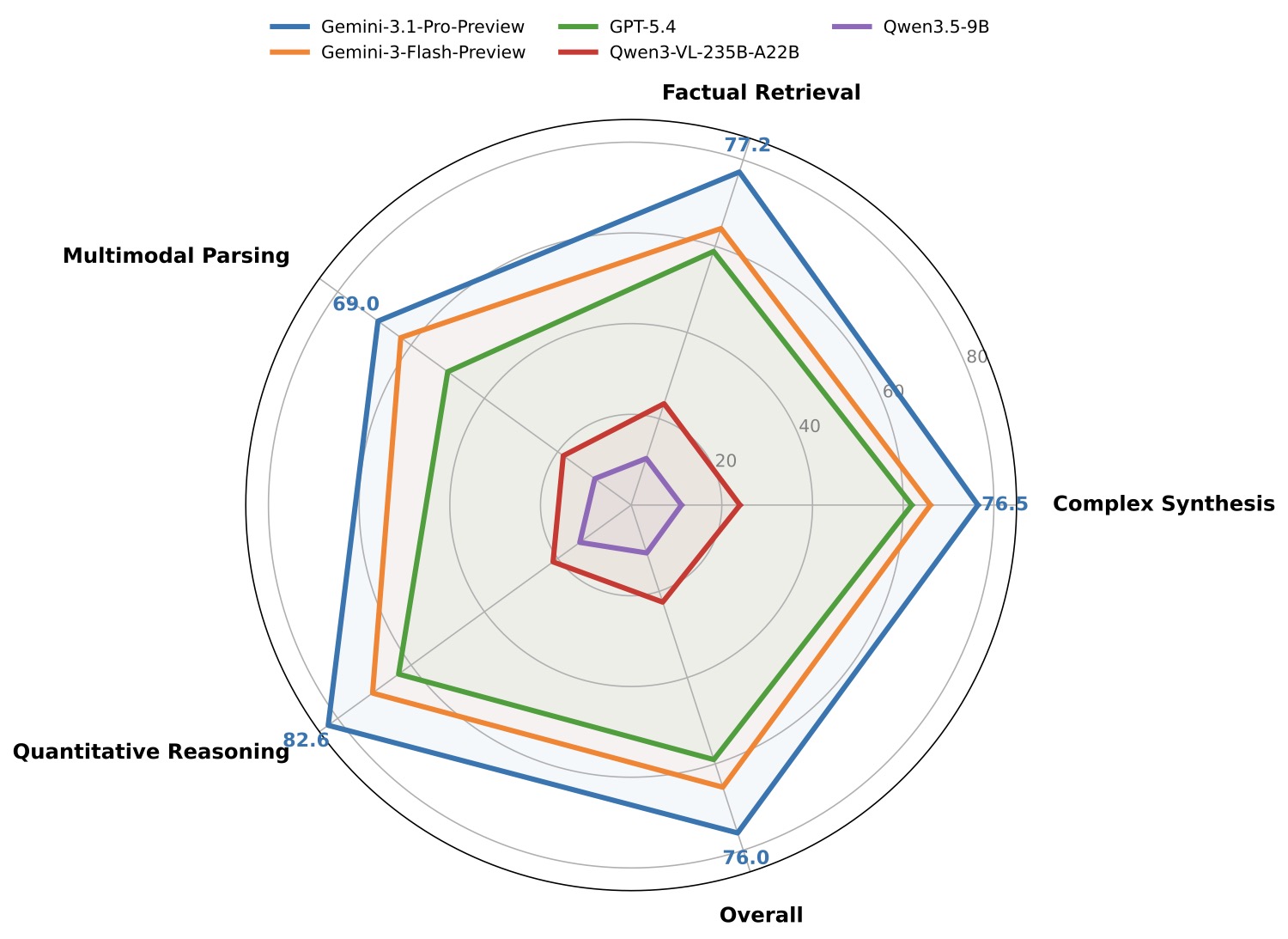 图3:各题型 SAA 雷达图。所有模型在 Quantitative Reasoning(定量推理)上表现最好,在 Multimodal Parsing(多模态解析)上表现最弱。
图3:各题型 SAA 雷达图。所有模型在 Quantitative Reasoning(定量推理)上表现最好,在 Multimodal Parsing(多模态解析)上表现最弱。
定量推理在所有模型上 SAA 都比平均水平高一些(Gemini-3.1-Pro 在这类题上能到 82.6)。原因不难理解:数字计算的逻辑是客观的,证据和答案之间的关联也很明确——你算出 23.5%,那个 23.5 一定来自某张表的某个单元。模型把这个对齐做出来不算特别难。
最难的是新引入的 Multimodal Parsing 任务。这类题大概是这种形式:"找到那张背景是浅蓝色、标题包含'Q3 Revenue'的表格,告诉我第三行第二列的值。" 它考的是先识别目标元素(按视觉描述定位),再解析它的内容。两步都难。我觉得这个题型是整个 benchmark 最有挑战性的部分,也是最贴近真实场景的——业务用户的问题就长这样。
证据质量和答案准确率正相关——可能不只是巧合
这是一个我比较 buy in 的发现。
作者做了一个图:把模型在每道题上的证据质量 \(\max(Rel., Rec.)\) 作为 x 轴,答案准确率作为 y 轴,画散点 + 趋势线。结果是——一旦越过证据质量的低分区(0-30 分),答案准确率随证据质量单调上升。
换个说法:那些证据指得准的题,答案也更准;证据找不到的题,答案大概率也错。
作者把这个观察推到了一个更强的假设:证据归因可能不是答完之后补上的注脚,而是答对问题的功能性前提。再讲清楚一点,模型能在内部"看到"正确证据,是它能给出正确答案的因,不是果。
为了验证这个假设,他们做了一组消融实验:把搜索空间人为缩窄,看模型表现。
| 模型 | 单文档原始 | 限定 GT 页 | 提升 |
|---|---|---|---|
| Qwen3.5-27B | 79.3 | 84.6 | +5.3 |
| Qwen3-VL-32B | 75.3 | 79.9 | +4.6 |
| Qwen3-VL-8B | 67.0 | 71.1 | +4.1 |
| 模型 | 多文档原始 | 提供 1 个 gold 文档 | 提升 |
|---|---|---|---|
| Qwen3.5-27B | 73.1 | 81.6 | +8.5 |
| Qwen3.5-9B | 58.4 | 68.1 | +9.7 |
| Qwen3-VL-8B | 53.3 | 66.7 | +13.4 |
单文档场景下,把搜索范围限定到 ground-truth 页,所有模型答案准确率涨 2 到 5 个点。多文档场景下,只给一个 gold 文档(其他文档去掉),最弱的 Qwen3-VL-8B 涨了 13.4 个点。
这组实验挺打脸"端到端就够了"的论调的。它说明:至少在当前 MLLM 上,"先定位、再回答"的两段式架构,可能比纯端到端更有上限。如果模型能先把证据精准找出来,再做推理,答得对的概率会显著上升。
这给一个工程方向:未来的 Doc-VQA 系统也许不该追求 end-to-end,而是应该把"定位"和"回答"做成两个可解释的阶段。OpenAI o1、Anthropic 的 thinking 模型其实已经在朝这个方向走了——只是它们的中间步骤没有跟 bbox 这种"可视化引用"对齐。
Case Study:一个能看清"归因幻觉"长什么样的例子
光看分数不够直观。作者放了几个对比例子,把幻觉的样子摆出来:
 图4:Qwen3-VL-235B vs Gemini-3.1-Pro 在同一道题上的对比。两个模型都答对了,但 Qwen3-VL-235B 引用的两个 bbox 一个是空白区域、一个是不完整裁剪,SAA=0;Gemini-3.1-Pro 引用虽然第一个有轻微偏移,第二个几乎完美,SAA=1。
图4:Qwen3-VL-235B vs Gemini-3.1-Pro 在同一道题上的对比。两个模型都答对了,但 Qwen3-VL-235B 引用的两个 bbox 一个是空白区域、一个是不完整裁剪,SAA=0;Gemini-3.1-Pro 引用虽然第一个有轻微偏移,第二个几乎完美,SAA=1。
这个图我盯着看了一会儿。Qwen3-VL-235B 那个例子,答案文字部分跟标准答案对得上,但它"声称看的那两块"——一块是页面空白处,一块裁了半个表格——根本撑不起答案。这就是典型的归因幻觉:模型答对了,但它给出的"我是怎么答的"是编的。
放在律所合规的语境里,这种回答就是不能用。审计员翻到那个 bbox 一看就知道这是模型在糊弄事。Gemini-3.1-Pro 的引用就老实多了,虽然第一个 bbox 偏了一点点,但能看出来它确实在试着把答案锚定到某段文字。
 图5:更复杂场景下的对比案例。可以看到不同模型在跨页、跨文档证据定位上的差异。
图5:更复杂场景下的对比案例。可以看到不同模型在跨页、跨文档证据定位上的差异。
我的判断
这篇论文我看完之后,主要有几个判断。
第一,这是一篇评测论文,而不是方法论文,但它的价值不低于一个新方法。
在 MLLM 越跑越快、榜单越刷越满的当下,能戳出"现有评测漏掉了什么"的工作是稀缺的。CiteVQA 这一刀切得很准——它切到了"答案准确率"和"实际可信度"之间的那条裂缝。这条裂缝以前业务侧的人都知道(我自己就吃过亏),但学术圈一直没有一个体面的方式把它量化出来。SAA 这个指标做到了。
第二,pipeline 的设计有不少可借鉴的地方。
特别是"消融式关键证据识别"那一步。以前做评测数据,标证据基本靠人工拉框,主观成分大,也很难判定一个证据是"必要的"还是"补充的"。CiteVQA 用 MLLM 做 mask 消融来自动识别 crucial evidence,思路挺干净,可以迁移到很多其他多步骤推理任务的评测设计里。
第三,潜在的批评点也得说。
一个是判定模型偏置——他们用 Qwen3-VL-235B 做 LLM judge 来评 Relevance 和 Answer,这意味着如果 Qwen 系列对某些回答风格有偏好,可能会系统性影响打分。作者在附录里做了不同 judge 的对比分析,说结果稳定,但我建议读者自己跑跑代码验证。
另一个是 SAA 的阈值选择有点 hack——Ans.≥4 和 Rel.≥4 这两个 4 是怎么定的?为什么不是 3.5 或 4.5?这种二值化阈值很容易引入"门槛附近样本"的不稳定。SAA 在边界样本上的鲁棒性,文章里没有深入讨论。
还有一个是 1897 道题对于 711 份文档来说,平均每份文档不到 3 道题。考虑到他们说要覆盖 7 大领域、4 种题型,每个细分格子里题数其实有点稀。雷达图上的某些点位(特别是开源小模型的某些题型)样本数可能就只有 20-30 道,单题影响就很大。
对工程实践的启示
如果你正在做或者准备做企业级文档智能系统,这篇论文我觉得至少有三点值得借鉴。
一是评测体系里加一个"证据维度"。
不要再只跑 DocVQA、MP-DocVQA 这种只看答案的榜了。哪怕你的产品不需要可视化引用,至少在内部评测里加一个 SAA 类似的指标——把模型回答和它声称的来源拉到一起对一遍。你会发现一些上线之前没察觉的问题。
二是"先定位再回答"的两段式架构值得重新考虑。
CiteVQA 的消融实验显示,把搜索空间从全文档缩到 GT 页,模型答案准确率能涨 5 个点;缩到 gold 文档,能涨 13 个点。这意味着如果你的检索器能做得更好一点(特别是在多文档场景),下游答题模块的天花板能跟着抬高一截。不要再把所有希望都压在"长上下文"上了,定位和回答分开做可能更靠谱。
三是数据自动标注的范式值得借鉴。
特别是那套"模板蒸馏 + MLLM agent 找证据 + mask 消融识别关键证据"的流水线。如果你需要为自己的业务场景造一个评测集,这套思路比纯人工标注便宜得多,而且最重要的是可复现——任何时候想增量更新,重跑一遍就行。
还想再聊一句
这种"答对了题、抄错了出处"的现象,其实不只是文档 VQA 的问题。在普通对话场景、RAG 应用、Agent 工具调用里,都能找到类似的影子——模型给出一个看起来合理的答案,但你追问"你是怎么得出这个结论的",它编出来的推理链跟实际生成路径完全对不上。
CiteVQA 选择在 Doc-VQA 这个相对可控的场景里把这个问题量化了。下一步,我挺期待看到类似的评测思路扩展到更广的领域——比如 Agent 的"工具调用归因"、推理模型的"思维链与答案一致性"等等。
只看答案、不看路径的时代该过去了。可信 AI 的下一程,归因和可追溯性会越来越重要。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新AI前沿,关注我