论文不再线性跑流水线:AutoResearchClaw 用辩论、自愈和跨次进化把 AI 科学家推上一个台阶
核心摘要
如果你跟过现有的"AI 科学家"系统跑过完整流程,应该会有一种很憋屈的感觉——它们把科研当成一条直线流水线:单 Agent 自问自答,跑实验一炸就退出,下一次重新开始还会踩同一个坑。可真实科研根本不是这样:假设要被反复挑战,实验失败本身就是信息,跨周期的教训会沉淀成下一轮的"安全带"。
UNC、UCSC、Stanford、CMU 等 12 家单位联手挂出来的 AutoResearchClaw(下称 ARC)就在解决这件事。它把整个 pipeline 拆成 23 个 stage、3 个 phase,围着五个机制转:多 Agent 辩论、自愈执行器(Pivot/Refine 决策环)、可验证结果报告、7 种粒度的人机协作、跨次运行进化。在自建的 ARC-Bench 25 个主题上,CoPilot 模式相对 AI Scientist v2 涨了 54.7 个百分点(0.648 vs 0.419,Overall);Result Analysis 这一项更夸张,翻了一倍。
更有意思的是 HITL 消融——干预越多并不越好。CoPilot 用 6 次精准干预拿到 87.5% 接受率和 7.27 的平均分;Step-by-Step 用 23 次干预只有 50% 接受率、5.19 分。这个结论我觉得是这篇论文里最值钱的部分。
论文信息
- 标题:AutoResearchClaw: Self-Reinforcing Autonomous Research with Human-AI Collaboration
- 作者:Jiaqi Liu、Shi Qiu(共同一作)、…… Mingyu Ding、Huaxiu Yao(通讯,UNC-Chapel Hill),共 35 位
- 机构:UNC-Chapel Hill、UC Santa Cruz、CMU、NUS、UC Berkeley、Rutgers、NEC Labs America、Meta、Stanford、Google、University of Washington、Recrusive.com
- arXiv:2605.20025
- 代码:github.com/aiming-lab/AutoResearchClaw
- 日期:2026 年 5 月 19 日
为什么现在的"AI 科学家"还是不太能打
我先把它要解决的问题摆清楚——不然后面五个机制看着就只是堆料。
AI Scientist v1/v2 这一脉,整体范式就一个字:串。一个 LLM 负责出 idea,同一个 LLM 评估这个 idea 好不好,然后写代码、跑实验,跑挂了就退出,结果分析也是这一个 LLM 自己看自己写的输出。整套流程的脆弱点全摞在一起:
- 出题人和判卷人是同一个:自己出的假设很难被自己反驳掉,弱假设会一路混到实验阶段;
- 执行一旦炸了就 GG:哪怕只是某个文件 import 错了,整次运行作废,前面那些可能本来就有用的中间产物也跟着扔;
- 跨次没有记忆:第 5 次运行和第 1 次没区别,今天踩的坑明天还会踩。
AIDE-ML 这边走的是另一条路,更像一个"实验机",但还是不带跨次记忆。Agent Laboratory 是单次内部多 Agent 协作,但同样不跨 run 学习。AI Co-Scientist 引入了辩论,但不真正跑实验。
ARC 作者的观察其实挺重要的一句:这三个问题不是独立的。
更好的假设会减少执行阶段的大返工;更稳的执行能保住中间结果给后续分析;过去 run 的教训能改进未来的假设和实验设计。
也就是说,这三块得放进同一个框架里一起搞,单独优化哪一块都不会有质变。这是它整篇文章的论证起点。
我自己跑过类似的多 Agent 实验系统,对这个判断挺有共鸣的——你单独把"自动 debug"做到很强,最后还是会被一个糟糕的初始假设拖死;你单独把"假设生成"做到很漂亮,落到代码层一炸还是白搭。
整体架构:23 个 stage,五个机制,一张图看完
下面这张是 ARC 的 pipeline 总览图。整个流程被拆成 Discovery / Experimentation / Writing 三个 phase,每个 phase 下面有具体的 stage(A 到 H),五个机制以横切的方式贯穿。
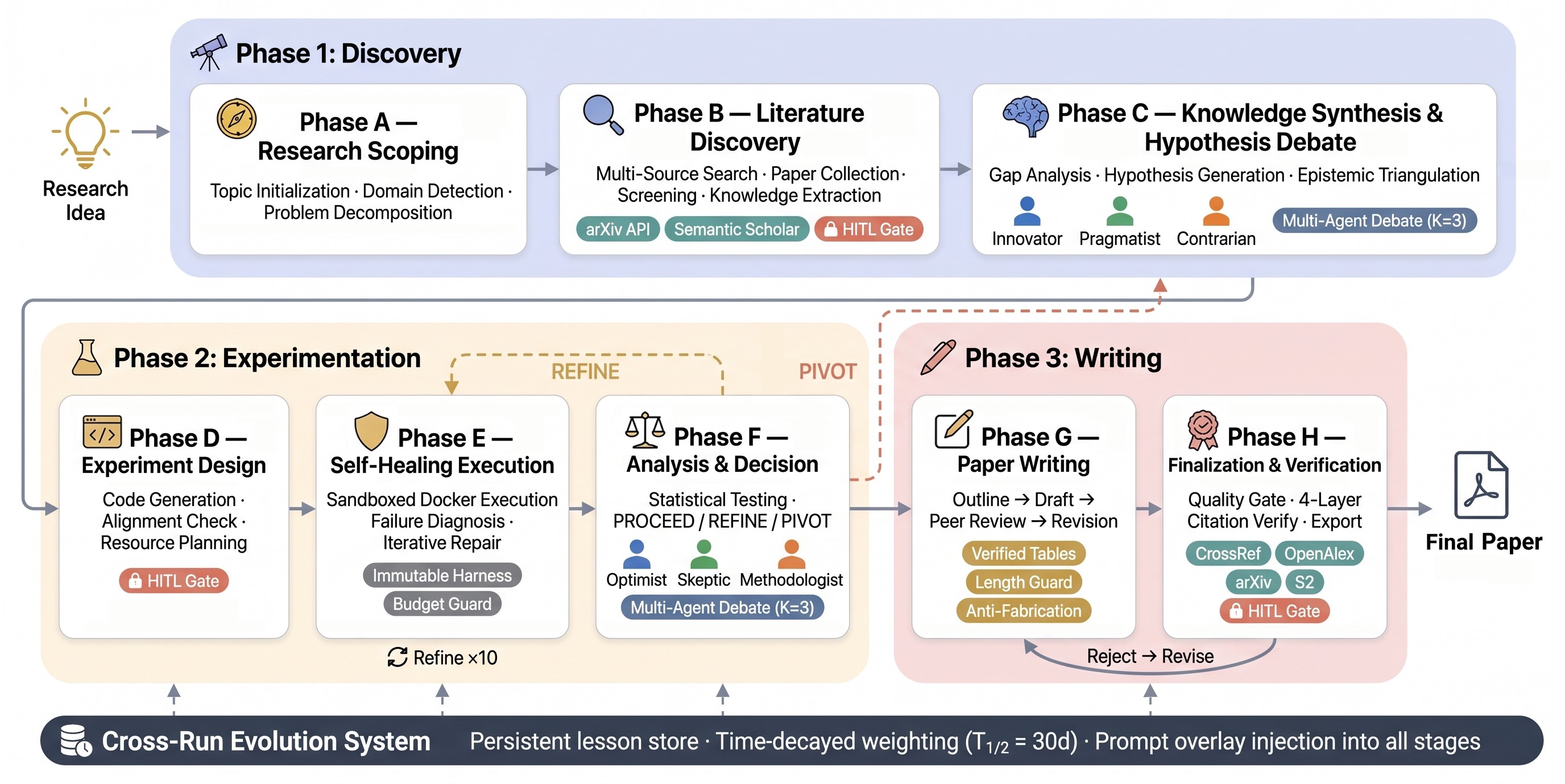
图1:ARC 的 23 阶段 pipeline 概览。三个 phase 分别负责发现、实验、写作;HITL gate 用橙色标出,作为可选的人类介入点;底部的 Cross-Run Evolution System 把过去的教训以时间衰减权重注入到所有阶段。
几个细节值得拎出来看:
- Phase 1 Discovery:先做 Topic 分解,再走文献检索(arXiv + Semantic Scholar),最后是 K=3 的辩论小组:Innovator(激进派)、Pragmatist(务实派)、Contrarian(唱反调)做假设辩论,最后由 synthesizer 收敛到 2–4 个可证伪的假设;
- Phase 2 Experimentation:实验设计、Docker 沙盒执行、结果分析。这里有第二个 K=3 辩论小组:Optimist、Skeptic、Methodologist,专门审结果。注意 REFINE 是回到 Phase E(执行)继续修,PIVOT 是直接退回到 Phase C(重新出假设);
- Phase 3 Writing:写稿 → peer review → 改稿 → quality gate → 4 层引用校验 → 输出;
- 底部那条粗黑横带就是 Cross-Run Evolution:持久 lesson store + 时间衰减权重 + Prompt overlay 注入。
23 个 stage 不是装饰——每个 stage 都有形式化的 input/output contract,支持 checkpoint resume。这点其实挺工程派的,长流程的可恢复性一直是这类系统的硬伤。
接下来我们一个一个看五个机制,为什么这样设计、它真的解决了什么。
机制一:两次结构化辩论,把"出题人 = 判卷人"的问题拆掉
第一次辩论在假设生成阶段,第二次在结果分析阶段。每次都是 K=3,角色不同:
| 阶段 | 角色 | 职责 |
|---|---|---|
| 假设阶段 | Innovator | 提高风险、挑战常规的假设 |
| Pragmatist | 评估在硬件/时间预算下是否可行 | |
| Contrarian | 主动找弱点、可能的混淆变量 | |
| 结果阶段 | Optimist | 把强的发现挑出来 |
| Skeptic | 挑战统计显著性、找潜在 confound | |
| Methodologist | 评估可复现性、查数据泄漏 |
最后由一个 Synthesizer 把三家意见揉成一个结构化产物——假设阶段是 2–4 个可证伪假设带测试标准,结果阶段是一份把"支持的 claim"和"不支持的 claim"分开的评估。
这一招好不好,要看消融实验。Table~\ref{tab:component-abl} 显示,去掉 Debate 这一块,平均质量从 5.62 降到 4.25(−1.37,p=0.003),是所有机制里质量贡献最大的。这个数我觉得是合理的——人类做科研,最难的其实是"找自己假设里的弱点",单 Agent 没有结构化激励去做这件事,光靠 Prompt 说"你要批判性地思考"基本是糊弄。
说实话,多 Agent 辩论这套从 2023 年 du 等人那篇 Improving Factuality and Reasoning via Multiagent Debate 之后就一直在被各种系统用,新意不算大。但 ARC 把辩论精准地嵌进两个最容易出问题的环节——出假设和读结果——而不是堆在整个 pipeline 里 K=10 那种"显得很热闹"的设计,这个工程取舍是对的。
机制二:自愈执行器与 Pivot/Refine——失败也是信息
这是我个人觉得最值得仔细看的部分。
现有系统对"实验失败"基本是两种态度:要么直接退出(AIDE-ML、AI Scientist),要么无脑重试(很多 ReAct 风格的 agent)。ARC 的处理方式更像一个真实的研究员:先诊断、再决定方向、保留中间产物。
级联式代码生成
不是所有实验都该用同一个 codegen 策略。ARC 用一个 6 维打分函数算复杂度 c ∈ [0,1]:
- 架构深度(模型多复杂)
- 文件数量
- domain 难度
- 依赖链长度
- 历史失败率
- 控制流复杂度
阈值设 τ=0.6。复杂度高于 0.6 的丢给外部 AI coding agent(论文里跑的是 GPT-5.3-codex 后端 + Claude Code 子进程),低于 0.6 的用内置多阶段 code agent:先生成 per-file blueprint,然后按依赖顺序逐个文件生成,用 AST 摘要保证跨文件一致性。
这个分流我特别理解。我之前在做实验 agent 的时候踩过的坑——你给一个"端到端写一个 4 文件的 PyTorch + Lightning 训练代码"的任务,不管多强的模型一次成功率都低得感人。但你拆成"先出 blueprint 再按依赖序填文件",成功率立刻上一个台阶。
三阶段网络策略
Docker 沙盒里跑代码,分三个阶段:
- Phase 0:开网,装依赖
- Phase 1:开网,下数据
- Phase 2:关网,跑实验
这个 Phase 2 关网是个挺细节但很关键的设计。两个作用:防止生成的代码偷偷上传结果(可能性低但确实存在),更重要的是防止它去网上下载已经算好的结果直接当自己的结果交差。这事 LLM 真的会干,我见过不止一次。
更狠的是 metric 上报只能通过一个只读的 evaluation harness,生成代码没法重写自己的测量函数。这等于是把"作弊"路径在工程层面物理切断。
Pivot / Refine / Proceed
实验失败或者结果退化的时候,自动 repair loop 抓 failure signature → 生成有针对性的修复,然后系统做三选一:
- Proceed:证据支持假设,继续往下走
- Refine:结果弱但方向是对的,调当前实验再跑一次
- Pivot:方法根本不对,带着这次失败的证据回到假设生成阶段重新开始
这个 Pivot 是整篇论文的精髓之一。它把"失败"从一个 termination signal 变成了一个 evidence——重新出假设的时候,"为什么这条路走不通"本身就是一条强约束。
数据怎么说话?消融里去掉 Self-Healing 后,完成率从 10/10 掉到 6/10,这是所有机制里完成率影响最大的。再去掉 Debate 一起,完成率直接 4/10、接受率 0/10。这个 super-additive 的交互很关键——辩论生成了野心更大的假设,自愈才扛得住实验阶段的折腾;反过来,自愈机制如果在修一个根本没意义的实验,也是白修。
机制三:可验证结果报告——把伪造数字和幻觉引用钉死
LLM 写论文的两个老问题:编数据和编引用。两者本质都是一回事——模型在生成"看起来合理"的内容,没有任何 grounding。
ARC 用两套确定性的 verification gate 来处理:
Numeric Registry(数字注册表)
执行阶段,系统把每一次实验跑出来的值都登记到一个 verified registry 里:每个条件的均值、标准差、单个 seed 的具体测量值。写稿阶段,预先填好的 LaTeX 表格直接从 registry 注入到生成 prompt。
写完之后还有一个 post-hoc verifier 把生成的每一个数字提取出来,跟 registry 里逐条对照——而且是按 condition 分桶比对,防止跨 condition 的假阳性匹配。严格章节(Abstract / Results / Experiments)里对不上 registry 的数字会直接触发文档拒绝,其他章节里对不上的数字会被替换成 visible placeholder。
Writing agent 能读 registry 但不能写。这就是关键。
引用校验:四层 fallback
每条 reference 走:
- CrossRef 的 DOI 解析
- OpenAlex 的模糊标题匹配
- arXiv ID 查
- Semantic Scholar 兜底
然后再过一个 LLM 相关性判断,分成 Verified / Suspicious / Hallucinated 三档。Hallucinated 的直接从稿子里删掉,draft 才算定稿。
消融里去掉 Verification 那行有意思:质量分从 5.62 升到 5.48(差不多),但接受率从 3/10 涨到 5/10——看起来更好了。但人工 audit 发现,那 5 篇里有 3 篇的数字在任何测量记录里都找不到——也就是说,去掉验证之后系统"看起来表现更好"是因为它学会了编数字。论文里专门用 ‡ 标注:"Score inflated by removing the verification gate"。
这个对比真的能讲清楚一件事:在 LLM 自动科研系统里,verification 不是锦上添花的功能,是 integrity backstop。你不上这一层,benchmark 分会涨,但你做出来的就不是科研系统,是 paper generator。
机制四:HITL 的七档干预——精准 > 全包
这块是我觉得论文最反直觉、也最值钱的发现。
ARC 提供 7 种干预模式,从 0 次干预到每个 stage 都要批准:
| 模式 | 触发点 | 干预次数 |
|---|---|---|
| Full-Auto | 不干预 | 0 |
| Gate-Only | 文献筛选、实验设计、最终质量审查 3 个 gate | 3 |
| CoPilot | 6 个高杠杆决策点(含 Idea Workshop、Baseline Navigator、Paper Co-Writer 等) | 6 |
| Thorough | 所有 phase 边界 | 8 |
| Step-by-Step | 每个 stage 都要批 | 23 |
| Pre-Experiment | 只在实验前 3 个点干预(文献、假设、设计) | 3 |
| Post-Experiment | 只在实验后 3 个点干预(结果分析、写稿、quality gate) | 3 |
另外还有一个 SmartPause——动态根据系统自身的 uncertainty 来决定要不要停下来叫人,而不是固定 checkpoint。这个机制描述比较短,但思路是对的:研究员经常 override 的 stage 加大停顿概率,研究员一直 approve 的 stage 就让它自己跑。
HITL 消融结果
| Mode | Valid | Mean Q | Accept | Interventions |
|---|---|---|---|---|
| Full-Auto | 8/10 | 4.03 | 25.0% | 0 |
| Gate-Only | 10/10 | 5.03 | 50.0% | 3 |
| CoPilot | 8/10 | 7.27 | 87.5% | 6 |
| Thorough | 7/10 | 4.86 | 42.9% | 8 |
| Step-by-Step | 10/10 | 5.19 | 50.0% | 23 |
| Pre-Experiment | 8/10 | 4.28 | 37.5% | 3 |
| Post-Experiment | 6/10 | 5.08 | 50.0% | 3 |
CoPilot 用 6 次干预,质量分 7.27,接受率 87.5%。Step-by-Step 用 23 次干预,只拿到 5.19 分和 50% 接受率。
我看到这个数字的第一反应是有点惊讶——按直觉,干预越多结果应该越好(至少不会变差),但实际是干预多了反而拖累。论文给的解释很直接:
Step-by-Step 在非关键 stage 上的 approve 动作只增加噪声,不增加信息;CoPilot 把专家判断集中在边际影响最大的地方。
这个判断其实可以从信息论角度想——每次干预都是一次"决策点上的人类信号注入"。如果一个 stage 系统本来就能稳定做对(比如格式化输出),你的 approve 不提供任何新信息,但它会增加上下文长度、稀释 prompt 中真正重要的信号;更糟的是,研究员在非关键 stage 上消耗的注意力,会让他在真正关键的 stage 上做出更草率的判断。
Pre vs Post 的对比也挺有意思:
- Pre-Experiment:8/10 valid(覆盖广),但质量只 4.28,37.5% 接受率
- Post-Experiment:6/10 valid(覆盖窄),但单篇质量高
- CoPilot:横跨 Pre + Post,所以综合最强
论文给的解释是:Pre-Experiment 修可行性,Post-Experiment 修 claim 的忠实度。两个修的是不同的失败模式,所以缺一不可。Post-Experiment 单独用的时候 valid 率只有 6/10——晚期 HITL 没法"从无中生有地造出实验证据"。
这条结论我觉得能直接迁移到很多类似系统设计上:人类专家最值钱的不是看着 AI 干每一步,而是在"AI 容易出错且后果严重"的几个点上提供精准的 high-leverage 输入。
机制五:Cross-Run Evolution——把昨天踩的坑变成今天的安全带
每次 run 结束,系统从 repair attempts、Pivot/Refine 决策、HITL gate 反馈、verification 结果里抽出结构化 lesson。每条 lesson 有:
- 类别(category)
- 严重度 s(l) ∈ (0, 1]
- 推荐的 mitigation
下一次 run 启动时,相关 lesson 按时间衰减权重排序:
其中 \(T_{1/2}\) 默认 30 天。这个公式其实就是放射性半衰期那套——一个月前的教训权重减半,两个月前再减半。
为什么要时间衰减?我的理解是两层:
- 科研主题在变——你三个月前在 NLP 上遇到的坑,三个月后在 GP 核函数上可能就不适用;
- lesson store 不能无限膨胀——如果所有历史 lesson 都保持满权重,prompt 会被旧 lesson 塞满,新 lesson 的影响力反而被稀释。
Lesson 以自然语言 overlay 的形式注入 prompt——这个设计很轻量,不需要任何模型再训练,理论上换任何 LLM backbone 都能用。这一点对工程落地是个加分项。
消融里去掉 Evolution,质量从 5.62 掉到 5.14(−0.48),完成率从 10/10 掉到 9/10。影响中等——它不是质量天花板的推动者,更多是"减少踩同一个坑的概率"。这个定位我觉得是诚实的,作者没有过度吹这个机制。
实验结果:ARC-Bench 上的硬碰硬
ARC-Bench 是作者自建的基准,25 个 ML 主题(ML01–ML25),覆盖了 tabular ML、优化、降维、NLP、AutoML、GP kernel、主题模型、半监督、动力系统、异常检测、特征选择、因果发现、learning-to-rank 这些方向。打分用 CD : CE : RA = 25 : 25 : 50 的三维 rubric:
- Code Development(CD):实现是否正确反映了提出的方法和 baseline
- Code Execution(CE):实验能不能完整跑完、产出有效输出
- Result Analysis(RA):结论是否 grounded 在真实测量上、是否给出 per-hypothesis 的 verdict、是否诚实报告 limitations
RA 占双权重——作者的逻辑是"这个维度才是区分'自主科研'和'自动化脚本'的关键"。
主表(25 主题)
| Framework | Code Dev | Code Exec | Result Analysis | Overall |
|---|---|---|---|---|
| ARC (CoPilot) | 0.968 | 0.578 | 0.523 | 0.648 |
| ARC (Full-Auto) | 0.938 | 0.562 | 0.442 | 0.596 |
| AIDE-ML | 0.958 | 0.415 | 0.336 | 0.511 |
| AI Scientist v2 | 0.712 | 0.442 | 0.261 | 0.419 |
几个观察:
- Code Dev 都不低。AIDE-ML 0.958,跟 ARC 几乎打平。这说明现在 LLM 把"写代码"这一关基本过了。
- 真正的差距在 Code Execution 和 Result Analysis。AIDE-ML 写得出来但跑不通——0.415 的执行成功率反映出"没有自愈" 的硬伤。ARC 靠 Pivot/Refine 把执行率拉到 0.578(CoPilot)。
- Result Analysis 上 ARC vs AI Scientist v2 是 0.523 vs 0.261,差不多翻一倍——这是辩论机制 + verified registry 联合的功劳。AI Scientist v2 单 agent 分析很容易"oversell weak findings",缺乏 cross-examination。
跨学科扩展(生物 / 统计 / 物理)
ARC 还做了一个 20 主题的科学领域扩展,10 个高能物理(HEP)+ 7 个系统生物 + 3 个统计。这部分挺有意思——两个 baseline 直接挂了:
| Framework | Biology | Statistics | HEP-ph | Overall |
|---|---|---|---|---|
| ARC (CoPilot) | 0.912 | 0.898 | 0.489 | 0.867 |
| AIDE-ML | × | 0.452 | × | 0.090 |
| AI Scientist v2 | × | 0.418 | × | 0.084 |
× 代表执行失败——baseline 系统的 sandbox 装不上 HEP(MadGraph、Pythia8、Delphes 这套)和生物(COBRApy + BiGG 基因组规模模型)需要的领域软件栈。ARC 用 sandboxed domain-specialized agent——HEP agent 装好 FeynRules / MadGraph / MadAnalysis;生物 agent 装好 GEM-builder、flux-balance analysis;统计 agent 装好 Monte Carlo + 半参数推断。每个 specialized agent 跑在自己的 Claude Code 子进程里。
这块的意义不是 ARC 拿了高分,而是 existing 系统在跨学科科研这件事上几乎为零。HEP 和生物领域那个 × 不是 ARC 故意挑刺,是这些领域的实验软件栈真的就只能这么做。论文挺诚实地把 HEP 那 0.489 摆出来——这是个偏低的分,作者解释是 "due to insufficient deliverable content and minor unsupported meta-claims",没掩饰。
组件消融:每个机制究竟贡献了什么
| Configuration | Completion | Quality | Accept | Fabrication |
|---|---|---|---|---|
| Full ARC | 10/10 | 5.62 | 3/10 | × |
| w/o Debate | 10/10 | 4.25 | 1/10 | × |
| w/o Self-Healing | 6/10 | 4.83 | 1/6 | × |
| w/o Evolution | 9/10 | 5.14 | 2/10 | × |
| w/o Verification | 10/10 | 5.48‡ | 5/10‡ | ✓ |
| w/o Debate & Healing | 4/10 | 3.47 | 0/4 | × |
(‡ 表示验证关闭后分数虚高;最后一列 ✓ 表示出现了 fabrication)
总结成一句话:Debate 拉质量,Self-Healing 拉完成率,Verification 守底线。
最关键的是最后一行的 super-additive:单独去掉 Debate 是 −1.37,单独去掉 Self-Healing 是 −0.79(5.62 → 4.83),如果两者是独立加性的应该是 5.62 − 1.37 − 0.79 = 3.46……巧合的是实际值是 3.47,几乎完全吻合。也就是说,这两个机制确实是接近独立的两个失败模式,去掉一个会暴露出另一个的脆弱性。
我看的时候有个小怀疑——这个 super-additive 是不是过拟合到这 10 个主题的特定失败分布?理论上需要看 25 个主题完整版的消融才好下结论,但 10 主题已经能看出趋势了。
Case Study:T10 是个非常有教育意义的失败
第 5 小节挑了 T10(交叉验证策略对小样本模型选择的影响)做了一个 Full-Auto vs CoPilot 的对比。这一节我觉得作者写得相当用心。

图2:T10 案例研究——Full-Auto 与 CoPilot 在四个维度(Tables / Figures / Method / Analysis)上的对比。Full-Auto 出现了"沉默的语义崩溃":所有 8 种 CV 策略都报告 0.000 的 bias,表格和图都是平的;CoPilot 因为人类在实验语义这个高杠杆点上做了介入,最终得到了 9 个有差异化的 pipeline 结果。
Full-Auto 模式下,所有 8 个 CV 策略都输出了一模一样的 0.000 bias——这种失败 runtime metrics 是抓不到的。论文管这个叫 silent semantic collapse:代码跑通了,结果有数字,verification gate 也过了(因为 0.000 也是一个真实测量值),但这些数字根本不能支撑科学比较。
CoPilot 模式下,人类在三个点做了介入:
- 检查不同 CV 策略是否会产生不同结果
- LOOCV 是否能在时间预算内跑完
- 论文里的 claim 是否都落在 log 里有的结果上
结果就完全不一样了——9 个有差异化的 pipeline 结果(LOOCV 0.072、RS5 0.002 等),meaningful 的对比能做了。
这个案例告诉了我们三件事:
- Debate 即使在执行成功的时候也重要:Contrarian 的"这几个 ablation 真的能区分开吗"那种质疑能在崩溃发生之前就拦下来;
- Verification 必要但不充分:它能保证数字真实,但管不了"这些数字回答的是不是研究问题本身";
- CoPilot 提升质量不是靠加更多干预,而是把干预放对位置。
第三点回到了 HITL 消融的那个核心发现——精准 > 全包。
我的判断:值得读,但有几个我想吐槽的地方
真的不错的几点
-
五个机制不是堆料,是真的形成闭环。Debate 出强假设 → Self-Healing 让强假设的实验不至于一炸就死 → Verification 保证 claim 落地 → HITL 在关键点放大人类判断 → Evolution 让经验沉淀。这个闭环我觉得是当前 autonomous research 系统里最完整的。
-
HITL 消融那张表是真的有价值。"精准干预 > 全包监督"这个结论可以推广到几乎所有 human-in-the-loop AI 系统的设计——RLHF 的标注策略、Agent 系统的人工审核、甚至代码 review 的频率,都能套这个判断。
-
Verification 那一段写得诚实。w/o Verification 的 5.48 分被作者主动标注为虚高,并且做了人工 audit 报告 3/5 是编的——很多 paper 会用类似的"看起来更好"的数字来粉饰,ARC 没这么干。
-
跨学科扩展的×是真的。把 HEP 的 0.489 摆出来,说自己也没那么完美——这是个加分点。
我有保留意见的地方
-
ARC-Bench 是自建的。25 个 ML 主题、20 个科学主题,全是作者团队定的。这套基准本身合不合理、有没有偏向 ARC 的设计哲学,需要更多独立验证。比如 RA 给双权重这个设计,对辩论机制是天然友好的——AI Scientist v2 那种单 agent 在 RA 维度上本来就会吃亏。这不是说作者作弊,是说"benchmark 设计本身就携带了对自家方法的归纳偏置"。
-
Baseline 用 GPT-5.3-codex 跑 AI Scientist v2 是 fair 但不是 representative。AI Scientist v2 在论文里被作者团队 prompt-engineering 过得很精细,换 backbone 之后表现会不会下降?同 backbone 比拼系统设计这个出发点没问题,但读者得明白这个数字不能直接套到原版上。
-
CoPilot 的 6 次干预具体在干什么? 论文里只说覆盖了 Idea Workshop、Baseline Navigator、Paper Co-Writer 等 6 个点,但每次干预的具体形式(是审查 + 批准?还是改写内容?还是给一个 hint?)展开得不够。这直接关系到这套方法能不能复现——如果是高质量的研究员花 20 分钟深度参与每个 gate,跟一个研究生快速点 approve,效果天差地别。
-
35 个作者这件事本身就挺反讽的。一篇关于"AI 自主科研"的论文需要 35 位作者来写,而且来自 12 个机构——这本身就说明,真实的高水平科研,至少在现阶段还是离不开大规模人类协作。这跟论文最后那句"research amplifier that augments rather than replaces" 倒是挺呼应的。
-
Cross-run Evolution 的效果证据偏弱。−0.48 质量、−1 完成率,相比 Debate 和 Self-Healing 的影响显得没那么明显。半衰期 30 天这个超参也没有做 sensitivity 分析。我猜在更长时间跨度(比如跑了 50 次 run 之后)这个机制才会真的体现价值,但论文里没有这个实验。
工程启发:如果你也在做类似的事
我想给三个具体的建议:
第一,别再线性串了。如果你正在做 LLM 驱动的自动化流程(实验、报告生成、数据分析 pipeline 都算),把"执行失败"和"假设错了"在架构上分开处理——失败该修就修,方向错了就 Pivot 回去重新出方案。这个 Pivot/Refine 的二分逻辑可以泛化到很多场景。
第二,验证层别省。LLM 写出来的数字默认应该是不可信的,必须有一个独立于生成路径的 verification 层。Numeric registry 这个思路特别适合任何"LLM 生成报告"的场景——不管是科研报告、运营周报、还是数据分析结果。让生成 agent 只能读,不能写测量值,这是 anti-hallucination 的关键工程动作。
第三,HITL 的设计哲学是精准 \gt 全包。如果你在做 Copilot 类产品,要花最多精力的不是"让 AI 全自动",而是"找到那 5–10 个高杠杆决策点,把人放在那里"。这件事比加更多 LLM 调用要值钱得多。
收尾:一个对的方向,但还在早期
ARC 这套系统不算是革命性突破,但它把过去三年 autonomous research 这个方向上零散的好想法(多 agent 辩论、self-healing、HITL、cross-run learning)系统性地装进了同一个 pipeline,并且用一个相对硬的基准证明了组合后的效果。
我不觉得 AI 科学家会在短期内真的"取代"科研,但这类系统作为"研究放大器"——帮你跑那些你知道怎么做但懒得花时间做的实验、帮你写那些你早就想清楚但不想动笔的稿子——已经具备相当实用价值。ARC 在这条路上做得比之前的同类系统都要往前走一截。
但说实话,看完之后我也有个更本质的问题:这种"很重的系统" + "很精细的 HITL"的组合,能不能扩展到真正前沿的科研问题上? ARC-Bench 里那些主题——CV 策略对比、AutoML、半监督——其实还是"已知方法在已知数据集上的优化",不是真正意义上的 novel discovery。真正的科学突破往往是"问出一个之前没人问的问题",这个能力 ARC 还远远没有 demonstrate。
不过这个就属于"AI for Science"领域大家共同面对的挑战了,不能算 ARC 一家的锅。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新AI前沿,关注我