Agent Coding 测试时算力怎么花?Meta 给出了一个反直觉的答案:先做"摘要"再做"选拔"
核心摘要
测试时算力扩展(test-time scaling)这事儿在数学题、单轮代码生成里玩得很溜,无非就是多采几个、投个票、refine 一下。可一旦把场景换成长程的 agentic coding——比如让 agent 在 SWE-Bench 里改 Django 的 bug——之前那套就全失灵了:每次 rollout 是一条几十步的轨迹,里面塞满了 bash 输出、报错日志、试错痕迹,根本没法直接比较,更没法直接 refine。Meta Superintelligence Labs 这篇论文换了个思路:算力扩展的瓶颈不是"再多跑几次",而是"怎么把跑出来的轨迹变成可以被比较和复用的紧凑表示"。具体方法是把每条 rollout 压成一份结构化 summary,然后在这个 summary 层面上做两件事——并行的递归锦标赛投票(RTV)和顺序的 Parallel-Distill-Refine(PDR)。效果挺漂亮:Claude-4.5-Opus 在 SWE-Bench Verified 上从 70.9% 干到 77.6%,在 Terminal-Bench v2.0 上从 46.9% 拉到 59.1%;Gemini-3.1-Pro 在 Terminal-Bench 上更是从 52.5% 飙到 64.8%。这篇论文最值钱的地方不在于哪个具体技巧多惊艳,而在于它把长程 agent 的 test-time scaling 重新框成了一个表征–选择–复用的问题。
论文信息
- 标题:Scaling Test-Time Compute for Agentic Coding
- 作者:Joongwon (Daniel) Kim, Winnie Yang, Kelvin Niu, Hongming Zhang, Yun Zhu, Eryk Helenowski, Ruan Silva, Zhengxing Chen, Srini Iyer, Manzil Zaheer, Daniel Fried, Hannaneh Hajishirzi, Sanjeev Arora, Gabriel Synnaeve, Ruslan Salakhutdinov, Anirudh Goyal
- 机构:Meta Superintelligence Labs / University of Washington / NYU / Google DeepMind / CMU / Princeton
- 链接:arXiv:2604.16529
- 提交时间:2026-04-16
为什么"多跑几次再投票"在 agentic coding 里不灵了
先说一个我自己经常踩的坑。
之前在做单轮代码生成的 best-of-N 时,思路特别朴素:模型采 16 个候选,用一个 reward model 排个序,挑分最高的那个。简单,有效,至少 pass@1 是肉眼可见地涨。这就是过去两三年 test-time scaling 的主流套路:majority voting、self-refine、self-consistency,全都在围绕"多生成 + 后处理"这个轴在做文章。
可是 agentic coding 完全是另一套游戏规则。
你让 Claude 去改一个 Django 的 bug,它要先 ls、cat、grep 一通,找到相关文件,然后试着改,运行测试,看到 traceback,再回去看代码,再改一版……一条 rollout 跑完动辄几十步、几万 token,里面 80% 是终端输出、出错堆栈、临时探索。这些 trace 根本没法直接拿来比较。
你想 majority voting?可两条 trace 改的是不同文件,输出格式完全不一样,怎么 vote?
你想拿 trace 当 refinement context 喂给下一轮?上下文几万 token 起步,还全是 noise,模型直接被淹没。
之前做过类似事情的人都知道,这块的痛点不是"算力不够",而是"算了半天的结果用不上"。每条 rollout 里有用的信号其实就那么几条——agent 试过哪条 hypothesis、改到了哪一步、为什么挂了——但这些信号被海量的低价值 trace 稀释得几乎看不见。
这篇论文的第一个判断其实就在这儿:长程 agent 的 test-time scaling,说到底是一个表征问题,不是采样问题。
如果你接受这个前提,后面的设计就顺了。
方法核心:先把 rollout 压成 summary,再在 summary 层面做选择与复用
整篇论文的骨架其实只有三件事:
- 把每条 rollout 用 LLM 自己压成一份结构化 summary(保留关键 hypothesis、进展、失败模式,扔掉冗余 trace 细节)
- 并行维度:用 RTV(Recursive Tournament Voting)在 summary 上做锦标赛式选拔
- 顺序维度:用 PDR(Parallel-Distill-Refine)的 agentic 版,把上一轮的 summary 作为下一轮 rollout 的 refinement context
最后把这两件事拼成一个统一的 pipeline:iter-0 跑 N 个 rollout → 出 summary → RTV 选 top-K → 这 K 个 summary 作为下一轮的 context → iter-1 跑 N 个 fresh rollout → 再 RTV 选最终的 top-1。
下面这张图是整个 PDR+RTV 的全流程:
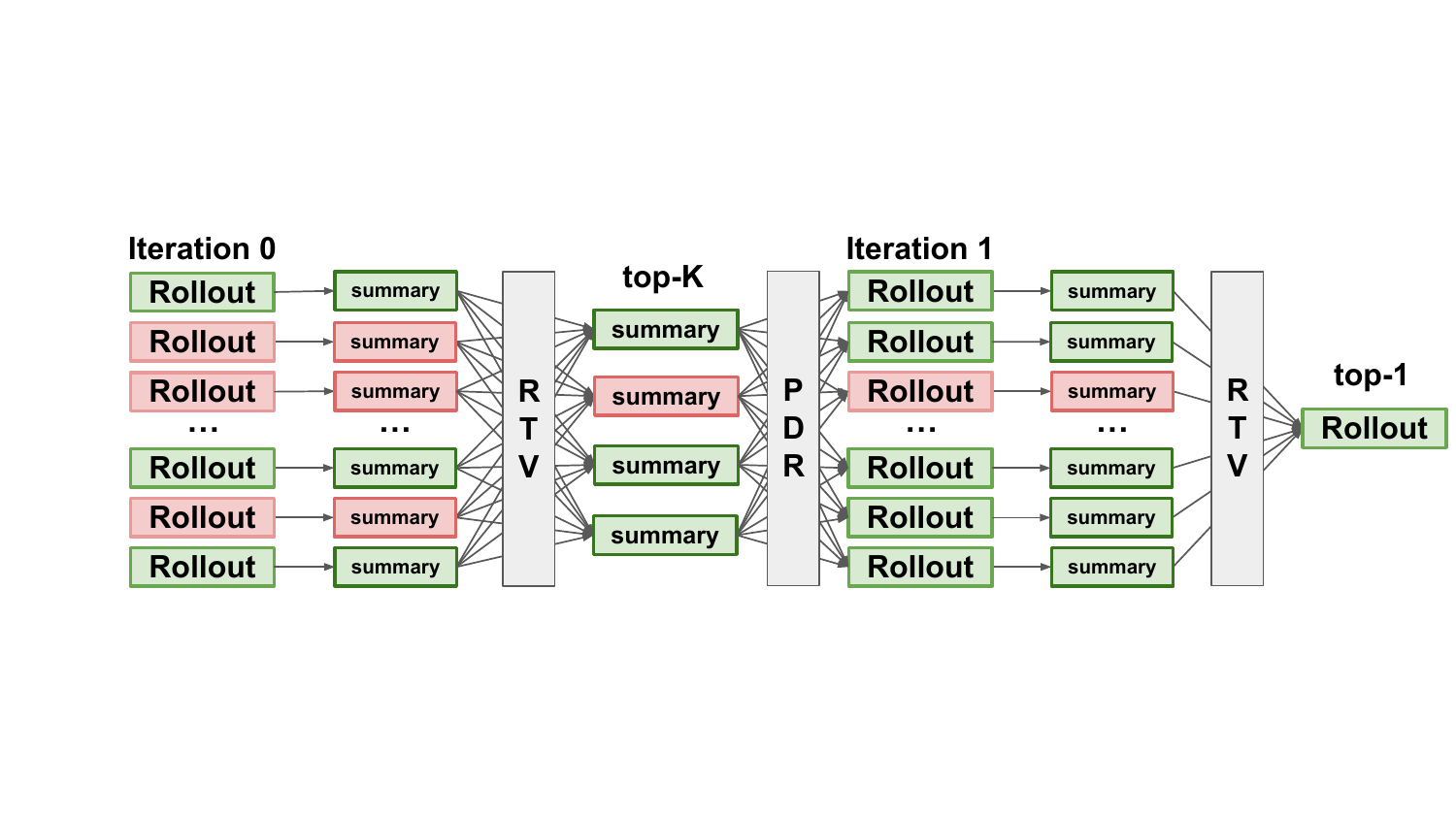
图1:整个 pipeline 是 "select → reuse → select" 三段式。绿色块是成功的 rollout/summary,红色是失败的。注意第二轮的环境是全新初始化的,agent 拿着前一轮的 summary 重新出发,而不是在原 trajectory 上接着跑。
接下来逐个讲清楚。
Rollout 怎么压成 Summary
形式上很简单:给定 rollout \(\mathcal{R}_i\),用一个 summarization prompt 喂给同一个 LLM,得到 summary \(S_i = \Pi_{\mathrm{LM}}[\mathcal{P}_{\mathrm{sum}}(\mathcal{R}_i)]\)。
但工程上这一步其实是整个方法的命门。Summary 要保留什么、扔掉什么,直接决定下游能不能 work。论文给的 prompt 让 summary 包含:agent 试过的核心 hypothesis、做出的关键决策、达到的进展、遇到的失败模式。terminal 输出的细节、重复的探索、dead-end 都被丢掉。
为什么这一步是命门?后面的 ablation 会告诉你答案——直接用原始 trace 做对比,效果会比 summary 差一截。这不是细节,这是这篇论文的第一个核心 finding。
Recursive Tournament Voting(RTV):并行选拔
并行维度的目标很明确:跑 N 个独立 rollout,从中选出最好的那个,但不能用 ground-truth(毕竟测试时没有 oracle)。
朴素做法:把 N 个 summary 全塞进 context,让 LLM 一次比较,挑最好的。
RTV 的做法不一样:递归地分小组比较。
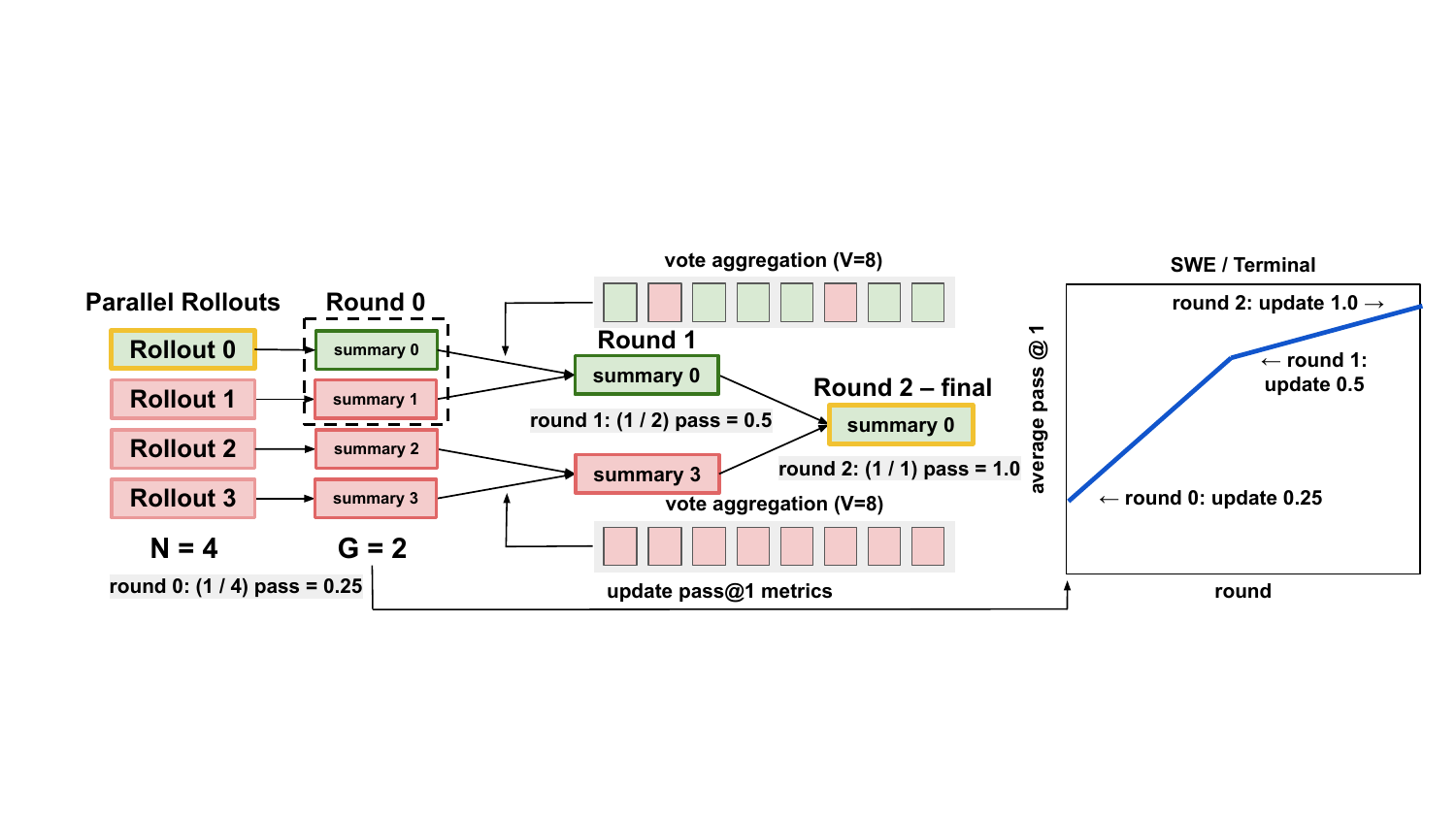
图2:RTV 的工作流程图。左边是 N=4 个 rollout 进来,先生成 summary;中间按 G=2 分组对比(每组用 V=8 次投票),选出 round winner;不停 recursive 直到只剩 top-1。右边的折线显示每一轮 pass@1 都在上升。
形式化一点写:在第 r 轮,每个 group j 内执行
人话翻译:每个 group 用 V 次投票决定 winner,winner 进入下一轮。
为什么要 recursive 而不是 flat?因为LLM 一次比 16 个东西,肯定不如比 2 个东西可靠。这个直觉在后面的 ablation 里被验证得很彻底——G=2(两两比较)效果最好。
为什么要 V=8 多次投票?因为单次比较有噪声,投票能平滑掉。同样在 ablation 里验证,V 从 1 涨到 8 提升明显,再往上递减。
Parallel-Distill-Refine(PDR):顺序复用
顺序维度的核心问题:怎么把上一轮的经验喂给下一轮?
论文用了 PDR 的 random-K 变体:上一轮跑 N 个 rollout 出 N 个 summary,下一轮的每个 rollout 随机抽 K 个 summary 作为 refinement context,在全新初始化的环境里重新跑。
注意"全新初始化环境"这一点很关键。Agent 不是在原 trajectory 上接着跑,也不是带着 partial state 继续,而是带着 prior experience 的"教训"重新出发。这个设计有点像人类做研究——你不会在失败的实验环境里硬刚,你会换个干净桌面,把上次踩的坑写在便签上提醒自己。
形式上,第 t+1 轮的第 i 个 rollout 的 refinement context 是:
其中 \(J_i^{(t+1)}\) 是从上一轮 N 个 summary 中随机抽的 K 个的下标集合。
第一个 action 在原问题 + refinement context 上 condition:
后面的 action 走正常的 rollout 动力学,只是 context 里多了 refinement summaries。
把两个拼起来:select → reuse → select
单独看 RTV 和 PDR 都没什么稀奇,关键是怎么拼。
论文的 unified pipeline 其实就是把 "随机 K"换成"RTV 选 K":
- Iter 0:跑 N=16 个独立 rollout,每个生成 summary
- Select-K:用 RTV 选出 top-K=4 个 summary
- Iter 1:在这 K 个 summary 作为 context 的条件下,再跑 N=16 个 fresh rollout
- Final RTV:对 iter-1 的 16 个 rollout 再做一次 RTV,选出最终的 top-1
这里有个"探索 vs 利用"的小巧思——K 不能太大也不能太小。K=1 退化成 vanilla refine,多样性没了;K=N 退化成全量传,相当于没选;K=4(中间地带)保留了不同 hypothesis 之间的 cross-pollination,又不至于让 context 充斥低质量 rollout。
实验:消融在前,主表在后
这篇论文实验做得挺扎实的,先用 ablation 把每个 design choice 论证一遍,再上主表。我也按这个顺序聊。
Finding 1:Summary 比原始 trace 更好用作比较对象
这是整个论文的第一块基石。
论文做了一个对照实验:在 RTV 的每一轮,要么把原始 rollout trace 丢进去比较(橙色),要么把 structured summary 丢进去(蓝色)。两个模型 × 两个 benchmark。
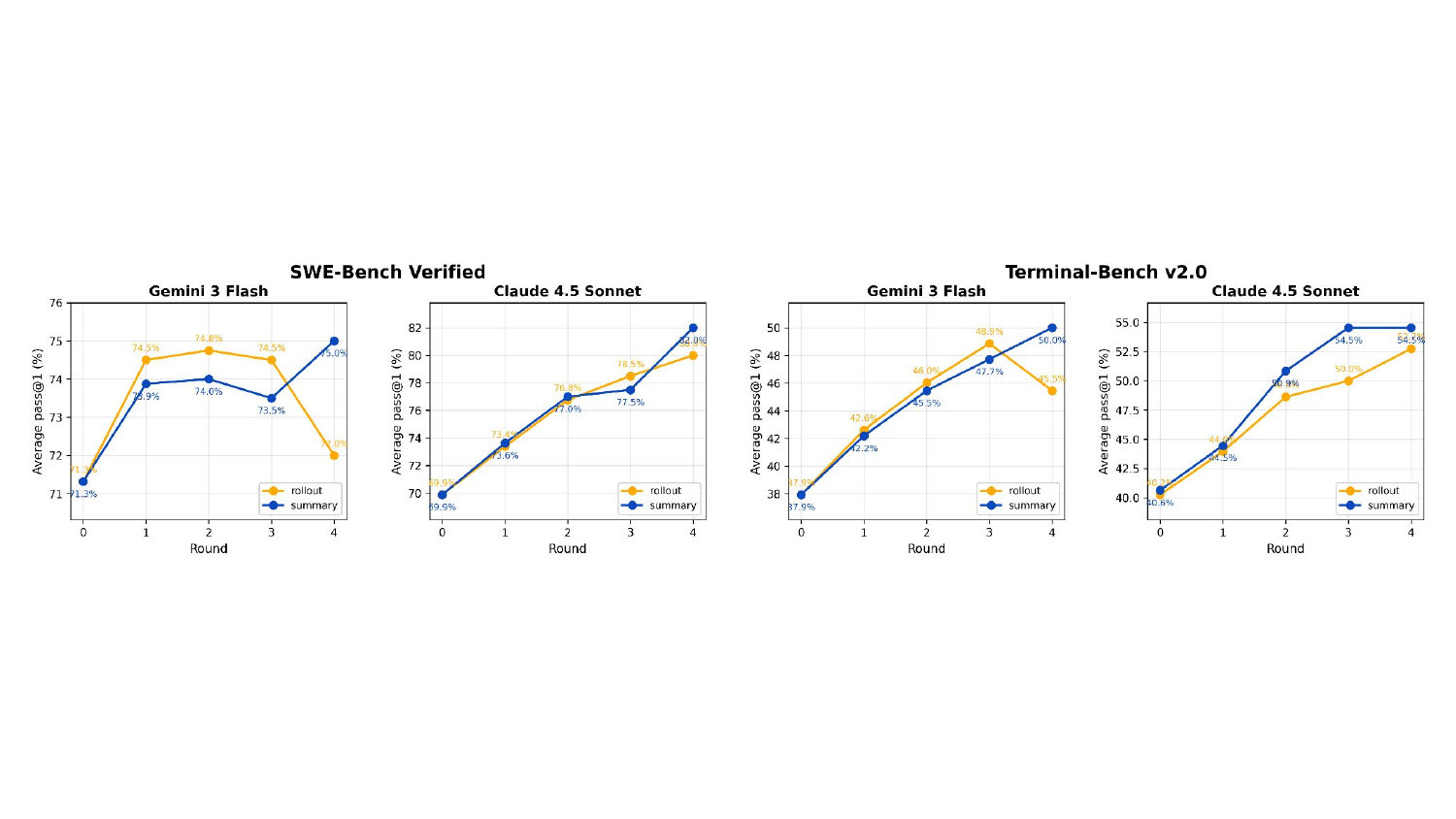
图3:summary vs raw trace 的对比。Round 0 是初始 pass@1(两条线起点重合,因为 rollout 还没经过任何选拔),随着 round 推进两条曲线开始分化。注意最后一轮(决赛)summary 拉开差距最明显——这一轮选的是最难分辨的两条 trace,trace 太长太 noisy 反而误导了 judge,summary 的"信噪比优势"在决赛里最值钱。
我看到这个图的第一反应:这说得通。轨迹里 80% 是噪音,到了决赛阶段两条候选都已经"看起来挺像",原始 trace 里那些不一致的细节反而干扰判断;summary 把"agent 最终改了哪几个关键点、test 结果怎样"提炼出来,judge 一眼就能定胜负。
Finding 2:递归小组比较 > 平铺大组比较
第二个 ablation 其实在挑战一个常识——既然 LLM 上下文越来越长,为什么不一次性比 16 个?
答案是:长上下文不等于好判断。
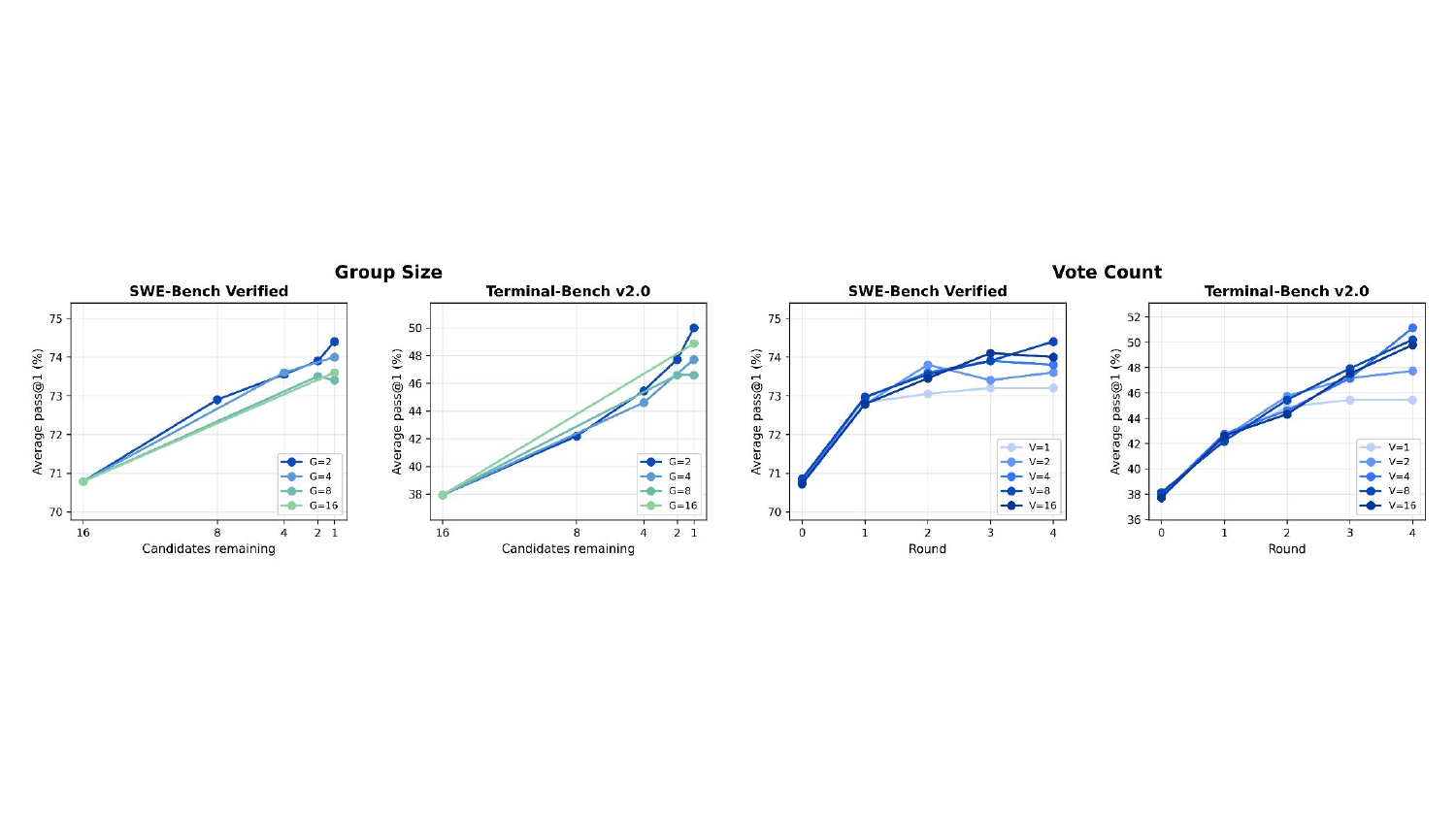
图4:左侧的 x 轴是"剩余候选数",从 16 一路缩到 1。G=2(深蓝)的曲线在 Terminal-Bench 上尤其陡峭,最终终点最高。右侧的 V 扫描显示 V=8 是 sweet spot,再往上提升微弱。
这个结果有点反直觉但其实合理:让 LLM 同时排序 16 个候选,等价于一次做 16-way 比较,这种全局判断的可靠性远低于一连串局部的 pairwise 判断。RTV 把全局选择拆成了一系列"local two-by-two"决定,每一步都只让模型做最简单的判断,这种"分而治之"反而提高了整体准确率。
V=8 这个数字的工程含义是:单次比较的噪声不能忽略,但平均 8 次基本能稳定下来,再多就是浪费 token。
RTV 单刀作战的效果
把 PDR 拿掉,只用 RTV 做并行选择,效果如何?
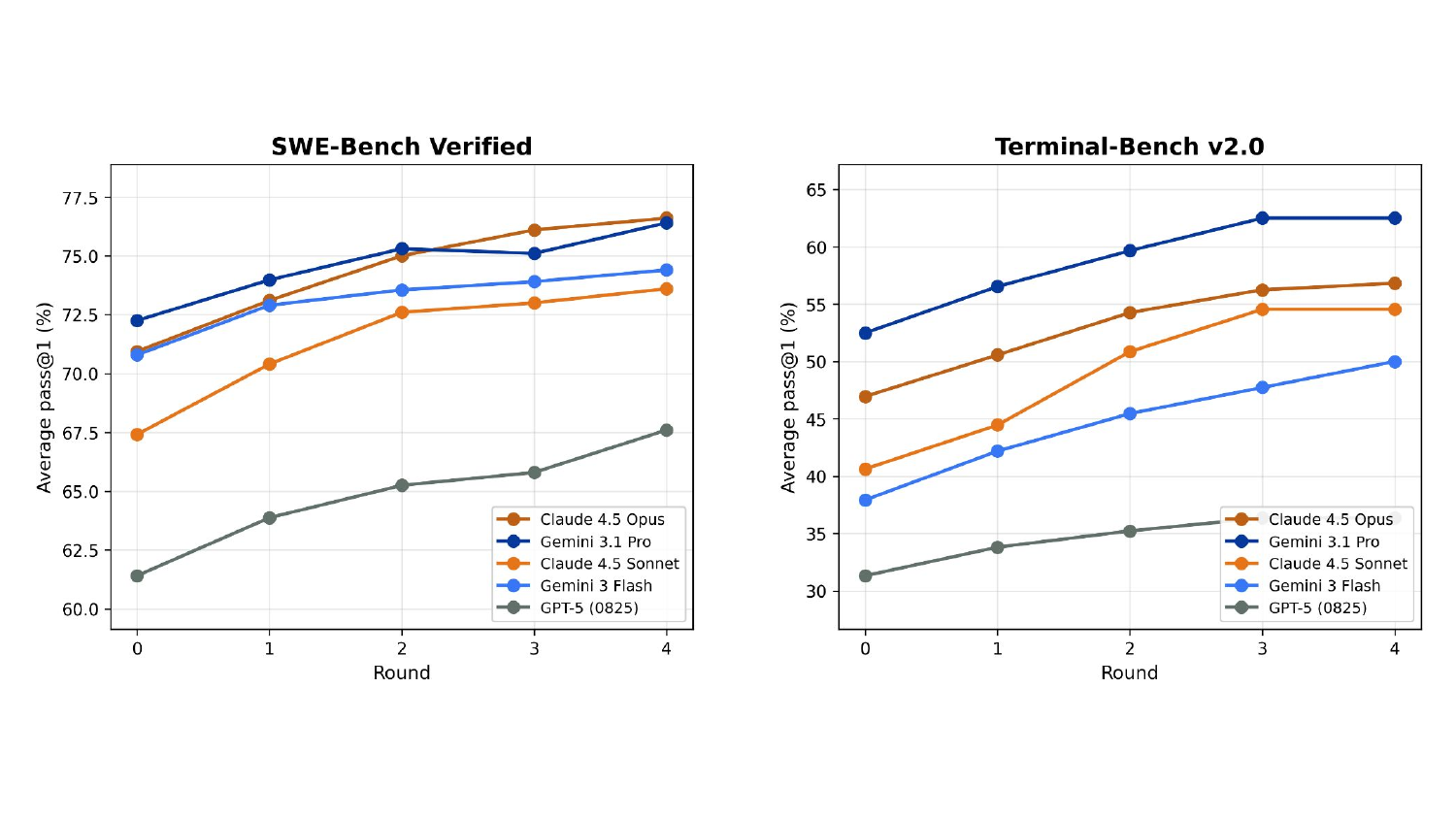
图5:RTV 作为单独的并行聚合机制的效果。可以看到所有模型从 round 0 到 round 4 都在涨,SWE-Bench 上平均涨 5–6%,Terminal-Bench 上涨 8–12%。其中 Sonnet 在 Terminal 上从 40.6% 飙到 54.6%,涨幅最大。
我注意到一个细节:Terminal-Bench 上的提升幅度普遍大于 SWE-Bench。论文里给的解释是 Terminal-Bench 的方差更大、长程 trajectory 之间的差异更明显,所以"选对了"的收益更大。这个解释我同意——Terminal-Bench 任务的 rollout 更"开放",model 之间的 hypothesis 多样性更大,选拔机制能挖出更多的 upside。
Finding 3:refinement context 用多份比单份强,选过的比随机的更强
这是 PDR 这边的核心 ablation。
论文比了三种构造 refinement context 的方式: - single-rollout:每个 iter-1 rollout 只参考自己 iter-0 的 summary(K=1) - random-K:随机抽 K=4 个 iter-0 的 summary - select-K:用 RTV 选出 K=4 个最好的 summary
| 模型 | Single iter-1 | Random-K iter-1 | Select-K iter-1 |
|---|---|---|---|
| Claude-4.5-Sonnet | 70.87% | 75.06% | 78.06% |
| Gemini-3.1-Pro | 73.75% | 76.94% | 79.25% |
(iter-0 都是 baseline,三种方式起点一样:Sonnet 69.87%,Pro 72.69%)
数据本身已经说话了:单独看自己的 iter-0 几乎没涨(+1 个点都不到),用 K=4 随机的涨 4-5 个点,用 RTV 选的 K=4 又再涨 2-3 个点。
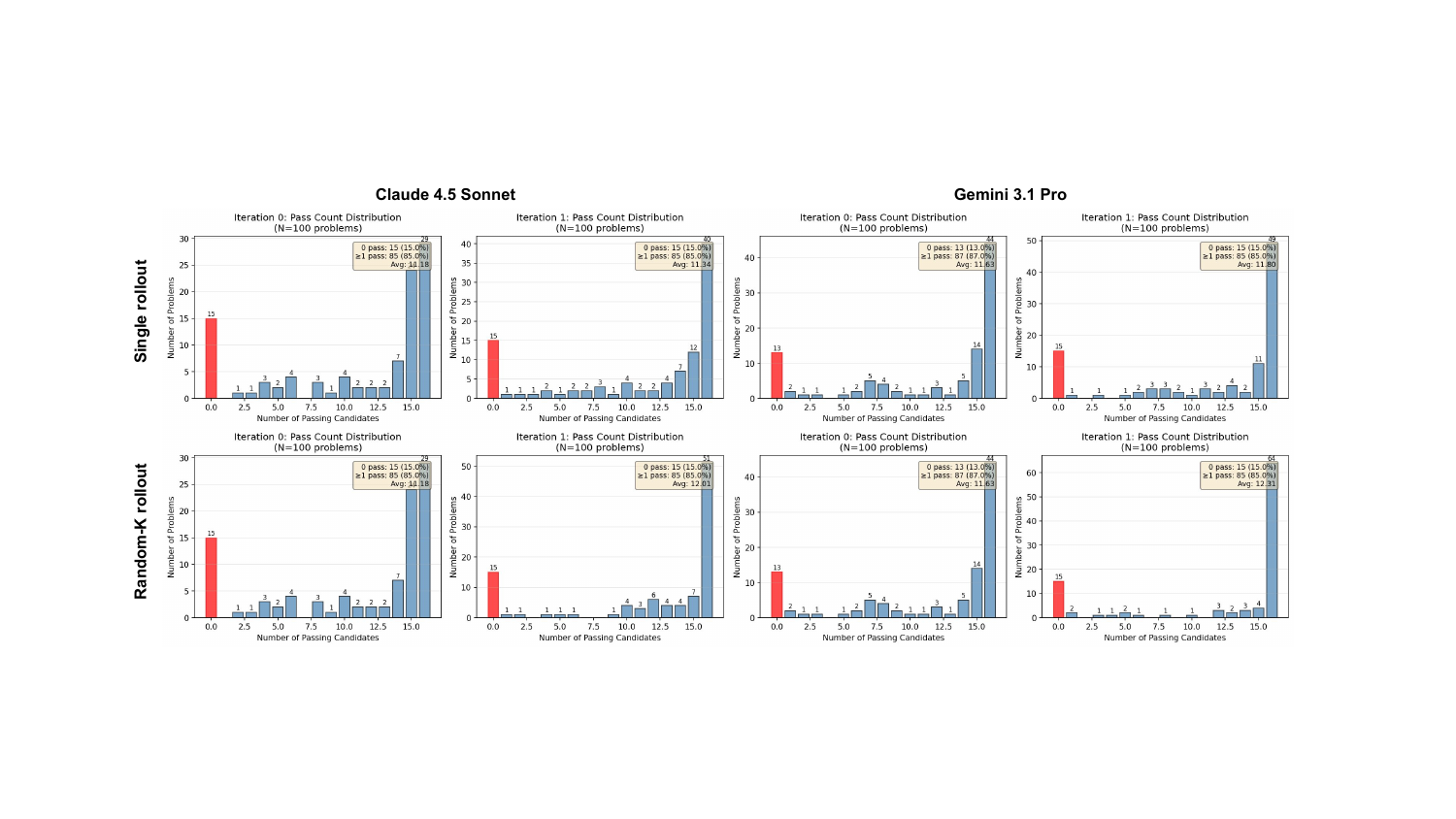
图6:分布图清楚地展示,random-K refinement 不只是把均值拉高,而是把整个 pass count 分布的右尾(16/16 全过的任务)拉得更厚。Sonnet 在 single-rollout 下 100 个任务有 40 个达到 16/16,random-K 下涨到 51 个。多样化的 prior context 真的在帮 agent 更稳定地拿全分。
我对这个结果的解读:单条 prior summary 容易让 agent 锁死在一种思路上(如果这种思路本身有问题,就一条道走到黑);多条 summary 形成的"思路池"反而能 cross-pollinate 出更好的解。这跟人类 brainstorm 的逻辑一脉相承——多样性本身就是 robustness 的来源。
Finding 4:refinement context 的质量决定下一轮的天花板
这个发现是论文里最让我"哦"了一下的。
论文按"K=4 个 prior summary 中有几个是 passing"把任务分桶,然后看 iter-1 的 pass@1:
| Model | 0/4 passing | 1/4 | 2/4 | 3/4 | 4/4 passing |
|---|---|---|---|---|---|
| Claude-4.5-Opus (SWE) | 0.1% | 33.4% | 55.5% | 85.4% | 99.2% |
| Gemini-3.1-Pro (SWE) | 0.6% | 36.9% | 38.4% | 87.0% | 99.8% |
差距夸张到什么程度?refinement context 里 4 个 prior 全失败时,iter-1 几乎跟着失败(0.1%);4 个全成功时,iter-1 几乎确定成功(99.2%)。
这其实是一个挺残酷的事实:sequential refinement 的 upside 完全被 prior 质量绑定。如果你 select-K 这一步选不准(选出来的全是失败 rollout),那 sequential 这一步就是在浪费算力,甚至可能把模型带到死胡同。
这就是为什么 RTV 和 PDR 必须组合用——RTV 保证 select-K 选到的是高质量 prior,PDR 保证这些 prior 被有效复用。任何一个环节弱了,整体就垮。
主表:PDR+RTV 在五个前沿模型上的表现
终于来到主表。
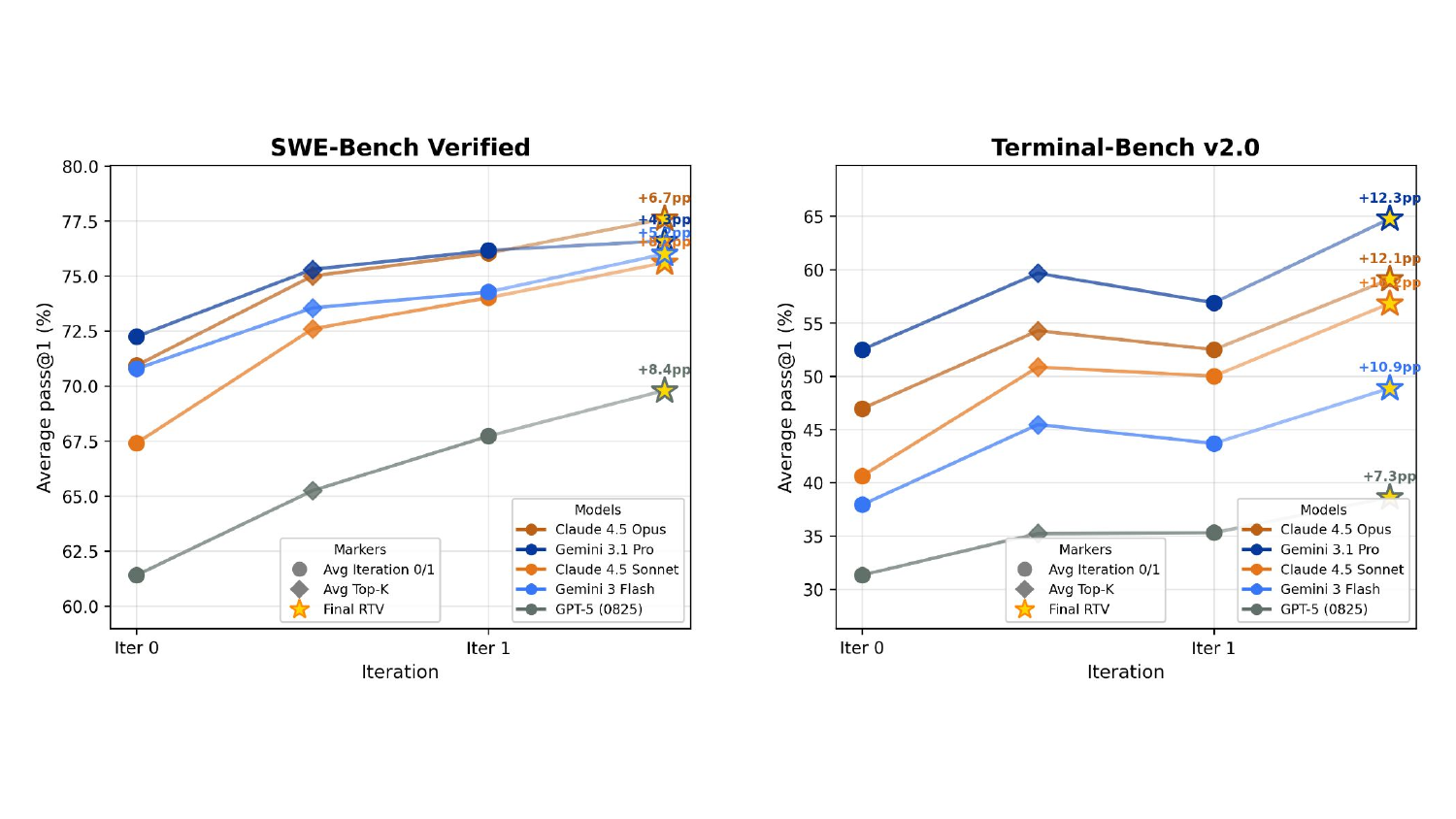
图7:主结果可视化。注意每个模型的"星"位置——final RTV 之后,五个前沿模型在两个 benchmark 上全部涨幅显著。Sonnet 在 Terminal 上 +16.2pp 是最猛的提升,对应到现实就是 14 个原本搞不定的任务现在能搞定。GPT-5 (0825) 是最弱的 baseline,但也涨了 8.4pp(SWE)和 7.3pp(Terminal)。
主表数字:
SWE-Bench Verified
| 模型 | Iter 0 | Sel-K | Iter 1 | Final | Δ |
|---|---|---|---|---|---|
| Claude 4.5 Opus | 70.94 | 75.00 | 76.04 | 77.60 | +6.66 |
| Gemini 3.1 Pro | 72.25 | 75.30 | 76.16 | 76.60 | +4.35 |
| Claude 4.5 Sonnet | 67.41 | 72.60 | 74.01 | 75.60 | +8.19 |
| Gemini 3 Flash | 70.79 | 73.55 | 74.28 | 76.00 | +5.21 |
| GPT-5 (0825) | 61.41 | 65.25 | 67.73 | 69.80 | +8.39 |
Terminal-Bench v2.0
| 模型 | Iter 0 | Sel-K | Iter 1 | Final | Δ |
|---|---|---|---|---|---|
| Claude 4.5 Opus | 46.95 | 54.26 | 52.49 | 59.09 | +12.14 |
| Gemini 3.1 Pro | 52.49 | 59.66 | 56.89 | 64.77 | +12.28 |
| Claude 4.5 Sonnet | 40.62 | 50.85 | 50.00 | 56.82 | +16.20 |
| Gemini 3 Flash | 37.93 | 45.45 | 43.68 | 48.86 | +10.93 |
| GPT-5 (0825) | 31.32 | 35.23 | 35.30 | 38.64 | +7.32 |
几个观察:
第一,Terminal-Bench 的提升普遍大于 SWE-Bench,跟前面 RTV 单跑的观察一致。这说明任务方差越大、长程 trajectory 越复杂的场景,PDR+RTV 的相对收益越大。
第二,Iter 1 的平均 pass@1 反而比 Sel-K 低一些(比如 Pro 在 SWE 上 75.30 → 76.16,但 Opus 在 Terminal 上 54.26 → 52.49)。这其实揭示了一个 nuance——select-K 是从 16 个里选最好的 4 个,平均自然高;iter-1 是 16 个全新 rollout,里面有的好有的坏,平均拉低了。但 final RTV 又把 iter-1 的好 rollout 再选出来,所以最终 pass@1 还是涨了。
第三,最弱的 baseline 也能稳定涨——GPT-5 (0825) 在两个 benchmark 上都拉了 7-8 个点。说明 PDR+RTV 对底层模型能力没有特别强的依赖,是个"普适增量"。
一个意外的副产品:refinement 让 agent 跑得更快
论文还做了一个 step count 的统计,结果挺让我意外的:
| Model | SWE Iter 0 | SWE Iter 1 | Terminal Iter 0 | Terminal Iter 1 |
|---|---|---|---|---|
| Claude-4.5-Opus | 41.23 | 14.31 | 24.43 | 12.14 |
| Gemini-3.1-Pro | 35.56 | 17.95 | 21.57 | 10.95 |
| Claude-4.5-Sonnet | 49.24 | 25.02 | 21.74 | 7.78 |
| Gemini-3-Flash | 51.10 | 28.80 | 16.01 | 7.80 |
Iter 1 的平均 step 数大概是 Iter 0 的一半甚至更少。Opus 在 SWE 上从 41 步降到 14 步——agent 拿到 prior summary 后,不再花一堆步骤去 ls、cat、grep 探索目录结构,直接奔着已知的解题路径去了。
这一点的工程价值其实比 pass@1 提升更大——少跑 65% 的步数意味着推理成本(API 调用次数、token 消耗)大幅下降。如果你是在做产品,这个数字会比 pass@1 提升更让 CFO 开心。
让我皱眉的几个地方
聊完亮点,说几个我看完之后觉得不太对劲的地方。
LLM 自己当 judge,准确率其实没那么高
论文里有个表格统计了 RTV 中 LLM-as-Judge 的 group selection accuracy。我看完有点意外:
| Iter | Model | SWE Avg | Terminal Avg |
|---|---|---|---|
| 0 | Opus | 67.0% | 77.9% |
| 0 | Pro | 64.5% | 80.7% |
| 0 | Sonnet | 66.6% | 81.7% |
| 0 | Flash | 61.3% | 82.3% |
| 1 | Opus | 58.2% | 77.2% |
| 1 | Pro | 48.3% | 76.7% |
| 1 | Sonnet | 60.9% | 78.0% |
| 1 | Flash | 62.1% | 75.8% |
iter-1 的 SWE 上,Pro 当 judge 的准确率只有 48.3%——比随机猜还差。论文自己也承认 Pro 在这次实验里表现异常,怀疑跟 API failure 有关,但即便是其他模型,iter-1 上 SWE 的 judge accuracy 也都跌到了 60% 出头。
这个数字说明什么?说明 RTV 当前的"judge"组件远远没到完美,还有很大优化空间。论文里也明说了——"我们预期通过 SFT/RL 训练专门的 judge 模型能进一步提升 RTV 性能"。
说到底,目前 RTV 是用一个"勉强及格"的 judge 拼出了 +5~12pp 的提升。如果有一天 judge 本身被针对性优化,这套方法的天花板还能往上抬不少。
失败模式:refinement 也会让任务"变差"
论文很坦率地承认了一个 unfavorable dynamic:iter-1 之后,"全失败"(0/16 passes)的任务数也增多了。
举例:Opus 在 SWE 上,0/16 passing 的任务数从 73 涨到 94(+21)。原因是 RTV 在这些"低质量 task"上选出的 top-K 大概率是失败 rollout,喂给下一轮就把 agent 带进了死胡同。
这是一个 bimodal 分布——成功的更稳了(16/16 涨了 141),失败的更死了(0/16 涨了 21)。整体净改善还是正的,但这个 failure mode 在生产环境里会比 benchmark 里更危险。如果你部署到一个 task 分布更宽的环境里,可能会遇到大量任务在 refinement 后退化的情况。
"首次"这个词需要打个问号
论文把自己定位为 "test-time scaling for agentic coding 的统一框架",但 trajectory summarization + multi-rollout aggregation 的思路其实跟 CodeMonkeys、SWE-Replay、OTTER 等同期工作有不少重叠。
我觉得这篇论文真正原创的地方有两点: 1. 把 summary 作为通用 interface 同时服务于 parallel 和 sequential 两个维度 2. RTV 的"递归 + 投票"组合相对新颖,而且做了相对系统的 ablation
但单独看任何一个组件,都不能算横空出世的颠覆性创新。这是一篇典型的"工程整合 + 系统验证"论文,价值在于完整性和可复现性,不在于单点突破。
我的判断:这篇论文值不值得细读
值得,但不要被表面的"+12pp"蒙住眼睛。
真正的亮点在于:它把长程 agent 的 test-time scaling 重新框成了一个"表征–选择–复用"三段式问题。这个框架比单点的 trick 更有迁移价值。如果你在做任何长程 agent 系统(不只是 coding),都应该问自己三个问题: 1. 我的 rollout 表征是不是太冗余了?能不能压缩成更高信噪比的 summary? 2. 我的多 rollout 选择机制是不是太粗暴?要不要 decompose 成 small-group 比较? 3. 我的 sequential refinement 是不是在用单条 prior?要不要换成多条 prior 的 cross-pollination?
对工程的实用启发: - 推理成本敏感的场景,不要无脑上 N=16,可以先 N=8 + RTV,可能性价比更高 - 如果你已经有 best-of-N 流程,加一个 summary 步骤 + RTV 替换原来的 majority voting,几乎是无痛升级 - PDR 这一步的隐性收益(step 数减半)在产品环境里的价值可能比 pass@1 提升更大 - 训一个专门的 judge 模型(SFT/RL)可能是这套方法下一步最值得做的事
几个值得追问的开放问题: - 这个框架能不能扩展到非 coding 的 agentic 任务?(比如 web agent、multi-tool agent)论文最后的 future work 提到了 persistent external artifacts,方向应该是这个 - summary 的 prompt 设计敏感性如何?换个 prompt 模板效果差距大不大?论文没正面回答 - N、T、K、G、V 这一堆超参在不同领域怎么调?现在的 default 是为 SWE/Terminal 调出来的,跨域可能要重做
如果你正在做 agent 系统,这篇论文最值钱的不是它的具体方法,而是它给你提供的思维框架——把"多花点算力"这个粗糙问题,拆解成 "怎么压、怎么选、怎么复用"三个可解的子问题。
这种把粗糙问题转化成精细子问题的能力,本身就是好研究的标志。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新AI前沿,关注我