教蒸馏教师"少看一点",反而学生学得更好——LLM 推理自蒸馏的一个隐藏旋钮
论文:Adaptive Teacher Exposure for Self-Distillation in LLM Reasoning 作者:Zihao Han, Tiangang Zhang, Huaibin Wang, Yilun Sun 链接:https://arxiv.org/abs/2605.11458 关键词:On-Policy Self-Distillation、Teacher Exposure、Beta Policy、Delayed Credit、LLM Reasoning
写在最前面
如果你最近也在做 LLM 的推理后训练,大概率绕不开 On-Policy Self-Distillation(OPSD)这套范式。一个模型同时扮演老师和学生:学生跑自己的 rollout,老师拿着标准答案在旁边逐 token 打分。这个范式比纯 RL 的稀疏奖励更密,比 SFT 的离线监督更对齐分布,工程上挺香。
但有件事,我相信很多人没认真想过:
老师每次都该看到完整的参考推理吗?
这篇 5 月挂出来的 NeurIPS 2026 投稿 ATESD 做的事就是这个——把"老师能看到多少参考"从一个写死的默认设定,变成训练过程里可学习的控制变量。Qwen3-1.7B/4B/8B 三个规模在 AIME 24、AIME 25、HMMT 25 上稳定优于 OPSD,提升幅度 +0.95、+2.05、+2.33(Average@12),而且越大的模型涨得越多。
100 字摘要里我最想强调的判断:这工作的问题切入很漂亮,它定位的"教师侧暴露失配"是一个之前 OPSD 这套体系里被默认掉了的设计选择。从"是不是 bug"到"用 Beta 策略 + REINFORCE 把它做成可学习"的这条链路也基本走通了。但绝对提升幅度不算大,1.7B 上 +0.95 已经贴在标准差边界上了,需要清醒看待。
一、痛点先讲清楚:OPSD 这套范式到底卡在哪
先快速过一下 OPSD(On-Policy Self-Distillation)是什么。如果你已经很熟,可以跳过这一段。
传统蒸馏是 off-policy 的:老师生成数据,学生在老师的轨迹上学。问题是经典的 exposure bias——训练时学生看到的是老师的完美前缀,推理时却要在自己(带错误)的前缀上接龙。
OPSD 的解法挺优雅:
- 学生用自己的策略 \(p_S(\cdot | x)\) 从问题出发采样 rollout \(\hat{y}_{1:T}\)
- 老师 \(p_T\) 在同一段学生采样的 token 上提供 token 级的目标分布——但老师手里有"特权",可以条件在参考推理 \(y^*\) 上
- 学生最小化 token 级 KL:\(D_{KL}(p_T \,\|\, p_S)\)
这个范式 2025 年下半年系统化提出后用得很广,因为它同时拿到了 RL 的 on-policy 性 + SFT 的稠密信号。学生没有偏离自己的分布去学,但每个 token 又都有反馈,不像 RL 一条轨迹只给一个标量奖励。
问题出在哪?
ATESD 这篇论文把矛头指向第 2 步里一个所有人都默认没动的设定:老师每次都看到完整的参考推理 \(y^*\),从第一步推到最后答案,一字不漏。
作者起了个名字叫 teacher-side exposure mismatch(教师侧暴露失配)。直觉上讲:
如果老师条件在的推理远远超出学生当前的能力,那它给出来的 token 目标分布就太"理想化"了——学生当前根本吸收不动。
这跟带学生是一个道理。一个刚入门竞赛的初中生,你直接把整套"先用判别式判根的性质再用韦达定理"的完整解法摆给他做监督目标,他能看懂个皮毛,但每一步的 logit 分布对他来说都是奢侈品。你只给个"先想想根的乘积"的小提示,让他自己推下去,学得反而扎实。
下面这张图是论文的 Teaser,把这个直觉画得挺到位:
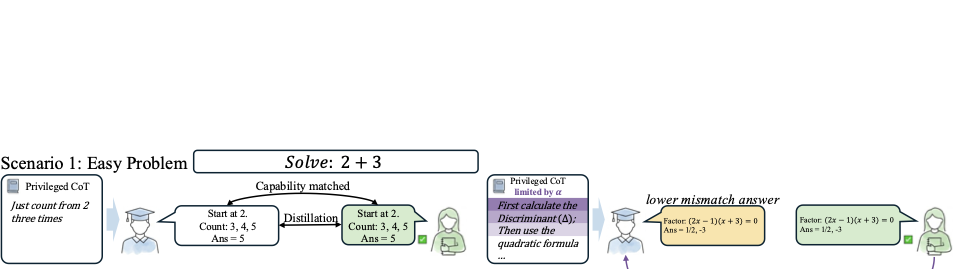
注意右边那个场景:当老师条件在了一段超出学生能力的"判别式 + 二次公式"推理时,老师 logit 和学生 logit 之间形成了大 gap;而把老师的暴露压低、只让它看到一部分参考推理时,gap 就显著下降——学生反倒更容易吸收。
二、把直觉做成实验:固定暴露扫描
这种"老师太强反而学不动"的话,听起来很对,但 ATESD 没满足于直觉,他们先做了一组诊断实验,我觉得这是这篇论文最值得点赞的地方。
设定是这样的:引入一个连续旋钮 \(\alpha \in [0, 1]\),表示老师能看到参考推理的前缀比例。具体做法是对参考 CoT 做前缀截断——假设完整推理是 \(r_1, r_2, \ldots, r_m\),截断成前 \(\lfloor \alpha \cdot m \rfloor\) 段,但最终的 boxed 答案始终保留。
- \(\alpha = 0\):老师只看到问题和最终答案,中间推理一字不见
- \(\alpha = 1\):老师看到完整推理(这就是标准 OPSD)
- 中间值:老师看到部分推理步骤
然后扫一遍 \(\alpha \in \{0, 0.25, 0.5, 0.75, 1.0\}\),3 个 seed,记录学生最终性能和老师-学生分歧度。
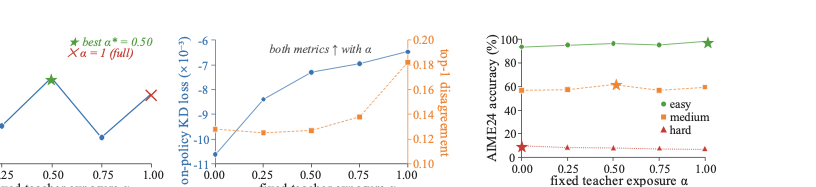
结果分三块看:
Panel A(左)—— 最优暴露不是 1.0:在 Qwen3 上扫完 5 个固定 \(\alpha\),最优是 \(\alpha^* = 0.5\),全暴露 \(\alpha = 1\) 反而只是次优。这是论文最关键的反直觉发现:给老师更多特权信息,并不自动转化为更好的学生监督。
Panel B(中)—— 失配单调上升:on-policy KD loss 的 tail 和 top-1 disagreement 都随 \(\alpha\) 单调增长。说人话就是,老师看的越多,输出分布和学生差得越远。这个跟 A 拼起来看就很有意思:分歧越大,性能反而不一定越好,存在一个最优中间点。
Panel C(右)—— 难度敏感:把题目按难度分 easy/medium/hard,easy 题偏好高暴露(\(\alpha = 1.0\)),medium 题偏好 \(\alpha = 0.5\),hard 题偏好最低暴露。没有一个全局的 \(\alpha\) 同时是所有难度上的最优。
到这一步,论文已经把问题坐实了:
教师暴露这件事不应该是固定超参,而应该随训练状态和样本特性动态调整。
我其实挺欣赏这种推导方式的——先把一个被默认掉的设定拎出来做受控扫描,让数据自己开口说话,再过渡到方法设计。比那种上来直接甩个新算法说"我们设计了一个 xxx 来解决 yyy"的论文要扎实得多。
三、ATESD 三件套:暴露调制 + Beta 控制器 + 延迟信用
诊断完问题就该谈解法。ATESD 的架构是三层叠起来的,下面这张大图把整个 pipeline 画清楚了:
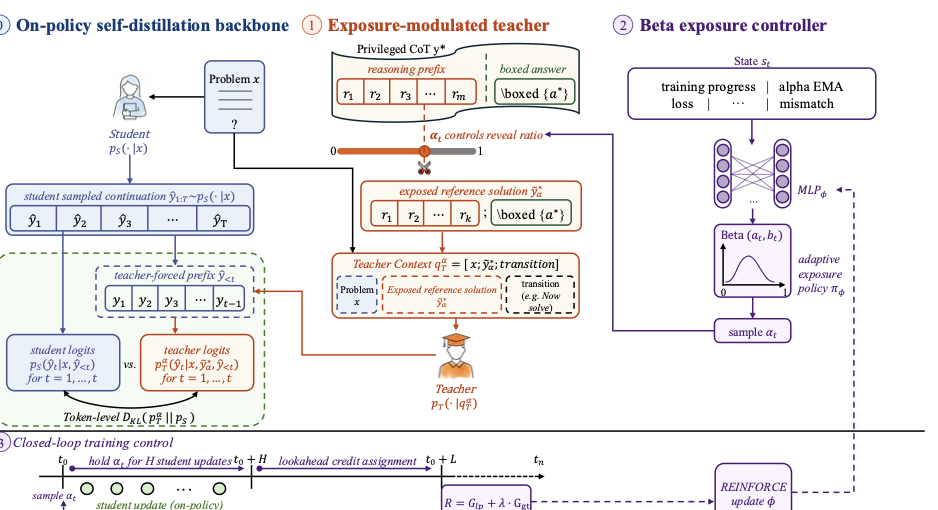
我顺着这张图从左到右讲。
3.1 Exposure-Modulated Teacher:连续旋钮
学生这一侧完全没变——还是从 problem-only 的 prompt 自己采样 \(\hat{y}_{1:T}\),保持 on-policy。
变的是老师那一侧的上下文。给定当前的 \(\alpha_t\),老师看到的不再是完整 \(y^*\),而是:
其中 \(\tilde{y}^*_{\alpha_t}\) 是参考推理的前缀截断版(前 \(\lfloor \alpha_t \cdot m \rfloor\) 段 reasoning + boxed answer),\(\tau\) 是一个固定的 transition 提示(类似"现在请基于上面继续解答")。
注意一个关键细节:boxed answer 始终保留。也就是说,无论 \(\alpha_t\) 多小,老师都能看到最终答案。\(\alpha_t\) 只控制中间推理给老师看多少。这个设计避免了 \(\alpha = 0\) 时老师彻底没有信号、KL 完全失去意义的边界 case。
蒸馏目标就在 OPSD 原 loss 的基础上把老师上下文替换掉:
梯度只过学生,老师每次只是个被 \(\alpha_t\) 调制的 scoring function。
3.2 Beta Exposure Controller:怎么挑 \(\alpha_t\)
固定暴露扫描已经证明"中间值更好、且依赖训练状态"。接下来的问题就是:怎么自动挑 \(\alpha_t\)?
ATESD 的选择是把 \(\alpha_t\) 建模成 Beta 分布的采样:
其中 \(f_\phi\) 是一个轻量 MLP,输入是训练状态 \(s_t\),输出 Beta 的两个浓度参数(用 softplus 保正、加 1 保证 unimodal)。
为什么是 Beta? Beta 分布的支撑集天然就是 \([0, 1]\),跟"参考推理暴露比例"完美匹配;而且它形状灵活——可以扁平、可以单峰、可以偏左偏右,比硬塞高斯然后 sigmoid 之类的处理优雅得多。\(a, b > 1\) 的约束保证单峰,让"我现在偏好哪个暴露区间"这件事有清晰的几何意义:mean 是偏好水平,concentration 是确信度。
状态 \(s_t\) 长什么样? 论文用了一组紧凑的训练状态统计量:
- 全局训练进度(归一化的当前 step)
- 近期 \(\alpha\) 的 EMA
- loss 和 mismatch 的 EMA
- probe-NLL 的 EMA
- batch 聚合的学生 self-confidence
不是什么复杂特征,主要是确保 controller 看到"训练进行到哪一步、学生当前状态如何、最近的反馈大概是什么样"。
Hold Window 设计:采样到一个 \(\alpha_t\) 之后,不是每个 student step 都重新采,而是固定保持 \(H\) 个 student update。这个设计有两个意义:
- 减小 controller 决策的方差——一个 \(\alpha_t\) 决策被使用很多次,反馈也更稳定
- 让信用分配可行——如果每步都换,根本说不清是哪个 \(\alpha\) 影响了 loss
3.3 Closed-Loop Training Control:延迟信用是关键
这部分是整个框架我觉得最精巧的设计。
为什么需要延迟信用?因为蒸馏的效果说到底是有滞后的。你在 step \(t_0\) 选了一个 \(\alpha_{t_0}\),老师在这个暴露下给学生提供了 token 级目标,学生 backward 一步——但这一步的 loss 变化是"嘈杂的",它既受 \(\alpha_{t_0}\) 影响,也受 batch 噪声、optimizer 状态、其他 sample 影响。
更要命的是:好的 \(\alpha_t\) 可能当下 loss 降得不多,但后面几个 step 学生越学越稳;坏的 \(\alpha_t\) 可能当下 loss 降得很猛(比如教师太接近学生的时候),但学生学到的东西很 trivial,后续不再涨。
ATESD 的奖励函数把这个直觉数学化了。对于在 \(t_0\) 采样的一个 hold action,等它走完 \(L\) 步前瞻窗口后,计算:
拆开看:
- \(G_{\text{lp}}\)(learning progress):折扣化的"loss 单调下降量"。只奖励正向的 loss drop,避免噪声造成的负向波动被算成负奖励。这个项的物理意义是:你的 \(\alpha_t\) 选完之后,学生在接下来 \(L\) 步里有没有持续变强?
- \(G_{\text{gt}}\)(teacher-grounded score):暴露调制后的老师对参考答案的平均 log-prob。意义是:当前 \(\alpha_t\) 下,老师"还认不认得标准答案"?防止 controller 偷懒——比如把 \(\alpha\) 压到很低让 mismatch 看起来小、但其实老师已经跟参考答案脱节了。
- \(\lambda_{\text{gt}}\):两者的加权系数。
REINFORCE 更新 controller 时用 centered + normalized advantage:
最后一项是 entropy bound——只惩罚"过度探索"(熵高于目标值),不强制最低熵,让 controller 在训练后期有需要时可以收敛到窄分布。
3.4 一个完整 step 的流程
把上面串起来,ATESD 一个完整训练循环长这样:
- 当前 step \(t_0\):Beta controller 看 \(s_{t_0}\),采样 \(\alpha_{t_0} \sim \text{Beta}(a_{t_0}, b_{t_0})\)
- 接下来 \(H\) 步 student update:每步都用同一个 \(\alpha_{t_0}\) 调制老师上下文,跑标准 OPSD KL loss,只更新学生
- 走完 hold window 再过 \(L\) 步前瞻
- 收集 \(G_{\text{lp}}\) 和 \(G_{\text{gt}}\),组合得到 reward \(R(t_0)\)
- 当累积了一个 batch \(B\) 的完成决策,用 REINFORCE 更新 \(\phi\)
- 回到 1
学生每个 step 都更新,controller 每个 batch 决策(约每 \(H + L\) step)更新一次——两者节奏解耦。这也是延迟信用分配能落地的关键工程细节。
四、实验:三规模一致提升,但幅度需要分模型看
主表先放上来:
| 模型 | 方法 | AIME 24 | AIME 25 | HMMT 25 | Average |
|---|---|---|---|---|---|
| Qwen3-1.7B | Base (Instruct) | 51.5 | 36.7 | 23.1 | 37.1 |
| + SFT | 48.4 | 36.3 | 22.7 | 35.8 | |
| + GRPO | 51.1 | 38.3 | 23.7 | 37.7 | |
| + OPSD | 57.2 | 43.9 | 29.2 | 43.4 | |
| ATESD | 59.17±0.80 | 44.72±0.28 | 29.17±1.37 | 44.35±0.23 | |
| Qwen3-4B | Base | 74.9 | 66.4 | 42.2 | 61.2 |
| + SFT | 70.2 | 62.3 | 43.4 | 58.6 | |
| + GRPO | 75.6 | 68.1 | 44.4 | 62.7 | |
| + OPSD | 76.4 | 68.3 | 46.1 | 63.6 | |
| ATESD | 78.06±0.43 | 71.39±0.48 | 47.50±0.89 | 65.65±1.04 | |
| Qwen3-8B | Base | 75.8 | 65.6 | 43.9 | 61.8 |
| + SFT | 72.3 | 64.2 | 42.9 | 59.8 | |
| + GRPO | 76.4 | 68.9 | 46.7 | 64.0 | |
| + OPSD | 77.8 | 70.8 | 45.8 | 64.8 | |
| ATESD | 80.56±0.70 | 72.50±0.32 | 48.33±0.28 | 67.13±0.32 |
几个值得讲的观察:
第一,提升随模型规模放大。 1.7B 上 +0.95,4B 上 +2.05,8B 上 +2.33——这个 scaling 趋势挺漂亮的。我的解读是大模型的"学习容量"更大,更容易被过强的教师分布"压住",所以调暴露的收益反而更高。如果这个趋势能外推到 32B / 70B,那就比现在的数字更有说服力了,但论文没做。
第二,SFT 在所有规模上都是负贡献。 这其实挺有意思——纯 SFT(监督微调)在 Qwen3 上反而比 base 还差,说明这套数据上简单 SFT 不再是默认正向操作。GRPO 和 OPSD 才是真正起作用的两条路。
第三,OPSD 和 ATESD 的差距比 OPSD 和 GRPO 的差距小。 比如 8B 上,GRPO → OPSD 涨了 0.8,OPSD → ATESD 涨了 2.33。说明 OPSD 这个范式本身的提升空间还在被进一步挖掘,ATESD 是在挖最后这块边际。这个定位要清楚——它不是颠覆性的新范式,是在 OPSD 这条线上做精细化优化。
第四,1.7B 上 HMMT 25 ATESD 反而比 OPSD 低 0.03。 论文没把这个数字加粗也没刻意回避,挺诚实。但反过来看,1.7B 上 +0.95 的 Average@12 提升,主要贡献来自 AIME 24 的 +1.97 和 AIME 25 的 +0.82——HMMT 25 是持平的。所以"小模型规模上 ATESD 提升边际不大"这个判断是确凿的。
五、消融实验:拆开看每个组件的功劳
ATESD 的消融做得比较精细,主要分两组——一组拆延迟信用,一组对比"学习的暴露"vs"固定的暴露"。
5.1 延迟信用是不是必要的?
| Reward 设计 | AIME 24 Average@12 |
|---|---|
| 即时单步反馈(one-step) | 52.22 |
| 短延迟信用 | 56.11 |
| 折扣前瞻(discounted lookahead) | 58.06 |
| 完整 ATESD(+ teacher-grounded 项) | 59.17 |
这个递进非常清晰。一个特别值得注意的点是:单步即时反馈(52.22)甚至比 OPSD baseline(57.20)还差了 5 个点。
这是什么意思?意思是没有延迟信用、强行让 controller 学的话,反而会破坏 OPSD。Controller 会去优化"立刻让 loss 降下来"的 \(\alpha\),但这些 \(\alpha\) 选择对后续学生改进毫无帮助,甚至会让学生过拟合短期信号。
只有引入了延迟反馈(56.11),controller 才开始往"对未来有帮助的方向"调,但还差 baseline。引入折扣前瞻(58.06),开始反超。加上 teacher-grounded 项防止 controller 偷懒(59.17),达到最优。
这一组消融把整个 ATESD 设计哲学的合理性立住了:这个问题不是"加一个超参 + 弱监督"就能解的,延迟信用是必需结构。
5.2 学到的策略 vs 固定/随机暴露
| 暴露策略 | AIME 24 Average@12 |
|---|---|
| OPSD(\(\alpha = 1.0\),全暴露) | 57.20 |
| 最优固定(\(\alpha = 0.5\),oracle 搜出来的) | 57.44 |
| 不可控随机暴露 | 54.94 |
| 学习到的策略(完整 ATESD) | 59.17 |
三个对比都很关键:
- 最优固定 \(\alpha = 0.5\) 只比 OPSD 涨了 0.24。这一组数据其实告诉我们:哪怕你拿 oracle 知道全局最优固定暴露是 0.5,跟 OPSD 也只是个小幅改进。真正的收益不在挑一个好暴露常数,而在动态调整。
- 不可控随机暴露反而掉了 2.26。这条很重要——它排除了"涨点是因为引入了噪声/数据增强效果"这条平凡解释。证明 ATESD 的提升来源不是单纯的随机性,是 feedback-driven 的自适应。
- 学习策略 +1.97 over 最优固定。这是 ATESD 相对于"暴力调超参"路线的真实增益。
下面这张 ablation 图把这个故事画得更直接:
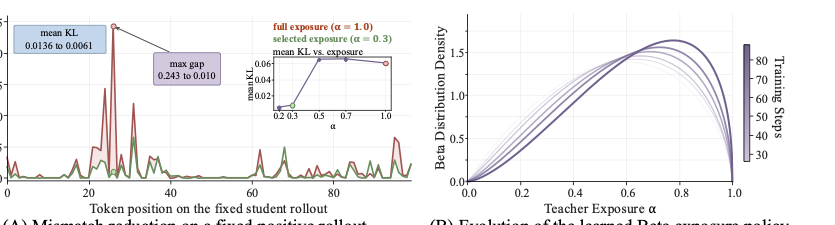
Panel A(左):固定 student rollout 和打分位置不变,只把 teacher exposure 从 \(\alpha = 1.0\) 改到 ATESD 学到的 \(\alpha = 0.3\)。在同一条正向轨迹上:
- mean KL:0.0136 → 0.0061
- max gap:0.243 → 0.010
- 位置 26 上的最大 spike:0.2432 → 0.0098
这是非常关键的诊断——在学生已经在做对的轨迹上,减少老师暴露能消除掉那些不必要的 KL 尖峰。学生已经走对了,老师还给一个超出能力的"理想化推理"作为目标,只会引入噪声。
Panel B(右):随训练步数演化的 Beta 分布密度。可以看到一个有意思的现象——Beta 分布从一开始的偏中性,逐渐演化到偏右(峰值大概在 0.7-0.8 附近),mass 始终在 \([0.2, 1.0]\) 的中间区域,没有坍缩到 \(\alpha = 0\) 或 \(\alpha = 1\) 任一边界。
我看到这张图的时候有点意外——直觉上我以为"训练后期学生变强,暴露可能往低走"(因为学生不需要太多帮助了);但论文学到的是反过来的趋势:随训练进展,暴露反而往高走。这其实有自己的逻辑:训练初期学生啥都不会,给太多信息反而 overload;训练后期学生有了基本能力,能消化更高暴露的信号。这跟 Vygotsky 的"最近发展区"理论里"教学应该略超前学生当前水平"的说法是一致的。
六、批判性看一下:哪些地方还不够稳
写到这里我其实是认可 ATESD 的方法论的,但作为一个老老实实读论文的读者,有几点不能不提:
1. 绝对提升幅度需要分规模看待
1.7B 上 +0.95 with std 0.23——这个显著性边界很紧,3 个 seed 的标准差还有概率覆盖到 OPSD 的最优 seed。4B 上的 +2.05 with std 1.04 也只能算 marginal。只有 8B 上的 +2.33 with std 0.32 才算稳。
所以这个工作的真实卖点其实是方法论上的新视角 + 大模型上稳定提升,而不是"全规模碾压"。论文的写法倒是没有夸大,主表也老老实实把所有数字都列出来了。
2. 只在数学竞赛上验证
AIME 和 HMMT 都是非常窄的 benchmark——题目结构、答题格式、推理长度都相对固定。代码生成、通用 QA、多轮对话、agentic reasoning 这些场景下,"教师暴露"这个旋钮是否同样有效?论文完全没碰。
我觉得这是 ATESD 现阶段最大的缺口。一个真正强势的工作应该至少在 LiveCodeBench、GPQA 或者 BBH 这些上面跑一下。论文的章节安排里也没有"More Benchmarks"或者"Beyond Math"之类的内容,说明他们自己也意识到这是窄域工作。
3. 引入了一堆新超参
ATESD 把"一个超参 \(\alpha\) 选什么"换成了:
- Hold window 长度 \(H\)
- 前瞻窗口长度 \(L\)
- 折扣因子 \(\gamma\)
- teacher-grounded 权重 \(\lambda_{\text{gt}}\)
- entropy bound \(\mathcal{H}_{\text{target}}\)
- Beta clip 上下界 \(\alpha_{\min}, \alpha_{\max}\)
- controller MLP 结构和状态维度
虽说每个都不算敏感,但工程上要把这套调起来比直接固定 \(\alpha = 0.5\) 麻烦多了。论文里也没看到对这些超参的鲁棒性分析。
4. 没有 per-sample 自适应
诊断实验 Panel C 明确证明了 easy/medium/hard 题目应该用不同 \(\alpha\),但 ATESD 当前的设计是对整个 batch 采一个全局 \(\alpha_t\)。论文自己在结尾也承认这点:"The current controller does not choose a separate \(\alpha\) for each example."
这个我觉得是未来工作里最有价值的方向之一——结合难度估计做 per-sample exposure,理论上还能再榨一波。
5. Controller 计算开销没有定量讨论
REINFORCE + 前瞻窗口意味着 controller 更新有延迟,且需要维护 \(H + L\) 步的历史信号。具体 training FLOPs 增加多少?wall-clock 慢多少?论文没数。
七、放到 OPSD 这条线上看:ATESD 是什么定位
最后回到一个更大的问题:ATESD 在 LLM 推理后训练这块儿处于什么位置?
我画一张快速的对比表:
| 维度 | RLHF / GRPO | SFT / Distillation | OPSD | ATESD |
|---|---|---|---|---|
| 学生数据 | on-policy | off-policy | on-policy | on-policy |
| 监督密度 | 稀疏(轨迹级) | 稠密(token 级) | 稠密 | 稠密 |
| 老师特权信息 | 无(RM 评分) | 完整解 | 完整推理 | 可调暴露 |
| 自适应粒度 | 无 | 无 | 无 | 训练状态级 |
| 信用分配 | 即时 / GAE | 即时 | 即时 | 延迟前瞻 |
| 新增超参 | 标准 RL | 几乎无 | 几乎无 | 较多 |
ATESD 不是颠覆 OPSD,而是在 OPSD 的设计空间里开了一个之前所有人都默认掉的新维度——教师侧的信息量调节。这跟过去 scheduled sampling、DAgger 那些"学生侧暴露"的工作是正交的,理论上两者可以叠加。
如果你问我"这工作对工程实践有什么启发",我大概会说:
- 如果你已经在跑 OPSD pipeline,ATESD 是一个值得尝试的精细化优化,特别是在 4B+ 规模上
- 但如果你刚开始搭蒸馏框架,先把 OPSD baseline 跑稳更重要
- 真正可以借鉴的是它的问题诊断方法——把一个被默认掉的设计选择拎出来,做受控扫描,再决定要不要做成可学习。这套思路在很多地方能复用
- 延迟信用 + REINFORCE 这套 controller 设计也挺通用,可以套到其他训练时控制变量上(learning rate schedule、loss 加权、curriculum 难度等)
八、收尾
读这篇论文给我最大的感触不是 ATESD 这个方法本身,而是作者对 OPSD 这套范式的批判性视角。教师每次都看完整答案这件事在 OPSD 出来之后被大家默认接受了一年多,没人去问:这是个最优选择吗?
ATESD 不光问了,还做了受控实验、给出了机制解释、设计了可学习的控制器。整套工作就是一个示范:怎么在一个看似成熟的范式里,找出未被审视的设计选择,然后用最小化改动把它升级为可学习变量。
绝对涨点不算炸裂,但思路扎实,工程也走通了。如果你在做 LLM 后训练,这篇值得看一遍——不一定要复现,但思考模式是真的有用。
下一步我个人最想看到的是:
- per-sample exposure(结合难度估计)
- 跨任务验证(code、general reasoning)
- 学生侧暴露和教师侧暴露的联合控制
任何一条做出来,都会比当前版本更有说服力。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新AI前沿,关注我