Agent 轨迹的"监督盲区":把多轮工具调用编译成长上下文训练数据,30B 干到 235B
核心摘要
最近一直在琢磨一个事:Agent 时代大家都在跑长上下文,但真正高质量的长上下文 SFT 数据从哪来?人工标注一篇带证据高亮的长文档贵到离谱,启发式拼接的"伪长文"又缺乏真实任务里那种七拐八绕的依赖关系。
ACC 这篇论文的切入点很妙——它没去造数据,而是回头审视了所有人都习以为常的 agent SFT 流程:你训 agent 的时候,工具响应(observation)是被 mask 掉的,模型只学"下一步该调什么工具",那些跨越十几轮才能拼出答案的散落证据,对训练目标根本是不可见的。作者把这个叫 supervision blind spot(监督盲区)。
解法朴素到让人怀疑这都能 work:把 agent 跑过的轨迹(搜索、SWE、SQL)里所有工具响应编译成一个长上下文,问题不变,答案不变,但模型这次必须直接从拼出来的长上下文里读出答案——工具调用这一层被拆掉了,原本被 mask 的证据 token 全部进入监督。
效果是 Qwen3-30B-A3B 上 MRCR 涨了 18.1 个点、GraphWalks 涨 7.6 个点,追平 Qwen3-235B-A22B——激活参数差着 8 倍。说实话看到这数我愣了一下。这篇论文我觉得最值钱的不是这个数,而是它指出了一个所有 agent SFT 玩家都在浪费的资源:你跑 agent 验证集那一堆通过的轨迹,扔了实在可惜。
论文信息
- 标题:ACC: Compiling Agent Trajectories for Long-Context Training
- 作者:Qisheng Su, Zhen Fang, Shiting Huang, Yu Zeng, Yiming Zhao, Kou Shi, Ziao Zhang, Lin Chen, Zehui Chen, Lijun Wu, Feng Zhao
- 发表:arXiv 2605.21850(2026-05-21)
- 链接:https://arxiv.org/abs/2605.21850
- 基础模型:Qwen3-30B-A3B-Thinking(MoE,激活 3B)
一、为什么要折腾这个?从一个被忽略的训练损失说起
先别急着看方法,我想先聊清楚这篇论文真正在攻击的痛点。
如果你做过 agent SFT,你的训练数据大概长这样:
q 是问题,每个回合 t 包含三件东西:reasoning r_t、action a_t、tool response(observation)o_t,最后一轮给出答案 y。
标准做法很清晰:只在模型生成的 token(reasoning 和 action)上算 loss,工具响应 o_t 全部 mask 掉。理由也很合理——o_t 是工具/环境给的,不是模型生成的,让模型去拟合这些 token 没意义。
听起来天经地义对吧?但作者把这个 loss 拆开看了一眼:
前 k-1 项是局部的——每一步只监督"在当前历史下选什么工具"。问题来了:考虑某一轮 t 中的工具响应 o_t,它本身被 mask,只能通过下一轮 a_{t+1} 那条路径间接拿到梯度。也就是说,对 o_t 来说,最强的监督信号是"我这条信息怎么帮模型决定下一步调什么工具"。
那 o_t 跟最终答案 y 的关系呢?理论上梯度需要从 y 一路反向传播,穿过 t+1, t+2, ..., k-1 一连串中间回合才能到达 o_t,信号在这条长链里被严重稀释。
作者把这个叫 supervision filter——中间的每一回合都像一个过滤器,让"答案相关、但跟下一步工具调用无关"的特征几乎拿不到梯度。
这就是关键。
举个具象的例子。Search agent 第 2 轮搜出来一个文档 D,里面同时包含答案需要的证据 A 和帮助下一步搜索的关键词 K。现在 agent SFT 的梯度会让模型重点编码 K(因为下一步要用),而 A——那个真正帮你做出最终判断的信息——就那么静悄悄地溜走了。
我之前在做 RAG 链路质量分析的时候碰到过类似的现象:明明文档里证据写得清清楚楚,模型答错了。回头一查训练数据,发现训练目标根本没强迫模型学会"从文档堆里精准定位答案",模型只是学会了"看到这种文档就调下一步搜索"。读到 ACC 这段分析的时候我一下子就被点到了——这事儿真不是个孤立现象。
二、ACC 的核心思路:把多轮拍扁成一轮
理解了痛点,方法就直白得有点过分。
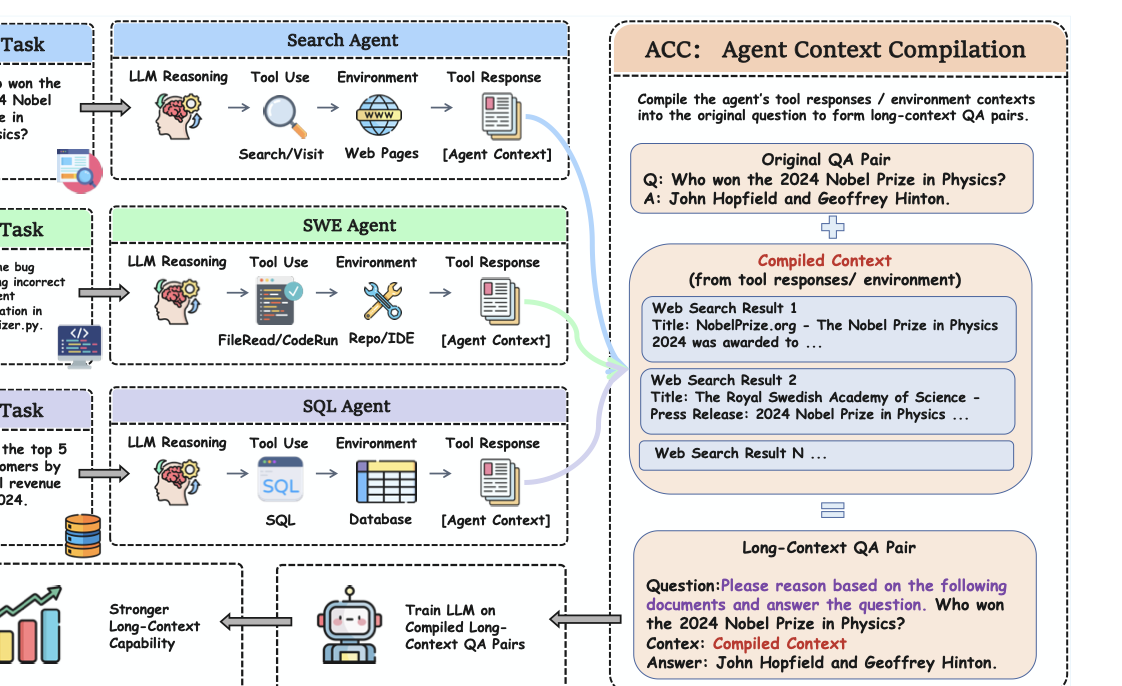
图1:ACC 整体框架。把 agent 三类轨迹(搜索、SWE、SQL)的工具响应 + 环境上下文打包成一个长上下文 QA 对,模型要从这堆"散落证据"里直接答题,工具调用层被整个拆掉。
ACC 的训练目标就一行:
跟原版 agent loss 比,没有中间 action 项了。模型直接面对"问题 q + 编译后的长上下文 C",写出一段推理 r,给出答案 y。原本被 mask 的工具响应,现在作为输入 context 的一部分,最终答案的监督信号可以直接抵达每一个证据 token,不用穿过那条衰减严重的长链。
工具调用这层"过滤器"被整个拆掉了。
具体到三类 agent,编译策略略有不同:
| Agent 类型 | 编译进 C 的内容 | Distractor(干扰项) |
|---|---|---|
| Search | 实际访问过的网页全文 | 搜出来但没访问的候选结果 |
| SWE | 正确 patch 涉及的源文件 | 调试时看过的其他文件 |
| SQL | 轨迹中查询过的所有表的完整内容 | (无,SQL 表本身就有结构性) |
注意 distractor 这个设计——不是噪声越多越好,是"看起来相关但不是答案"的内容。这个细节后面消融实验会专门聊。
还有一个工程细节挺关键:对证据片段做随机置换。
π 是个随机排列,B 是 token 预算。为啥要打乱?因为如果按时间顺序拼,模型可能学到"答案大概率在最后几个证据里"这种位置 shortcut。打乱之后强迫模型靠语义关联去定位证据,这是长上下文推理的核心能力。
Reasoning trace 怎么来?
有个细节挺务实。Agent 轨迹里只有最终答案 y,没有那段从 long context 直接出发的推理过程 r——毕竟原 agent 是边搜边想,不是一上来就面对全部证据。
作者的处理:用 DeepSeek-V3.2-Thinking 给每条编译好的 (q, C) 生成候选 reasoning,只保留那些最终能推出正确答案 y 的。这个步骤的 pass rate 也挺有意思:
- Search:≈ 100%
- SQL:≈ 50%
- SWE:≈ 10%
SWE 任务只有 1/10 通过率,意味着 90% 的 SWE 长上下文,连 V3.2 都没法直接读出正确答案。这从侧面说明 SWE 的长程依赖比另两类难得多——也是后面消融里 SWE 单独跑效果不太好的伏笔。
三、训练数据长啥样?
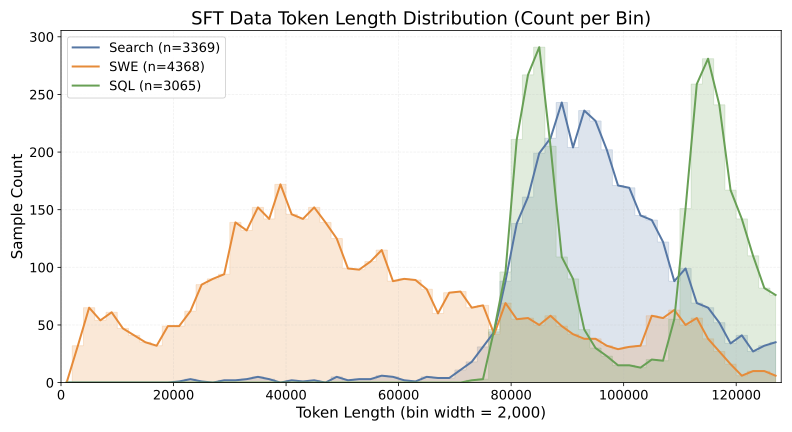
图2:三类 agent 编译出的训练样本 token 长度分布。Search 主要落在中等长度(多页面拼接但每页不大),SWE 偏向更长尾(源文件本身就大),SQL 跨度最广(取决于查询的表规模)。三类组合起来覆盖了 2K-128K 整个区间,这种"天然的长度多样性"是 ACC 能 work 的关键之一。
数据规模也不大:总共 10,802 条(Search 3,369 + SWE 4,368 + SQL 3,065)。说实话这数据量在 SFT 里算偏少的——10K 量级出来的效果,对比那些动辄百万级长文档训练,性价比挺扎眼的。
训练配置也没什么花活:
| 参数 | 值 |
|---|---|
| 序列长度 | 131,072 tokens |
| Global batch size | 16 |
| Learning rate | 1e-5(min 1e-6),cosine + 5% warmup |
| Optimizer | AdamW(β₁=0.9, β₂=0.999, wd=0.1) |
| Sequence parallelism | 8 |
| Epochs | 4 |
就是个标准 SFT 配方,没有 RL,没有 curriculum,没有花哨的 loss 设计。这一点其实挺重要——它不是赢在训练技巧,是赢在数据视角的转变。
四、主结果:30B 追平 235B,差点没绷住
直接上长程依赖建模的主表(avg@3):
| Model | MRCR 2-needle | 4-needle | MRCR Overall | GraphWalks Parents | BFS | GraphWalks Overall |
|---|---|---|---|---|---|---|
| Qwen3-30B-A3B-Thinking(基线) | 61.84 | 38.41 | 50.19 | 71.19 | 68.47 | 69.92 |
| + ACC(本文) | 76.90 | 59.57 | 68.28(+18.09) | 81.50 | 72.95 | 77.51(+7.59) |
| Qwen3-235B-A22B-Thinking | 74.98 | 59.96 | 67.51 | 78.53 | 74.45 | 76.63 |
| GPT-OSS-120B | 46.72 | 29.16 | 38.00 | 75.92 | 61.82 | 69.34 |
| DeepSeek-V3.2-Thinking | 81.60 | 60.32 | 71.01 | 89.87 | 80.26 | 85.39 |
| GPT-5.1-Thinking | 73.75 | 47.93 | 60.91 | 81.41 | 29.41 | 57.14 |
| GLM-4.6-Thinking | 73.63 | 55.33 | 64.53 | 80.29 | 77.41 | 78.95 |
| Kimi-K2-Thinking | 68.01 | 47.96 | 58.05 | 84.34 | 75.17 | 80.04 |
几个我觉得有意思的点:
第一,30B 追平 235B 这个数字含金量怎么样? Qwen3-235B-A22B 激活参数是 22B,30B-A3B 激活只有 3B——差了 8 倍。MRCR 上 ACC 版甚至略高于 235B(68.28 vs 67.51),GraphWalks 也基本打平(77.51 vs 76.63)。这两个 benchmark 本身就是 GPT-4.1 团队设计来专门测长程依赖的,不是那种容易刷的小学生题,这个对比挺能说明问题。
第二,DeepSeek-V3.2-Thinking 还是真的强。MRCR 71.01、GraphWalks 85.39 这两个数仍然是表里最高的——别忘了,ACC 的 reasoning trace 就是用 V3.2-Thinking 蒸出来的。所以说到底,ACC 跑出来的 30B 是在追 V3.2 的"上限投影",能追到 7-8 成已经很可以了。这个事作者没刻意藏着,但表里也没明说,需要读 method section 才能拼起来。
第三,GPT-5.1-Thinking 在 GraphWalks BFS 上只有 29.41,这个数我反复看了三遍。Parents 子任务还有 81.41,BFS 直接崩了。说明哪怕是闭源最强模型,长程图遍历这种"严格按规则跳节点"的任务也不是稳赢的。GraphWalks 这个 benchmark 比看起来要狠。
第四,GPT-OSS-120B 的 38.00 有个脚注说是"harmony format 解析失败"导致的——这种细节不可忽视。评测一个开源 baseline 的时候,推理框架的格式兼容性可能直接抹杀模型的真实能力。读论文表格永远要看脚注。
通用能力会被搞坏吗?
长上下文 SFT 最怕的就是 negative transfer——专项练过头,通用能力崩。作者专门测了一下:
| Benchmark | Qwen3-30B-A3B-Thinking | + ACC |
|---|---|---|
| GPQA-Diamond | 67.71 | 70.20(+2.49) |
| MMLU-Pro | 74.50 | 76.00(+1.50) |
| AIME'24 | 90.00 | 90.00(持平) |
| AIME'25 | 86.67 | 90.00(+3.33) |
| IFEval | 86.69 | 86.14(−0.55) |
通用能力不仅没退化,还小幅涨了。这个挺反直觉的——专门训长上下文,怎么数学和知识题也能涨?我觉得有两个可能:一是 ACC 的 reasoning trace 来自 V3.2-Thinking,这本身就是通用能力强的"标注员";二是长上下文里"从大量信息中抓核心"这件事,跟通用推理能力本来就是相通的。
五、是不是数据泄露在背后偷偷加分?
涨点这么明显,研究者的本能是去查数据污染。作者把 Search/SWE/SQL 三类训练 query(剥掉文档/代码/表的纯问题文本)和评测题做了 UMAP:
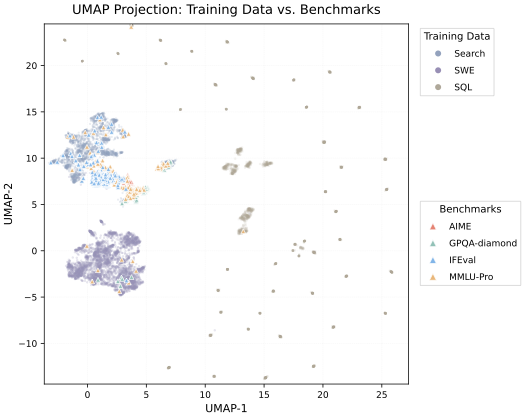
图3:训练 query(Search/SWE/SQL)与评测题的二维 UMAP。Search 因为是从 Wikipedia 合成的多跳问题,话题词跟 GPQA、MMLU-Pro 这类知识题天然有重叠;SWE 和 SQL 单独成簇。这是话题级重叠,不是题目级重复。
| Benchmark | NN Sim. | Center Dist. |
|---|---|---|
| AIME | 0.2832 | 0.8701 |
| GPQA-Diamond | 0.3557 | 0.7150 |
| MMLU-Pro | 0.3216 | 0.7685 |
| IFEval | 0.3425 | 0.9216 |
最近邻余弦相似度都在 0.36 以下,线性分类器分训练 vs 评测的 AUC 高达 0.9986——也就是说一个非常简单的分类器都能轻松把两者区分开。
这个数怎么读?AUC 0.9986 意味着训练分布和评测分布几乎是线性可分的,说明它们在向量空间里就是两堆不同的东西。涨点不是因为见过题,而是长程推理能力本身的迁移。
我个人对这个 decontamination 分析的态度是——它是个必要的健全性检查(sanity check),但还不够强。理想的对照实验是把训练数据里跟某个 benchmark 主题最像的那批样本去掉,看看分数会不会掉。不过 SFT 论文里能做到这一步的不多,作者放了 UMAP + AUC 已经算尽心。
六、消融实验:哪些设计真的重要?
这部分我觉得才是论文最硬的部分。先看 agent 类型 + distractor 的双重消融:
| 训练数据 | MRCR | GraphWalks |
|---|---|---|
| 基线(Qwen3-30B-A3B-Thinking) | 50.19 | 69.92 |
| + Search(标准 agent SFT,o_t 被 mask) | 42.16(−8.03) | 57.87(−12.05) |
| + Search(ACC,带 distractor) | 58.33(+8.14) | 44.75(−25.17) |
| + Search(ACC,无 distractor) | 54.99(+4.80) | 58.46(−11.46) |
| + SWE(带 distractor) | 54.82(+4.63) | 50.66(−19.26) |
| + SWE(无 distractor) | 51.01(+0.82) | 52.88(−17.04) |
| + SQL | 56.44(+6.25) | 75.50(+5.58) |
| + ACC 全量(Search+SWE+SQL) | 68.28(+18.09) | 77.51(+7.59) |
这张表里能挖出来的洞察非常多。
洞察一:直接拿 Search 轨迹做标准 agent SFT,反而比基线还差 8 个点。
这条最关键——直接论证了 supervision blind spot 的存在。同样的数据,只是改变了监督方式(o_t mask vs 不 mask 当成 input),效果天差地别。"agent SFT 训出来的模型不擅长长上下文"这个结论在这表里被钉死了。
洞察二:Search 单独跑,MRCR 涨但 GraphWalks 暴跌 25 个点。
这个反直觉。Search 的长上下文不是应该泛化到各种长程任务吗?作者的解释是:Search 编译出来的是长篇连续段落(网页文本),适合训练 cross-turn coreference(MRCR 测的就是这个),但对 GraphWalks 那种"严格按图结构跳节点"的离散关系推理没什么帮助。
洞察三:SQL 单独跑,GraphWalks 反而是唯一涨点的(+5.58)。
这个也很自然——SQL 表本身就是关系型结构,行与行、表与表之间天然就有"图遍历"的味道。这印证了 ACC 的一个隐含假设:不同 agent 类型的轨迹,提供的不是同质数据,而是不同结构的长程依赖。
洞察四:distractor 在 MRCR 上是必需的(去掉就掉 3-4 个点),但在 GraphWalks 单 agent 上反而是负担。
这是个对实操有指导意义的细节。Search/SWE 的 distractor 跟 query 语义不相关,对"在长 context 里精确定位证据"是好的训练信号(MRCR 涨点)。但 GraphWalks 测的是图遍历,distractor 反而干扰节点关系的学习。好消息是混合训练后这个矛盾被消解了——SQL 提供图结构能力,distractor 提供噪声鲁棒性,两边互补。
这种"单看每个组件有缺陷,混合后正好互补"的现象,是 ACC 这套数据组合最有意思的地方。
七、ACC vs 其他长上下文方法
作者还做了一个跟现有长上下文 post-training 方法的对比:
| Model | MRCR | GraphWalks |
|---|---|---|
| Qwen3-30B-A3B-Thinking | 50.19 | 69.92 |
| QwenLong-L1.5-30B(多阶段+RL) | 92.30 | 73.85 |
| Qwen2.5-7B-LongRLVR | 19.76 | 15.72 |
| Qwen2.5-14B-LongRLVR | 20.06 | 22.78 |
| Qwen2.5-7B-LongPO-128K | 31.50 | 12.97 |
| + ACC(本文) | 68.28 | 77.51 |
QwenLong-L1.5 在 MRCR 上 92.30,看起来吊打 ACC。但要看脚注——QwenLong-L1.5 用了"文档清洗 + 知识图谱构建 + RL"的多阶段 pipeline,它的训练框架还没开源。这是工业级重投入的方案。
ACC 只用标准 SFT,在 GraphWalks 上反过来超过了 QwenLong-L1.5(77.51 vs 73.85)。我对这个对比的解读是:ACC 不是要做"最强长上下文模型",它是在最低工程复杂度下,给 agent 链路顺手补一个长上下文能力。如果你团队已经在跑 agent 应用、有大量历史轨迹,ACC 的边际成本几乎为零。
LongPO/LongRLVR 这两个数据看起来很惨,主要原因是它们基于 Qwen2.5(不是 thinking 系列),评测设置上也吃亏。作者放在表里是出于完整性,但客观说不太适合直接对比。
八、机制分析:模型到底学到了什么?
这部分是论文给我惊喜的部分——大多数 SFT 论文做到主表 + 消融就收尾了,作者还认真挖了一下"训完之后模型的内部机制有什么变化"。
注意力模式:任务自适应的重构
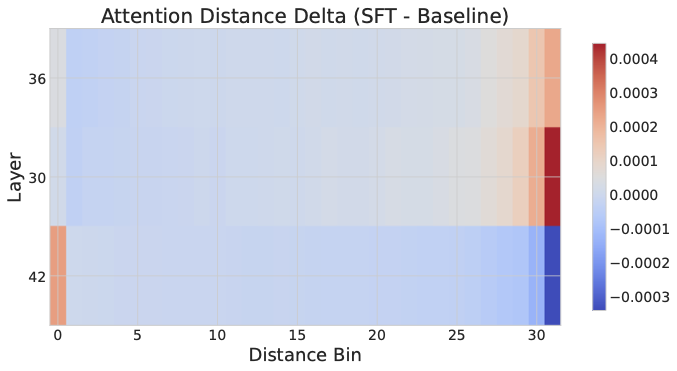
图4:GraphWalks 上 ACC 训练前后的注意力距离分布差异。蓝色为正向变化(注意力质量增加),可以看到模型同时在"近距离精细对齐"和"远距离跨节点跳跃"两个区段都增加了注意力——这正是图遍历任务需要的"局部检查 + 远程跳点"的双模式。
GraphWalks 上:模型在近距离 bin 和远距离 bin 上的注意力都增加。这跟图遍历任务结构吻合——既要做局部邻居检查,又要做远端节点跳跃。
MRCR 上:模型主要在近距离 bin 上增加注意力,远距离的 baseline profile 基本保留。这跟 MRCR 需要做的"扫描候选段落 → 精确比对"也吻合。
最有意思的是:两个任务上注意力变化最大的层完全不重叠。也就是说模型不是学到了一个统一的"长上下文模式",而是根据任务自适应地分配注意力资源。这个发现挺重要——它否定了"长上下文能力 = 一组固定的长程注意力头"这种朴素假设。
专家路由:任务相关的特化
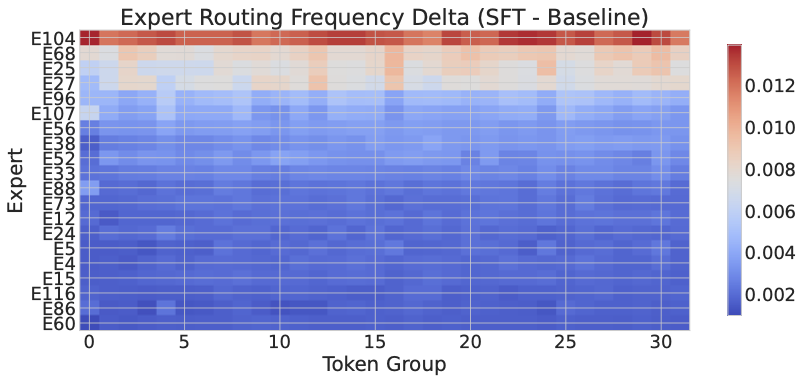
图5:MRCR 上 ACC 训练前后专家激活频率差异。可以看到某个专家在所有 token 组上激活频率都显著上升(深红区域),其他专家被压制——这是 MoE 架构下"专家特化"的典型迹象。
由于基础模型是 MoE,作者还看了专家路由的变化:
- GraphWalks:远距离 token 组的高激活分散在多个专家上,对应"跨节点跳跃需要并行处理"。
- MRCR:单个专家在所有 token 组上的激活都显著升高,其他专家被压制——指向"扫描-验证"这种序列化、专门化的处理流程。
跟注意力分析一样,两个任务上专家变化最大的层完全不同。这种"任务相关的专家特化"现象,跟近期一些 MoE 可解释性研究里的"emergent expert specialization"是吻合的。
我对这部分的判断:mechanism 分析虽然不能算 ACC 的核心贡献,但它有效反驳了一个潜在的批评——"你这就是个数据 trick,模型能力没有真正变化"。看到注意力模式和专家路由都发生了任务相关的结构性变化,至少能说明 ACC 不是在浅层拟合。
九、批判性视角:ACC 的盲点和真伪命题
聊完亮点,按惯例必须抠几个值得追问的点。
1. "Supervision blind spot" 是真命题,但它有多严重?
直观上 agent SFT mask 工具响应确实让 o_t 拿不到 y 的直接监督,但 agent 的真实痛点真的是"长上下文能力缺失"吗?
我倾向于认为这事儿对长上下文 benchmark 是真命题,对真实 agent 落地是部分真命题。真实 agent 任务里,每一轮的工具响应通过 a_{t+1} 间接拿到的信号其实够用——不然现有 agent 也跑不起来。但当任务需要把跨多轮的散落证据综合起来一次性回答(这是 MRCR/GraphWalks 直接测的),盲区就被放大了。
所以 ACC 受益最明显的是"长程依赖建模"这个具体子能力,不是 agent 的端到端能力。论文里没拿 SWE-bench、AppWorld 这种端到端 agent benchmark 测,是个合理但保守的选择。
2. 数据规模就 10K,会不会太小?
10,802 条训练样本听起来很少,但配合 4 epoch、序列长度 128K,总训练 token 数是相当可观的——粗算 10K × 64K 平均 × 4 = 2.5B tokens 量级。所以"数据量小"是个错觉,真正小的是轨迹数量,不是 token 量。
这也提示了一个事实:ACC 的成本不在标注,而在你愿意花多少 GPU 跑长序列训练。8 卡 sequence parallelism + 128K 序列,单 step 显存压力很大。这是个"工程成本转移"的故事——把人工长文档标注的钱省了,转移到训练算力上。
3. 跟纯长文档 SFT 的对照实验缺了
如果有一组对照——同样 token 量但用的是 Wikipedia/书本这种"自然长文档"做 next-token prediction——能直接证明"agent 编译数据 > 自然长文档"的优势在哪。论文没做这个对照。我猜作者的逻辑是"自然长文档 SFT 已经被 base model 训过了",但这个隐含假设需要明说。
4. Reasoning trace 的"教师依赖"是隐性瓶颈
SWE 任务上 V3.2-Thinking 只有 10% 的 pass rate——意味着ACC-SWE 的训练数据是被严重 filter 过的简单子集。这种偏差会传递到训练模型上,导致它在难 SWE 样本上可能并没有真的提升。后续如果换一个更弱的 teacher(比如 GPT-4o-mini),效果会怎么样?这个 ablation 是缺失的。
十、写在最后:这篇论文给我的三个工程启发
整体看下来,我觉得 ACC 是那种思路简单、效果硬、洞察深的论文。三个对工程实践的启发:
第一,所有跑 agent 的团队都在浪费一座金矿——通过率高的历史轨迹。每天有多少轨迹被你们的 agent 跑通然后扔掉了?ACC 等于告诉你这些数据按某种方式重新组装就能变成 SFT 黄金数据。如果你们已经在做工业级 agent,这个套路的实施成本几乎是零。
第二,标准 agent SFT 的训练目标值得重新审视。下次写训练代码的时候,认真想一下你 mask 掉的那部分 token 到底有没有让模型学到该学的东西。"约定俗成"不等于"最优"。
第三,长上下文不是单一能力,是一组任务自适应的能力。机制分析里看到的"不同任务激活不同层、不同专家"这个现象,意味着我们不能用单一的 needle-in-haystack 来评估长上下文。如果你在做这块的评测体系,必须把 MRCR、GraphWalks 这类有结构差异的 benchmark 放进去。
最后说一句,ACC 这篇思路上有点像"reverse engineering an agent's own data"。它没在追前沿模型架构,没在堆数据规模,就是把所有人都习惯性忽略的那块训练信号捡了起来。这种风格的工作我个人特别喜欢——让你回头看自己做过的东西,会突然意识到"原来这里还能这么挖一刀"。
如果你也在做 agent 训练或者长上下文,我觉得这篇值得仔细读。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新 AI 前沿,关注我