ActGuide-RL:把 SFT 冷启动换成"动作引导"的智能体 RL 新范式
写在前面
做过 Agentic RL 训练的人多半都有过这种崩溃时刻:模型在简单任务上能学,一到难任务,整组 rollout 全 0 分,advantage 直接归零,梯度啥也没有,loss 曲线躺平。
更让人无语的是,业内目前公认的解法只有一条——先做一轮 SFT 冷启动,再上 RL。问题是:SFT 数据要标注 reasoning trace、要蒸馏大模型、要做难度配平,整个流程比 RL 本身还重,换个领域、换个工具集就得从头做一遍。
阿里高德 AMAP 团队最近放出来的这篇 ActGuide-RL,提出了一个我看完之后觉得"对,就应该这么做"的思路:与其费劲做 SFT 冷启动,不如直接把人类日常产生的"动作数据"作为参考计划喂给模型,让它在踩不到 reward 的关卡上自己走过去。在 GAIA 上零冷启动比纯 RL 涨 10.68 个点,在 WebWalker 上涨 27.79 个点——更关键的是,性能跟"SFT 加 RL"两段式 pipeline 持平,但没有任何 SFT。
这篇我想认真聊聊,因为它触碰到了一个很底层的问题:Agentic RL 到底卡在哪?以及,凭什么动作数据可以替代 reasoning 数据?
论文信息
| 项目 | 内容 |
|---|---|
| 标题 | Learning Agentic Policy from Action Guidance |
| 作者 | Yuxiang Ji、Zengbin Wang、Yong Wang、Shidong Yang、Ziyu Ma、Guanhua Chen、Zonghua Sun、Liaoni Wu、Xiangxiang Chu |
| 机构 | 厦门大学 / AMAP(阿里高德) / 南方科技大学 |
| 提交日期 | 2026 年 5 月 12 日 |
| arXiv | 2605.12004 |
| 代码 | github.com/AMAP-ML/ActGuide-RL |
一个被低估的问题:可达性瓶颈
先抛个问题:为什么 RL 在难任务上学不动?
教科书答案是"reward 太稀疏"。但稀疏只是表象。真正的根因是论文里讲的"reachability barrier"——可达性瓶颈。
我用大白话翻译一下。Agentic RL 通常用 GRPO 这种 group-based 算法:同一个任务采 N 条轨迹,根据成功失败之间的对比算 advantage。这玩法的前提是,N 条里至少得有几条成功——这样 advantage 才不是 0。
但如果任务太难,N 条全失败呢?group advantage 集体归零,梯度归零,这一批数据完全没用。论文形式化地把这个现象描述成"effective state-visiting mass"在某个关键区间 \([b, b+m-1]\) 内崩溃:
其中 \(\bar{\kappa}_t^\pi\) 是单步可达性保留率。一旦某个短区间的累积 \(\bar{\kappa}\) 远小于 1,后续 rollout 就再也走不回有奖励的状态了。
这事关键在于"结构性失败"四个字。论文里讲得很硬气:这种失败不是采样不够,加大 N 也救不了。模型必须先被"推过"那道墙,才能学到任何东西。
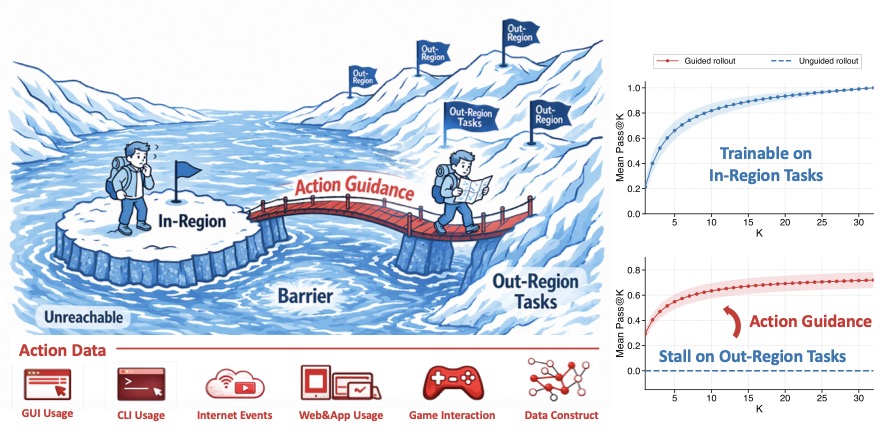
配图:左侧是论文标志性的冰川示意——基础策略只能在 in-region 区域内学习,out-region 任务被一道 barrier 隔开。ActGuide-RL 的核心做法是用 action data 搭一座桥,让策略走过去。右上图显示 in-region 任务的 unguided rollout 可以稳定提升 Pass@K,右下图显示 out-region 任务的 unguided rollout 始终停在 0,只有 guided rollout 能逐渐走出去。
这里我得停一下,吐槽一个常见的误解:很多人觉得 RL 比 SFT 强是因为 RL"能探索新行为"。这个说法在 in-region 任务上成立,但在 out-region 任务上彻底崩塌——你都到不了奖励状态,谈什么探索?这恰恰是 Yue 等人在 2025 年那篇 "Does RL Really Incentivize Reasoning" 里强调的:当前 RL 方法的能力天花板,其实被基座模型的可达性卡得死死的。
为什么不直接用 SFT 冷启动
正常的工业界做法是这样的:
第一步,标注或蒸馏一批带完整 reasoning trace 的高质量 SFT 数据。 第二步,用 SFT 把基础模型"暖"到能在难任务上偶尔成功。 第三步,再上 RL 微调。
这套流程跑得通,但代价不小:
- 标注成本高:reasoning trace 要么人工写,要么蒸馏教师模型。前者贵,后者要先有一个足够强的教师。
- 泛化性差:换个领域、换个工具集,SFT 数据得重做。
- out-of-domain 性能掉点:SFT 的 mode-covering 特性会让模型在域外任务上变差。这一点论文用 GPQA、TruthfulQA、IFEval 三个域外榜单的数据做了实证(后面会讲)。
那么有没有更便宜的"暖启动"信号?
论文的回答是:有,动作数据。
人类日常和电脑、手机的交互,本身就产出海量动作轨迹——GUI 点击、命令行操作、API 调用、长程游戏。这些数据的特点是:只有动作,没有 reasoning。过去之所以没人直接拿来训智能体,是因为缺 reasoning trace 这一环。要么硬塞一个合成的 chain-of-thought,要么做行为模仿——前者容易出现 post-hoc 合理化(事后编理由),后者学到表面行为模式,学不到推理能力。
ActGuide-RL 的切入点很巧妙:不去补 reasoning,而是把动作序列当作一个"参考计划"塞给模型,让模型自己在 RL 训练里把 reasoning 学出来。
ActGuide-RL 的三个核心设计
整个方法围绕三个问题展开:怎么引导?引导多少?怎么把引导的收益学回来?
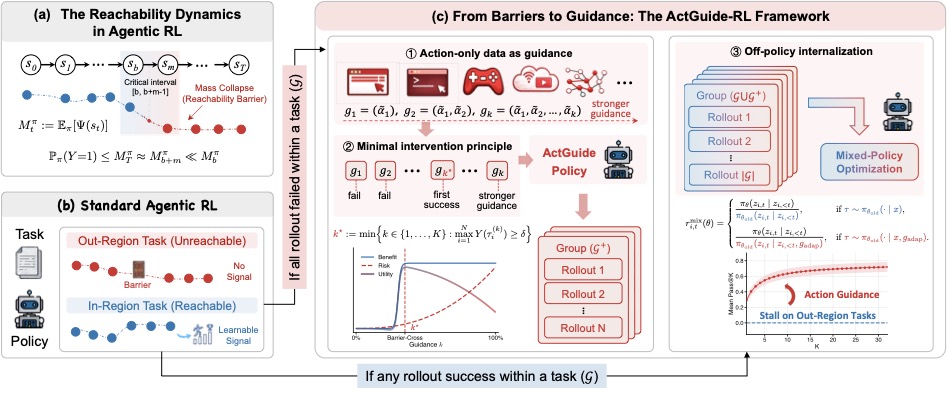
配图:左边 (a) 描述可达性动力学——状态访问质量在关键区间 \([b, b+m-1]\) 内坍塌,导致 \(M_T \approx M_{b+m} \ll M_b\)。左下 (b) 对比标准 Agentic RL——in-region 任务有可学信号,out-region 任务无信号。右边 (c) 是 ActGuide-RL 框架的三个模块:动作数据作为参考计划、最小干预原则下的自适应级别选择、guided 与 unguided rollout 的混合策略优化。
设计一:动作数据当"参考计划"
最直接的用法是把动作序列 \(g = (\tilde{\alpha}_1, ..., \tilde{\alpha}_L)\) 作为条件喂进策略:
注意一个细节——论文是把 \(g\) 作为 prompt 里的"未来参考动作列表"附加进去,不是强制模型按这个 prefix 生成。这个差别很重要。强制 prefix 等于行为模仿,模型学不到自己思考;非侵入式 reference 才能让模型把动作翻译成自己的 reasoning 过程。
那这种 reference 真的能修复 barrier 吗?作者做了一个我觉得设计得很漂亮的实证。沿着一条 guided rollout,每个步骤上同时算两个量:
- \(|\Delta\mathrm{Logit}|\):guided 策略和 unguided 策略的 token logit 差,衡量引导在这个位置上"改变"了多少决策;
- 前缀级 Pass@K:从当前 guided 状态出发,不再使用引导继续采样 K 条,看能不能恢复 reward。
理想情况下,如果引导真的"推过了"barrier,那么过完 barrier 的位置上,unguided Pass@K 应该从 0 跳上去。
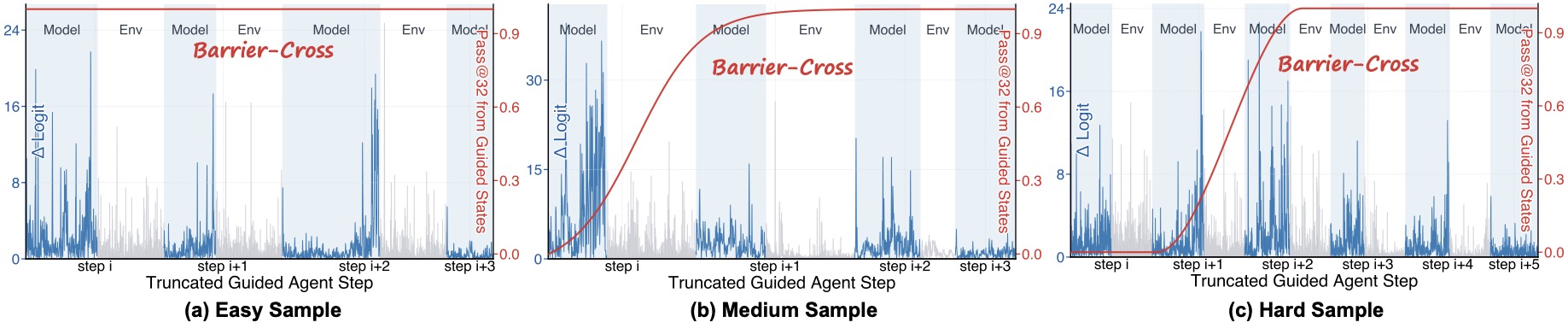
配图:蓝色柱状是 \(|\Delta\mathrm{Logit}|\),红色曲线是前缀级 Pass@32。(a) Easy sample 几乎从一开始就有非零 Pass@K,说明本来就 in-region;(b) Medium sample 前半段 Pass@K 是 0,在某个步骤之后跳到 0.9 以上,logit 差也在这附近骤增;(c) Hard sample 整条 rollout 几乎都在 0 附近徘徊,直到最后 step i+4、i+5 才跨过 barrier。
这张图我盯着看了一会儿。Easy 和 Hard 的对比尤其有意思——hard sample 的 barrier 不是某一步,而是分散在多个 step,每跨过一个就有一次 logit 跳变。说明 reachability barrier 不是单点墙,而是一系列断点的累加。
为了让引导有强度可调,作者把引导组织成一个递增族:
\(g_k\) 就是只给前 \(k\) 个参考动作。这给了"引导强度"一个单调参数,为下一步做铺垫。
设计二:最小干预原则
强引导一定好吗?我看到这里心里就咯噔一下——但凡做过 off-policy RL 的都知道,分布漂移太大会让 importance sampling 直接爆炸。
论文用 cumulative token-level log-ratio shift 来度量漂移:
对应的 off-policy 风险就是这个 shift 的方差 \(R_k\)。
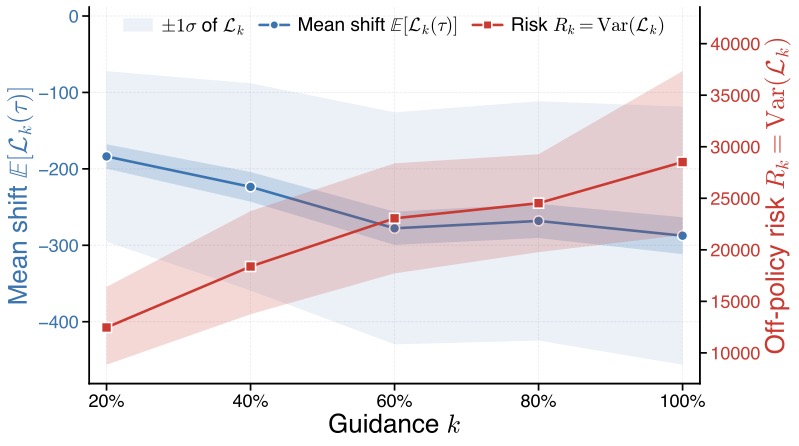
配图:横轴是引导比例 \(k\)(20% 到 100%),蓝线是 mean log-ratio shift(左轴),红线是 off-policy 风险 \(R_k\)(右轴)。可以看到红线随 \(k\) 单调上升,蓝线在 \(k=60%\) 之后基本饱和。
这张图很关键。红线一路上升,蓝线 60% 之后趋平——说明引导收益在某个点之后饱和,但风险还在涨。这是典型的边际收益递减加风险递增。
基于这个观察,作者抛出了最小干预原则:每个任务用恰好够用的最小引导级别。形式化地说,目标是近似最大化:
其中 \(B_k\) 是 barrier-repair benefit,\(R_k\) 是 off-policy 风险。
关键在于 \(B_k\) 在二值奖励下呈现"阈值行为"——在 barrier 没被跨过之前几乎是 0,跨过之后跳到很高。\(R_k\) 则单调递增。所以 \(J_k\) 的峰值就在"刚好够跨过 barrier 的那个最小 \(k^\star\)"。
实操上怎么找 \(k^\star\)?作者用了一个非常实在的二分查找:
而且——这里是我觉得最聪明的设计——引导只在 fallback 时触发。每个任务先采 N 条 unguided rollout,如果有成功的就直接用,根本不引导。只有整组全 0 才启动二分查找去找最小够用的 \(k^\star\)。
这样做的好处:
- in-region 任务完全不引入分布漂移,等价于纯 RL;
- out-region 任务才付出代价,且代价被压到最小。
我个人觉得这个 fallback 机制是整篇论文最被低估的设计。它把"何时引导"和"引导多少"两个问题一起解了,而且解得非常自然。
设计三:混合策略优化
引导只在训练时有,推理时模型必须能独立工作。所以 guided rollout 拿到的 reward 必须被"转化"回 unguided 策略上。
由于 guided 和 unguided 策略共享参数,guided rollout 可以视为相对 \(\pi_\theta(\cdot \mid x)\) 的 off-policy 数据。论文的混合目标是:
token 级 importance ratio 根据 rollout 来源自适应:
- unguided rollout 用标准 ratio \(\frac{\pi_\theta(z)}{\pi_{\theta_{\rm old}}(z)}\);
- guided rollout 的分母换成 guided 分布 \(\frac{\pi_\theta(z)}{\pi_{\theta_{\rm old}}(z \mid g_{\rm adap})}\)。
这样 guided 探索的 credit 就被 importance weight 转移回了无引导目标。
相比之前 off-policy RL 那些 ratio shaping 的复杂技巧(Yan et al. 2025、Nath et al. 2025),ActGuide-RL 保持目标函数不变——理由是最小干预已经把分布漂移压住了,PPO 的 min-clip 足够稳定。这里我是真的觉得设计得很克制,能不加的复杂度坚决不加。
实验:在 Qwen3-4B 上的爆炸式提升
四个 search-agent 榜单:GAIA(通用 AI 助理任务,分 Lv.1/2/3)、WebWalkerQA(多步网页推理)、XBench、BrowseComp-ZH。基础模型覆盖 Qwen2.5-3B、Qwen2.5-7B、Qwen3-4B、Qwen3-8B 四个不同能力档位。
主表关键数据
| 模型 | 方法 | GAIA Avg | WebWalker Avg | XBench | BC-ZH |
|---|---|---|---|---|---|
| Qwen2.5-3B | RL | 11.65 | 15.29 | 10.00 | 2.42 |
| Qwen2.5-3B | ActGuide-RL | 18.45 | 18.82 | 16.00 | 4.50 |
| Qwen2.5-7B | RL | 11.65 | 18.67 | 22.00 | 4.84 |
| Qwen2.5-7B | ActGuide-RL | 25.24 | 22.05 | 24.00 | 8.31 |
| Qwen3-4B | RL | 25.24 | 12.06 | 18.00 | 15.26 |
| Qwen3-4B | ActGuide-RL | 35.92 | 39.85 | 37.00 | 20.41 |
| Qwen3-8B | RL | 36.89 | 42.50 | 33.00 | 21.79 |
| Qwen3-8B | ActGuide-RL | 41.74 | 46.77 | 44.00 | 26.64 |
最炸的是 Qwen3-4B:WebWalker 从 12.06 涨到 39.85,跨越式提升。XBench 从 18 涨到 37,几乎翻倍。GAIA 涨了 10.68 个点,BC-ZH 涨了 5.15 个点。
为什么 Qwen3-4B 的提升最夸张?我猜是因为它正好处在"基础能力够推理但不够探索"的甜蜜点——in-region 太小,RL 学不动;但只要一点引导就能跨过 barrier。Qwen3-8B 本身 in-region 就大,提升空间被压缩;Qwen2.5-3B/7B 则可能基座能力本身偏弱,引导也只能救一部分。
还有一个细节我得点出来:Qwen2.5-7B 在 GAIA 上"RL"反而比基础模型差了 10 个点(22.32 → 11.65)。这就是论文讲的"in-region RL capability regression"——训练数据难度和基础能力不匹配时,纯 RL 会在容易任务上"忘记"原有能力。ActGuide-RL 通过引导让难任务有训练信号,反而修复了这种退化。
SFT 加 RL pipeline 的对比
| 方法 | GAIA | WebWalker | XBench | BC-ZH | GPQA-CoT | TruthQA | IFEval |
|---|---|---|---|---|---|---|---|
| ZeroRL | 25.24 | 12.06 | 18.00 | 15.26 | 35.45 | 62.17 | 81.33 |
| ZeroRL + ActGuide | 35.92 | 39.85 | 37.00 | 20.41 | 36.93 | 62.30 | 82.99 |
| SFT | 34.95 | 31.18 | 25.00 | 25.61 | 29.15 | 56.95 | 77.82 |
| SFT + RL | 36.89 | 32.20 | 17.00 | 26.30 | 29.85 | 57.02 | 76.34 |
| SFT + RL + ActGuide | 40.77 | 37.06 | 25.00 | 28.02 | 29.57 | 57.11 | 77.43 |
这张表是论文最有杀伤力的论据。看几个关键点:
- 零冷启动 ActGuide-RL 在 in-domain 三个榜单上和 SFT 加 RL 持平甚至超过:GAIA 35.92 vs 36.89(基本打平),WebWalker 39.85 vs 32.20(反超 7.65 点),XBench 37.00 vs 17.00(碾压)。
- SFT 在域外榜单上明显掉点:GPQA-CoT 从 35.45 跌到 29.15,TruthQA 从 62.17 跌到 56.95,IFEval 从 81.33 跌到 77.82。这是 SFT 的典型 mode-covering 副作用——把模型过拟合到 SFT 数据的分布上,丢了通用能力。
- ActGuide-RL 在域外榜单上没有这种掉点,反而略有提升。
我看到 SFT 在 IFEval 上从 81.33 跌到 77.82 的时候停了一下。这个掉点其实挺要命的——IFEval 测的是指令遵循能力,是个非常底层的能力,SFT 把它都搞掉了。这说明现行 SFT 加 RL pipeline 的代价比我们想象的还大。
消融与引导强度
| 方法 | GAIA | WebWalker | XBench |
|---|---|---|---|
| ActGuide-RL(完整版) | 35.92 | 39.85 | 37.00 |
| 去掉 Minimal-Intervention(Adaptive) | 27.18 | 35.00 | 34.00 |
| 去掉 Minimal-Intervention(Fallback) | 24.27 | 23.82 | 19.00 |
| 去掉 Mixed-Policy Optimization | 22.32 | 21.76 | 21.00 |
三个组件去掉任何一个都掉很多。其中"去掉 Fallback"和"去掉 Mixed-Policy"掉得最狠——XBench 从 37 掉到 19/21,几乎掉一半。这两个组件刚好对应"何时引导"和"如何把引导收益学回来",是 ActGuide-RL 的命脉。
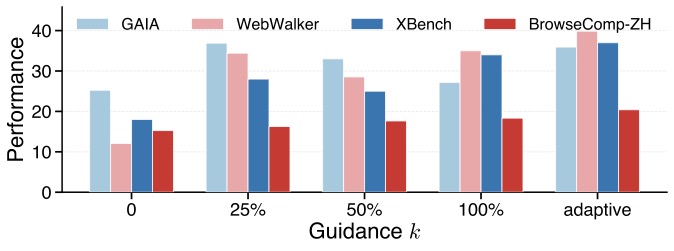
配图:横轴是固定引导比例(0%、25%、50%、100%)和自适应(adaptive)。可以看到 25% 和 50% 比 100% 略好(引导太多确实有害),但 adaptive 在大部分榜单上都是最高。
这张图证实了"最小干预"的核心论断:引导既不是越多越好,也不是越少越好,关键是"按任务难度自适应"。100% 引导(全部参考动作都给)在 XBench 上反而最差,因为引发了过度 off-policy。
噪声敏感性
考虑到实际收集动作数据时不可避免会有"无意义动作"——比如人类在做任务时手滑、回头、试错——作者还测了噪声比例的影响:
| 噪声比例 | GAIA | WebWalker | XBench | BC-ZH |
|---|---|---|---|---|
| 0% | 35.92 | 39.85 | 37.00 | 20.41 |
| 10% | 39.81 | 39.26 | 38.00 | 19.03 |
| 20% | 29.12 | 37.94 | 35.00 | 17.64 |
10% 噪声居然在 GAIA 上反而最好——这事让我有点意外。我的猜测是少量噪声起到了类似 dropout 的正则化作用,逼模型不能完全照抄引导。但 20% 噪声明显伤害性能,所以数据质量还是有底线的。
训练动态:可学样本比例的对比
论文还跟踪了一个我觉得非常有说服力的指标——训练过程中"产生有效学习信号的 rollout 组"的比例。简单说,就是 group advantage 不全为 0 的比例。
baseline 在很多 step 上这个比例只有 0.4 到 0.7,意味着将近一半的 batch 是"白跑"——采了 N 条轨迹,结果 advantage 全 0,梯度等于浪费算力。ActGuide-RL 因为有 fallback 引导,几乎稳定在 0.95 以上,意味着每个 batch 都能贡献梯度信号。
这事翻译成工程语言就是:在固定算力预算下,ActGuide-RL 的"有效训练数据吞吐"是 baseline 的近两倍。如果你算单位算力的样本利用率,这个优势会进一步放大 RL 训练效率的差距。
交互轮数与响应长度的演化
另一个有意思的现象:Qwen3-4B 在 zero RL 设定下,训练过程中平均交互轮数和响应长度是缓慢上涨的;而 ActGuide-RL 让这两个指标快速上涨。
这对应一个工程直觉——多步推理能力是"练"出来的。一个 4B 小模型本来不太会拆解任务、不会调用工具,但如果它能不断从"成功的多轮交互"中得到反馈,它就会逐渐学会多步交互。引导数据提供的就是这种"成功多步交互"的脚手架。
为了验证这种能力是真的,作者做了一个 turn budget 的扫描:
| 交互轮数上限 | GAIA | WebWalker | XBench | BC-ZH |
|---|---|---|---|---|
| 2 | 0.97 | 9.26 | 5.00 | 1.04 |
| 4 | 18.44 | 33.97 | 33.00 | 4.84 |
| 8 | 19.41 | 35.00 | 33.00 | 16.96 |
| 16 | 27.18 | 37.55 | 35.00 | 17.99 |
| 32 | 35.92 | 39.85 | 37.00 | 20.41 |
ActGuide-RL 训出的模型在 turn budget 越大时性能越好,说明模型真的学会了"用更多轮交互换更高成功率"。turn=2 的时候 GAIA 只有 0.97(连基础任务都做不完),turn=32 时跳到 35.92——这种单调上升曲线,是模型真正掌握长程交互能力的标志。如果模型只是模式匹配,多给轮数也不会涨。
我对这篇论文的判断
亮点很硬:
第一,问题诊断准确。把"RL 难任务学不动"形式化成 reachability barrier 这件事,比单纯讲"reward 太稀疏"深一层。barrier 是结构性的,加大 N 解决不了,这个观察对整个领域都有价值。
第二,方案设计克制。最小干预原则 + fallback 触发 + 二分查找最小 \(k^\star\) 这三件事拼在一起,把"引导"这件事的代价压到了最低。我尤其欣赏 fallback 这一刀——在 in-region 任务上完全不引入任何 off-policy,等于免费午餐。
第三,混合策略优化的目标函数没有花活。没有 ratio shaping、没有额外的 variance reduction,就是标准 PPO 加上 ratio 自适应。能不加的复杂度坚决不加,这种克制在当下 RL 论文里挺少见的。
第四,对 SFT 加 RL 范式的挑战是实打实的。在 in-domain 上持平,在 out-of-domain 上还更好。如果这个结果能在更多领域复现,agentic RL 的工作流可能真的要重写。
但也有几个地方让我皱眉:
第一,只在 search-agent 这一种 stateless 设定上验证。Search-agent 的好处是动作空间简单(就 web-search 和 web-visit 两个工具),而且 stateless 意味着每一步的动作可以独立解释。但对于 GUI、CLI、复杂多工具调用这种 stateful 场景,动作之间的依赖更强,参考计划可能没这么容易"翻译成 reasoning"。我希望看到更多场景的复现。
第二,"最小干预原则"的二分查找是有计算代价的。每次 fallback 都要再采几次 rollout 来定位 \(k^\star\),论文里给的 budget 是 \(B\),但具体到训练吞吐上影响多大没明确给。如果一个 batch 里 50% 任务都触发 fallback,训练速度可能掉一半。
第三,动作数据的来源问题没有充分讨论。论文用的是 Tongyi-DeepResearch 蒸馏出来的动作轨迹,说到底还是依赖一个强的"教师代理"。如果动作数据来自真实人类交互(论文一直暗示这是终极目标),噪声会比 20% 更大、动作会更不结构化,能不能复现这个效果是个开放问题。
第四,跟同期工作的对比可以更充分。论文里 baseline 主要对比 vanilla GRPO 和 SFT 加 RL,但 2025 年下半年其实出过几个"用 expert demo 引导 RL"的工作,比如 LMM-R1 的引导式探索、ARPO 的轨迹增强等。这些工作的核心思想跟 ActGuide-RL 有相似之处,论文里没有正面对比,这一点我觉得可以更严谨些。
工程上的启发
如果你在做 agentic RL 训练,这篇论文有几个直接可以借鉴的点:
先在 in-region 任务上 RL,难任务才上引导。不要一上来就给所有任务塞引导,那是浪费分布漂移预算。
引导以"参考计划"而非"强制 prefix"形式注入。让模型自己消化动作,而不是照抄。这是动作数据能转化成 reasoning 的关键。
Importance ratio 要根据 rollout 来源切换。混合策略训练里,guided rollout 的分母必须用 guided 分布,否则梯度方向就是错的。
如果你有动作数据(GUI 录屏、CLI 历史、API 调用日志),别浪费。即使没有 reasoning trace,单纯的动作序列也能撑起一个 agentic RL 的训练流程。这一点对工业界的意义非常大——动作数据的获取成本远低于 reasoning 标注。
收尾
我觉得 ActGuide-RL 真正动人的地方,不在那几个涨点数字,而在它指出了一个之前被忽略的方向:agentic 能力的训练信号,不必非要是 reasoning trace。
过去两年大家围着 chain-of-thought 转,所有 SFT 数据都在卷推理过程的质量。但 agent 干的事是"行动",而不是"想"。人类教徒弟也不是先讲一万遍道理,而是先示范一遍动作,让徒弟自己摸索为什么这么做。
这套思路如果在 GUI agent、code agent、tool-using agent 上都能复现,那 agentic post-training 的工作流可能要从"SFT 加 RL"变成"action guidance RL",整个工业界的标注成本会降一个量级。
当然,这都建立在论文结论能泛化的前提下。Search-agent 是个相对友好的场景,更复杂的 stateful 任务里 reachability barrier 长什么样、最小干预是不是还成立,都需要后续工作来验证。但这个方向我会持续盯着。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新 AI 前沿,关注我