Memanto:当所有人都在堆图谱时,他们用一颗朴素的向量索引把SOTA又拿回来了
核心摘要
过去一年Agent记忆赛道的画风几乎是同一个套路——堆图谱、堆Pipeline、堆多查询。Mem0、Zep、Letta、A-MEM全是"向量+知识图谱"的混合架构,写一条memory要走一遍LLM抽实体、再写图、再更新索引,几秒钟就这么没了。Memanto这篇论文反着来:只用纯向量、单次检索、零LLM写入,照样在LongMemEval上刷到89.8%、LoCoMo上87.1%,把所有同样走"vector only"路线的baseline甩开20多个点,整体只差Hindsight那种4/4复杂度的怪物一两个点。它的底层是Moorcheh团队自家的Information Theoretic Search引擎——把embedding二值化压缩32倍,用信息论度量替代余弦距离,做到sub-90ms的确定性检索、无索引延迟、即写即查。再叠一个13类语义类型的Memory schema和冲突检测机制,就基本是一个能直接打到生产的Agent记忆层。这篇论文最值钱的不是分数本身,而是它用一个干净的消融把"图谱必要性"这件事戳破了:Recall扩到k=40一步白涨20.4个点,prompt工程死磕只有2.2个点——结构没那么重要,能把相关chunk捞回来才重要。
论文信息
- 标题:Memanto: Typed Semantic Memory with Information-Theoretic Retrieval for Long-Horizon Agents
- 作者:Seyed Moein Abtahi, Rasa Rahnema, Hetkumar Patel, Neel Patel, Majid Fekri, Tara Khani
- 机构:Moorcheh.ai / Memanto.ai 团队
- arXiv:2604.22085
- 日期:2026-04-23
- 页数 / 体量:13页,10表,8图
一个让我想骂街的现状:写一条记忆,要等3秒
先聊点工程感受。
如果你最近做过任何带"长记忆"的Agent,大概率踩过同一个坑:用户随口说一句"我们deadline改到5月1号了",你想存进Mem0或者Zep,然后立刻问Agent"我们deadline啥时候?"——结果Agent答了上一版的4月15号。
为什么?因为这条新memory正在异步走"LLM抽实体→更新向量库→同步到Neo4j"的pipeline,2-3秒之后才能被检索到。
这就是Memanto论文里给的那个名字——Memory Tax(记忆税)。它说得挺狠:现在主流的Agent记忆系统,每写一条都要交一笔税:LLM token、ingestion延迟、Graph基础设施、空闲实例费用,一项不少。
我之前看过Mem0自己的ablation表,加了Graph之后的效果提升大概只有2个点,但运维复杂度直接从1变成3——一个Postgres + 一个Qdrant + 一个Neo4j,三套东西一起scale。如果你做过SaaS,应该立刻能感受到这个trade-off有多别扭。
Memanto这篇论文的姿态特别直接:这税我不交了,效果还更好。
它给出来的成绩是LongMemEval 89.8% / LoCoMo 87.1%,在所有"vector only"的方案里是断档第一,比Mem0高出22.9个点。然后它在论文里把Hindsight那种"4/4最大复杂度"的对手单独拎出来对比——确实Hindsight在LongMemEval上比它高1.6个点(91.4% vs 89.8%),但那是要做parallel multi-query + reflection passes换来的,Memanto一句single query就交付了。
下面这张图是论文里非常有"slogan感"的Figure 1,把过去三年的Agent记忆架构演化画出来了:
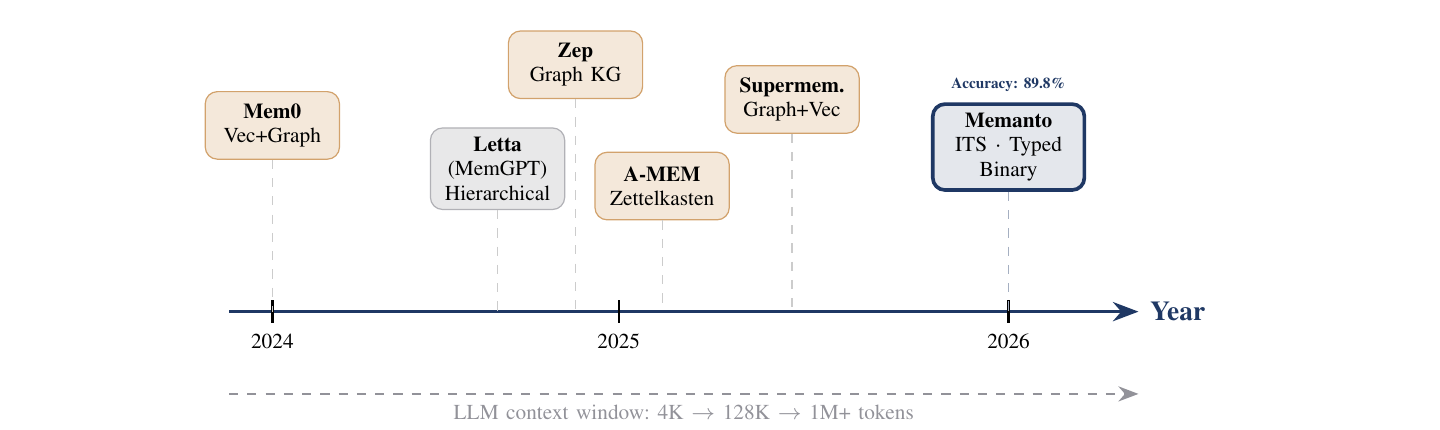
图1:这张图本身就是论文的核心立场——上下文窗口都涨到1M+了,谁还需要在外面堆一坨graph?
它到底反对的是什么?先把"图谱派"的账算清楚
这部分论文写得挺克制,我给翻译得直白一点。
Mem0g / Zep / A-MEM做了什么:每写一条memory,先用LLM抽实体("用户=Alice,角色=PM,截止日期=4月15日"),把这些三元组写到Neo4j;同时把原文向量化写到Qdrant;再做一次跨索引的同步。单次写入就要≥2次LLM调用,延迟2-3秒起步。
Letta / MemGPT做了什么:用OS分页思路把信息在context和外存之间搬来搬去,靠递归summarization压缩。问题是召回精度受summary质量牵制,而且每次recall都可能触发新一轮的compression,latency不稳定。
Hindsight做了什么:双管齐下——既做vector retrieval,又做reflection memory,用multi-query把候选集扩大,然后用反思层去筛选。效果好(LongMemEval 91.4%),但complexity score拉满到4/4。
Memanto团队画了张图(Figure 8)把这件事一目了然——横轴是架构复杂度(0-4分),纵轴是benchmark分数:
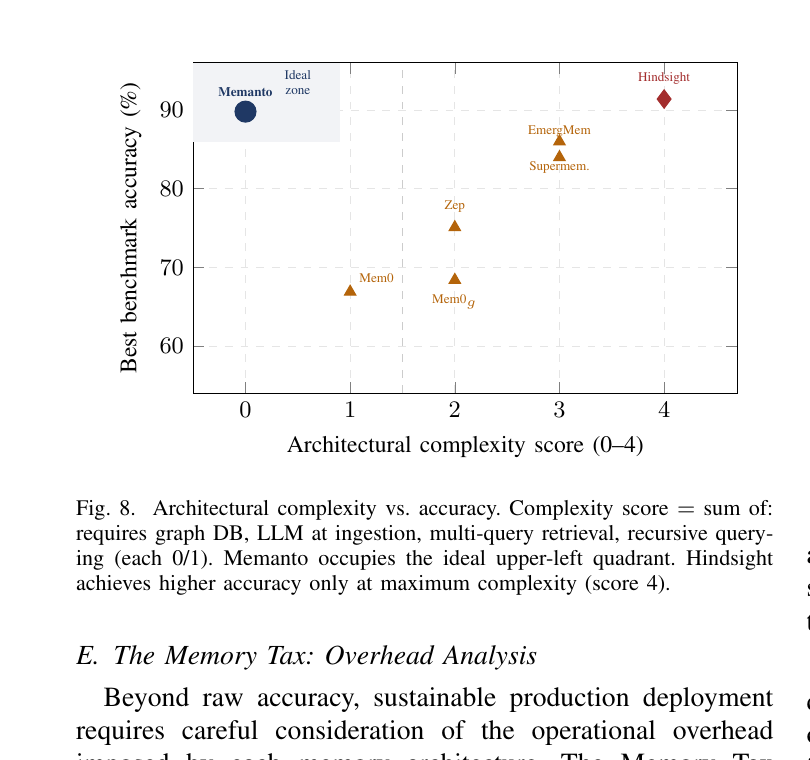
图8:你看Hindsight在右上角,那个分数是用4/4的复杂度换来的;Memanto站在左上角的"Ideal zone"里,0复杂度同样能打到90左右。这才是论文真正想说的故事。
我自己的判断:这张图比文字更狠。它实际上是在跟整个图谱派说——你们多花的那些工程预算、运维成本、写入延迟,并没有换来对应的精度回报。
方法核心:六条desiderata + 13类typed memory + ITS引擎
Memanto没急着上系统图,先讲了六条它认为生产级Agent记忆系统必须满足的设计原则(D1-D6)。这部分我觉得是论文最值得认真看的元设计:
| 编号 | 原则 | 一句话翻译 |
|---|---|---|
| D1 | Queryable, not injectable | 不要把整团context塞给Agent,要让它能像找图书管理员一样按相关性查 |
| D2 | Temporally aware with decay | 昨天定的deadline和半年前的偏好权重不该一样 |
| D3 | Confidence and provenance tracking | 区分"用户明确说的"和"系统推断的",别让Agent对过时数据自信 |
| D4 | Typed and hierarchical | episodic / semantic / procedural要分开存分开查 |
| D5 | Contradiction aware | 新memory和旧的冲突时要标记,不能默默覆盖 |
| D6 | Zero overhead ingestion | 写入不能阻塞,要能即写即查 |
D5和D6是大多数现有方案的死穴。论文里有张雷达图(Figure 2)非常一目了然——Mem0和Zep在D5(冲突)和D6(写入开销)上几乎是零分,Letta在D2-D5上都是大坑。
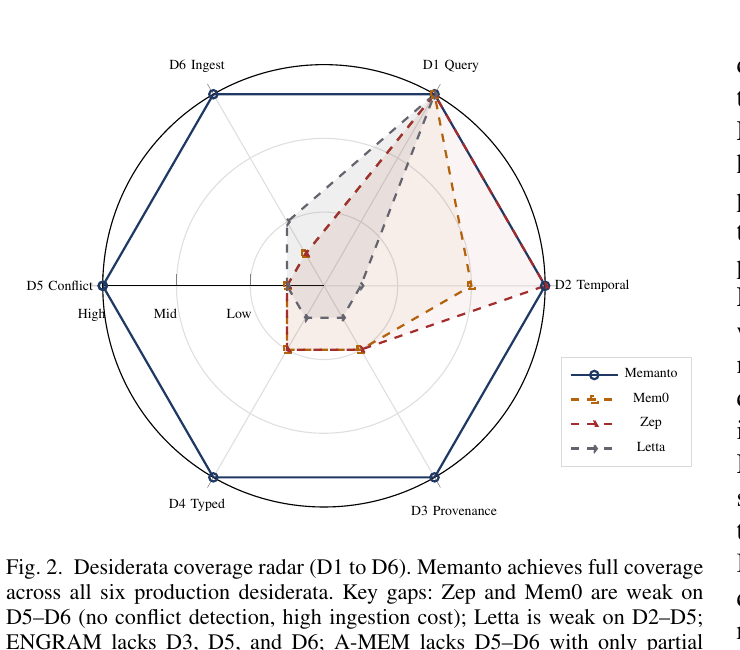
图2:这张图我觉得是Memanto在打"产品舆论战"——它把"评估维度"重新定义到了对自己有利的方向(不只是benchmark分数,而是六个生产级要求)。但平心而论,这六条desiderata提得是真有水准的,每条都对应过我自己踩过的坑。
13类typed memory schema
这部分我之前在做内部Agent项目的时候也试过类似思路,但我们当时只分了4类。Memanto拉到了13类,算是把"语义类型驱动的检索"做到了一个极致:
| 类型 | 含义 | 优先级信号 |
|---|---|---|
| fact | 客观可验证信息 | 稳定、高置信度 |
| preference | 用户/系统偏好 | 中度衰减 |
| decision | 影响未来的选择 | 高持久性 |
| commitment | 承诺/义务 | 时间敏感 |
| goal | 待达成目标 | 直到完成都激活 |
| event | 历史事件 | episodic、衰减 |
| instruction | 规则/指令 | procedural、持续 |
| relationship | 实体关系 | 类graph、稳定 |
| context | 情境信息 | 高度时序 |
| learning | 经验教训 | 累积型 |
| observation | 观察到的pattern | 统计性、演化 |
| error | 要避免的错误 | 持久护栏 |
| artifact | 文档/代码引用 | 引用指针 |
实际效果是两层的:一是检索时可以按type过滤(agent明确说"给我看所有commitment"),二是隐式的优先级和衰减信号会被检索引擎拿来加权。
有个细节我必须提一下——目前的type分配是写入时由用户/调用方手动指定的,论文的Appendix里直接承认了"自动type分配作为future work"。这其实是一个挺务实的实现妥协,但你装了pip install memanto之后,每次调remember接口都得自己带上type参数。
Moorcheh ITS引擎:真正的底牌
整个Memanto的"零ingestion延迟"和"sub-90ms检索",全靠下面的Moorcheh Information Theoretic Search引擎撑着。这是同一个团队2025年发的工作[Abtahi et al., 2025],Memanto是它的应用层。
ITS引擎做了三件事:
1. Maximally Informative Binarization(MIB):把高维浮点embedding压成二值表示,32倍压缩率,论文声称retrieval-relevant signal零损失。这是它能做到"无索引"的关键——二值向量做穷举搜索的成本足够低。
2. Efficient Distance Metric(EDM):用一个信息论度量替代余弦相似度。核心思路是把"chunk对query的相关性"转化为"chunk能减少多少query上下文的不确定性",而不是几何空间里的角度。
3. Information Theoretic Score(ITS):归一化到[0,1]的相关性分数,确定性检索——同一个query永远返回同一组结果。这一点对监管严格的场景(金融、医疗)特别关键,HNSW那种ANN方案在并发更新下会有结果抖动。
我对这块持中性偏正面态度:二值化压缩+穷举搜索的思路在搜推领域不算新(参考bitwise hashing那一脉),但把它包装成"agentic memory专用"+"零索引延迟",确实切中了一个真问题——HNSW类ANN索引的rebuild确实会让"即写即查"很难做。
论文给的MAIR benchmark数据:64-74% NDCG@10、9.6ms距离计算延迟(PGVector和Qdrant是37-86ms)、2000+ QPS。这些数字我没法独立验证,但量级看起来合理。
系统架构:FastAPI服务+三个端点
整体架构分前端和后端两块。前端是agent ecosystem(IDE集成、CLI、自定义agent、本地dashboard)通过CLI/REST/Status接入Memanto Gateway:
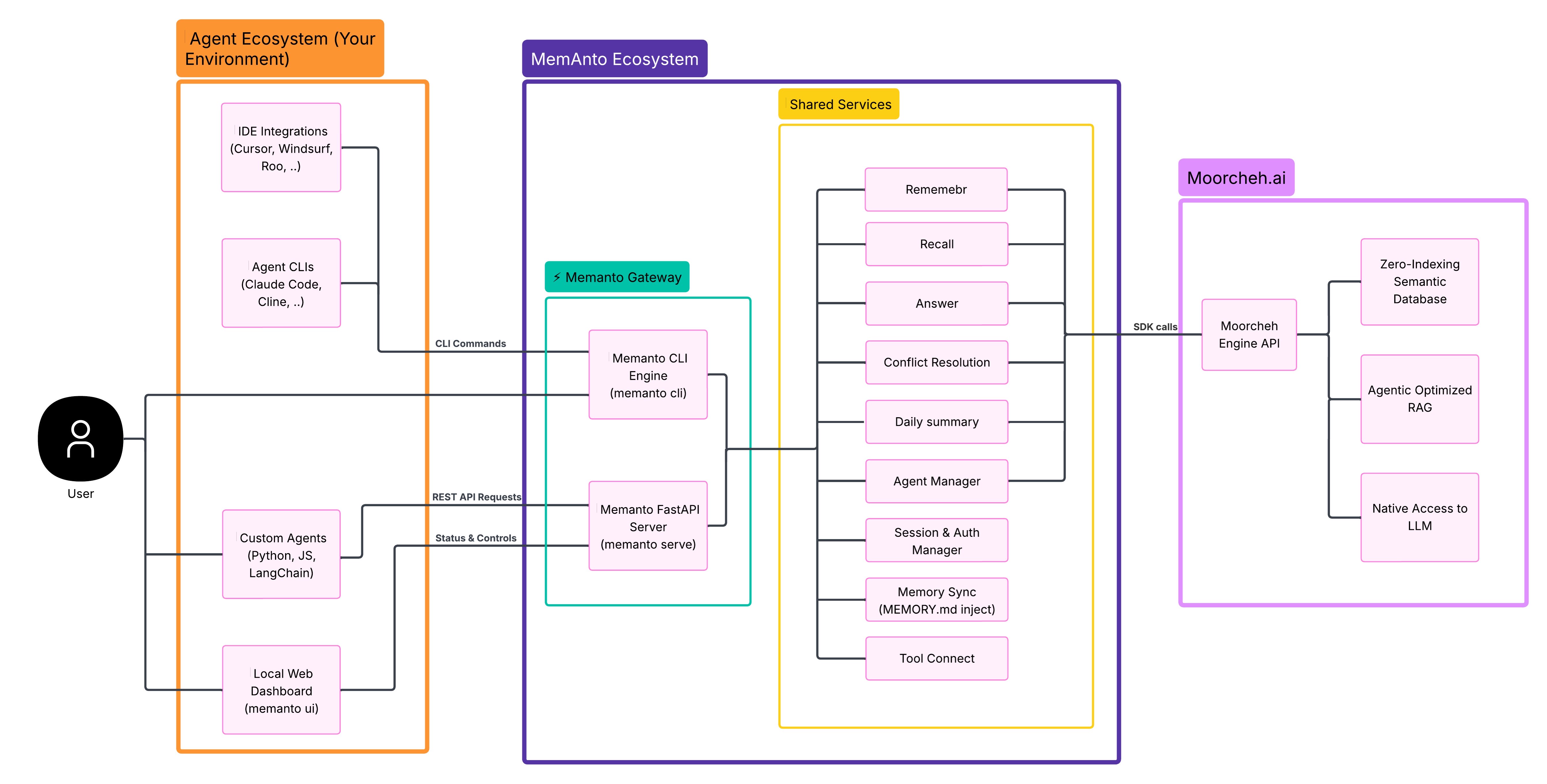
图3:架构本身没什么特别,就是一个标准的FastAPI服务+CLI双入口。但有意思的是它把"Memanto"定位为一个"专门服务于其他Agent的Memory Agent"——说到底是把记忆能力做成了一个外挂的微服务。
后端的Shared Services层有9个内部服务,前6个直接走SDK调Moorcheh Cloud:
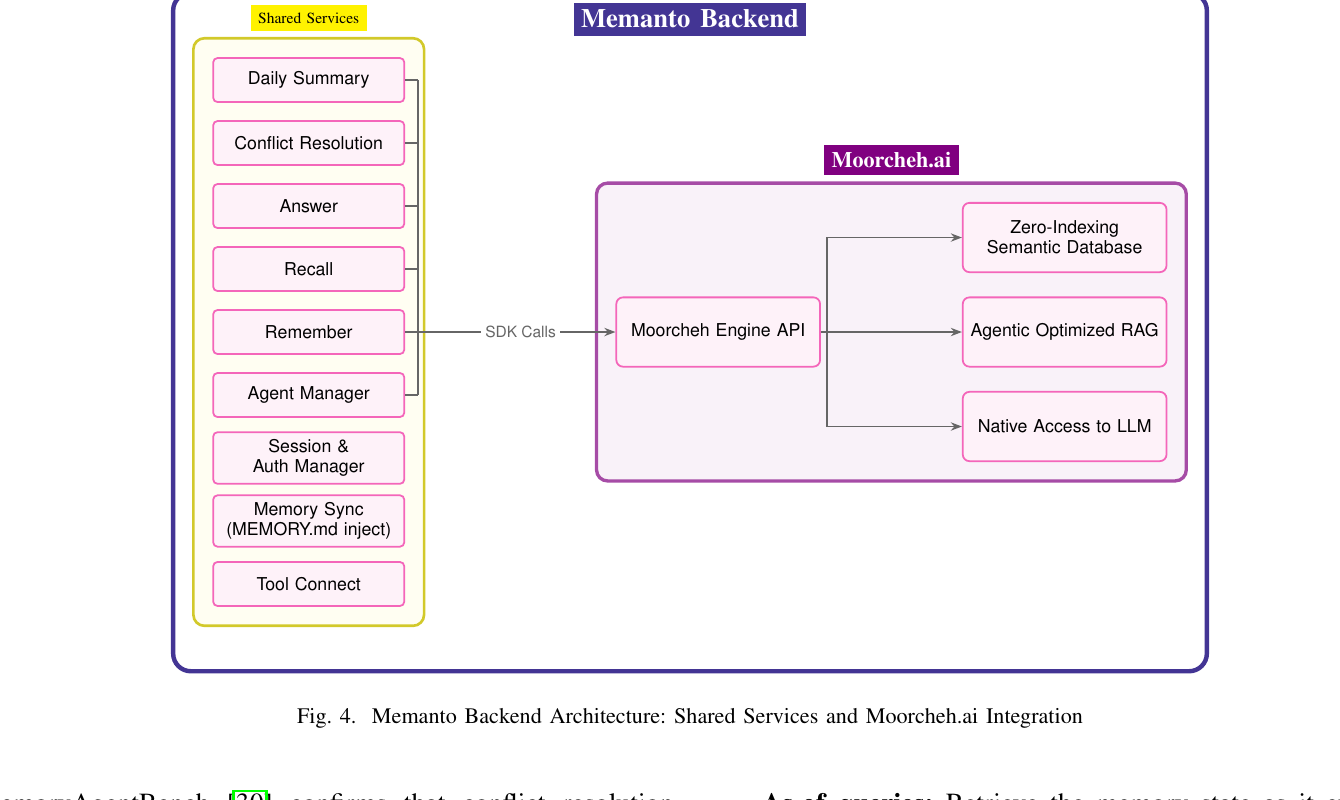
图4:注意Memory Sync这个组件——它会把记忆同步到一个本地的MEMORY.md文件,这是为IDE-based agent(Claude Code、Cursor、Cline这些)准备的"人类可读+机器可查"的双视图设计,挺贴合实际工作流的。
三个核心endpoint: - /remember:写入memory,自动typing/tagging/timestamping,带冲突检测 - /recall:用ITS做语义检索,可配阈值和k - /answer:完整RAG,在检索结果上加LLM推理
冲突检测:被低估的生产刚需
这是我个人觉得Memanto相对其他方案最大的差异化。其他系统在多session场景下,旧记忆和新记忆冲突时基本是默默overwrite,时间一长就出现作者命名的"constraint drift"——agent的世界模型逐步崩坏。
Memanto的处理方式:当新memory和同namespace下同type的旧memory语义相似度超过冲突阈值时,主动block写入,把冲突推给agent决策——三个选项:supersede(取代)、retain(保留旧的)、annotate(两个都留,打冲突标记)。
我之前做长程Agent的时候,就是吃过这个亏——用户说"把会议改到周三",agent记下了,但旧的"会议在周二"那条没被废弃,后面查日程的时候两条都被retrieve出来,agent就懵了。Memanto这套机制相当于在写入侧就把这个问题截断了。
论文还引了MemoryAgentBench[Hu et al., 2026]说"所有现有方法在multi-hop冲突场景上都失败"——这是他们刻意挑出来打对手的弱点。
时间版本化
Memanto支持三种时间查询: - As-of:在某个历史时间点的memory状态(审计回溯) - Changed-since:某个时间区间内新增/修改的memory - Current-only:只返回未被supersede的memory
Memory supersession是non-destructive的——被取代的条目不删除只标记,整个时间线可重建。这在合规场景(金融、医疗)是硬刚需。
实验:5阶段消融把"图谱无用论"说透了
整个IV节核心就是一张消融图。先看结论:
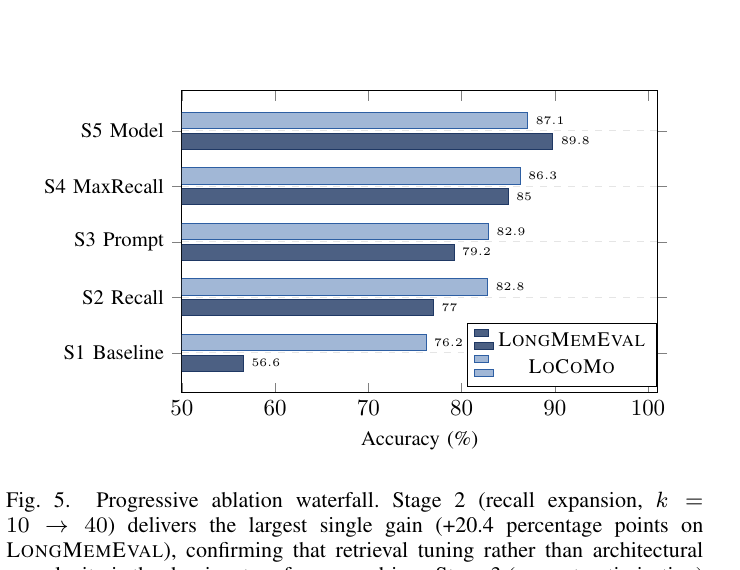
图5:注意看S2和S3的对比——参数从k=10改到k=40,一步白涨20.4个点;prompt死磕优化只换来2.2个点。这两个数字摆在一起,说服力比任何文字都强。
具体每一阶段:
Stage 1(Naive Baseline):k=10、threshold=0.15、Claude Sonnet 4 - LongMemEval 56.6% / LoCoMo 76.2%
为啥两个benchmark差这么多?论文给了一个挺有意思的解释:LongMemEval的query更长、跨topic更多,相关signal被分摊到更宽的embedding空间,相似度分数被压低,0.15的阈值卡住了关键chunk。这其实是一个很值得记住的工程经验——threshold并不是越严越好,要看query结构。
Stage 2(Recall Expansion):k扩到40、threshold降到0.10 - LongMemEval 77.0% / LoCoMo 82.8% - LME +20.4 pp,是整个消融里最大的单步gain
这个发现总结成一句话就是:Agentic memory里,召回压倒精度。把更宽更乱的candidate set丢给LLM,让它用in-context reasoning自己筛,比在retrieval层做精准卡点要划算得多。
我看到这个数据时有点皱眉——20.4个点的gap只靠调k?这意味着Stage 1的那些baseline在做不公平的比较。但反过来想,如果其他论文的baseline也是用了类似的"naive配置",那Memanto的核心insight就成立了:整个领域可能都在精度过滤上钻牛角尖。
Stage 3(Prompt Optimization):换Hindsight的优化prompt - +2.2 pp / +0.1 pp,几乎没变
Finding: 当retrieval层把相关内容拿不出来时,任何prompt工程都补不上这个结构性缺陷。这话说得有点重,但确实是大模型时代的真理。
Stage 4(Maximum Recall):k扩到100,threshold降到0.05 - +5.8 pp / +3.4 pp
Stage 3失败case分析发现,错误不是出在LLM被噪声淹没(lost-in-the-middle),而是出在关键句子根本没被召回。所以继续放宽召回,效果继续涨。
Stage 5(Inference Model Upgrade):Claude Sonnet 4 → Gemini 3 - +4.8 pp / +0.8 pp,到达最终89.8% / 87.1%
这一步主要是为了和竞争对手的model对齐做公平比较。论文这里挺老实的,直接写了:Gemini 3贡献了最终成绩的4.8 pp,模型本身的能力依然是大头。
k vs accuracy曲线
下面这张图给了Stage 2-4的连续视角——k从10到100,accuracy和token cost的trade-off:
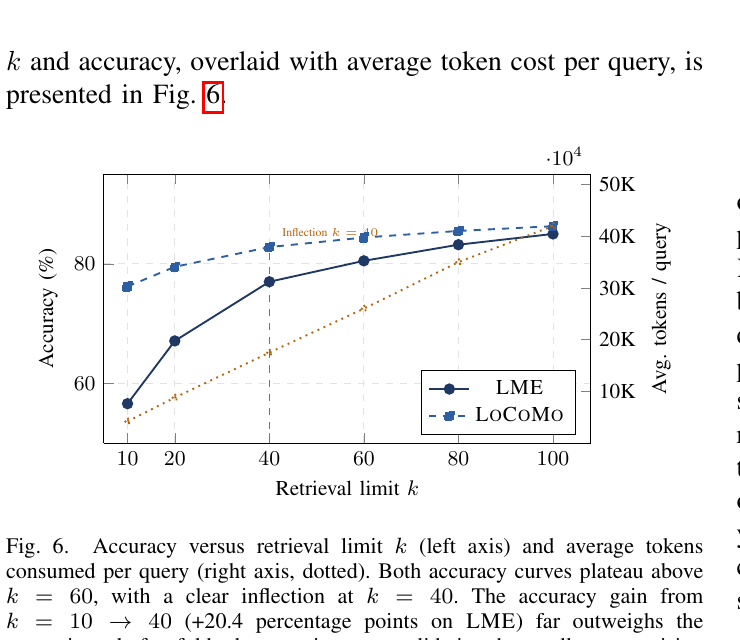
图6:这张图最关键的信息是k=40那个拐点。如果你在做生产部署,最佳实践就是把k放到40左右——再大就是边际效益骤降。
最终对比表
下面这张是和所有对手的对比,自家在LongMemEval上是vector-only里的第一,整体只输给Hindsight:
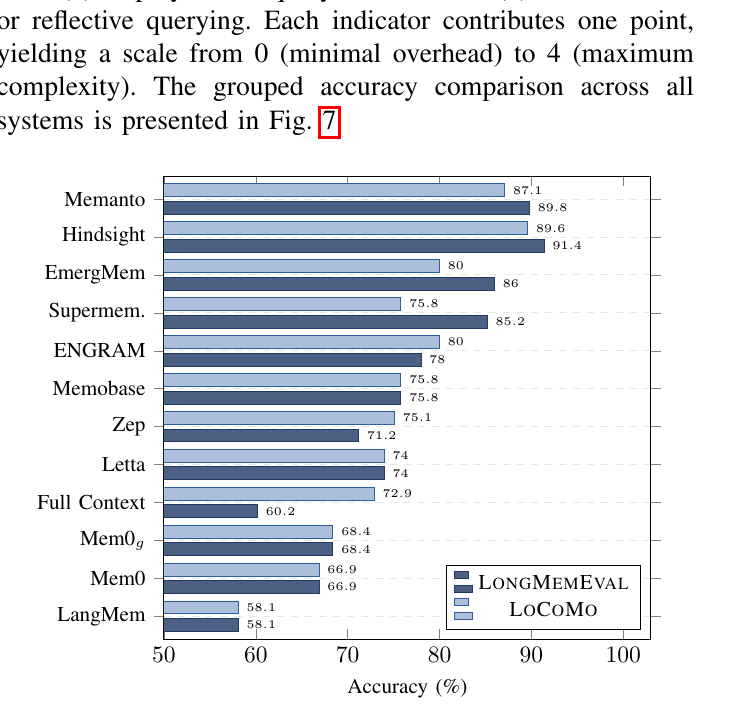
图7:Hindsight在LME上确实比Memanto高1.6 pp(91.4 vs 89.8),但代价是4/4的复杂度。这种"用工程复杂度换精度"的trade-off在生产环境里很多时候是不划算的。
Memanto各类别分项
LongMemEval分6类——Memanto在Single-session Assistant类做到100%,Multi-session最低81.2%。这个分布挺合理的,跨session合成本来就是最难的。
LoCoMo分4类——Open Domain最高92.4%,Multi-Hop最低70.8%。多跳推理是vector-only方案的天然弱项,这是预期内的。
| LongMemEval类别 | 准确率 | LoCoMo类别 | 准确率 |
|---|---|---|---|
| Single-session User | 95.7% | Single-Hop | 78.7% |
| Single-session Assistant | 100.0% | Multi-Hop | 70.8% |
| Single-session Preference | 93.3% | Open Domain | 92.4% |
| Knowledge Update | 93.6% | Temporal | 85.4% |
| Temporal Reasoning | 88.0% | Overall | 87.1% |
| Multi-session | 81.2% | ||
| Overall | 89.8% |
Memory Tax量化对比
这个表是论文最务实的部分——把成本算清楚:
| 系统 | 写入LLM调用 | 检索LLM调用 | 基础设施 | 写入延迟 | 空闲成本 |
|---|---|---|---|---|---|
| Memanto | 0 | 1 | Moorcheh向量DB+API key | <10ms | 零 |
| Mem0 | 1 | 1 | 向量DB | ≈500ms | 固定 |
| Mem0g | ≥2 | ≥2 | 向量DB+Neo4j | ≈2s | 固定 |
| Zep | ≥2 | ≥2 | 向量DB+Graph | ≈3s | 固定 |
按10K daily memory operations估算,Memanto日成本\(0.50,Mem0g是\)2.32,Zep是\(1.70。**单agent年化能省\)662**——如果你在做企业级agent fleet,几百个agent堆起来这个数就很可观了。
我的几个判断
1. 这篇论文的真实定位:工程整合,不是底层突破
论文的核心创新是Moorcheh ITS引擎,但ITS本身是同一团队2025年的工作,这篇是它的应用层包装。Memanto做的事情更像是把ITS引擎+typed schema+conflict detection打包成一个面向Agent的产品形态。
这不是贬义。把"已经有的好东西"组合成"生产可用的好产品"本身就是有价值的工程工作,并且对整个领域有"指明方向"的作用——它用一个干净的消融实验把"图谱必要性"这个普遍迷思戳破了。
2. "Recall压倒Precision"是真insight,但要小心适用边界
k=10→40换20.4个点,这个数字确实很震撼。但也要看到:
- LME和LoCoMo都是对话型benchmark,单session token不算特别夸张(LME约115K,LoCoMo约9K)
- 当你做的是百万token级别的长程Agent(比如code agent操作一个大型repo),把k扩到100可能会让context爆掉
- LLM的in-context filtering能力在Gemini 3和Claude Sonnet 4这种顶级模型上很强,但小模型会怎么样?论文没测
我的判断:在对话和personal assistant场景下,"recall over precision"这个原则可以直接照搬。在code agent或者research agent场景下,可能还得做一层reranking才安全。
3. ITS引擎的"零索引"是一把双刃剑
二值化+穷举搜索的好处是写入即查,没有HNSW的rebuild问题。但穷举搜索的复杂度是O(N),在Memanto声称的10M+文档+2000 QPS这个规模上,这意味着要做大量的并行优化(SIMD指令、GPU加速等等)。
论文没具体讲这块的硬件配置,只说"4 CPU cores + 8GB RAM"。这个配置能跑10M文档的穷举搜索吗?我严重怀疑——大概率是论文里那个配置只针对小到中等规模的场景。如果你打算把Memanto直接上百万级文档,需要先压一下他们的实际部署细节。
4. 13类typed schema的可扩展性
Memanto固定了13类。但Agent生态的多样性很可能让这个固定schema变成限制——比如医疗Agent可能需要"诊断"、"用药"这种特殊type,code agent可能需要"代码片段"、"错误堆栈"这种。
论文里type assignment还是手动指定的(write-time由调用方传入),自动type分配作为future work。这个设计目前对开发者是有心智成本的——每次调remember接口都要选type,用错了召回就跑偏。
我的预测:未来一定会有人做"自动type分类"的简化版本,要么用一个轻量分类模型,要么直接让大模型来判断。Memanto如果不主动迭代这块,会被竞品吃掉这个差异化。
5. 冲突检测是产品差异化的真正护城河
老实说,Memanto的vector-only架构本身没什么技术壁垒——任何团队拿一个好的embedding模型+一个支持二值检索的向量库(MILVUS、ScaNN这些都行)都能复刻七七八八。真正难复刻的是它的冲突检测产品化设计——semantic similarity matching + 三种resolution选项 + 与时间版本化系统的集成。
这一块是要把Agent当作"产品"而不是"算法"来思考的工程师才做得出来的。如果你也在做Agent的长记忆,这部分是值得借鉴的。
6. 论文的局限性,作者自己也说了
作者在Limitations部分挺坦诚的,几个点我觉得很关键:
- Benchmark饱和:LongMemEval和LoCoMo大概各有5-7%的标注不一致,对手都在快速逼近这个上限——也就是说,这两个benchmark的区分度正在快速衰减
- Benchmark scope:只测了对话场景,code agent/research agent/multi-agent coordination这些完全没测
- Inference model依赖:Gemini 3贡献了4.8 pp。换个稍弱的模型分数可能立刻掉
- Scale evaluation:千级并发agent的测试还没做
工程启发:如果我现在要做Agent记忆系统
如果你正在团队里做Agent的长记忆,看完这篇我会给三条建议:
第一,先把recall扩起来再想精度。如果你现在k=5或者k=10,先调到40试试。论文里20.4 pp的gap可能不会全部复现,但5-10个点的提升大概率是能拿到的。
第二,引入typed memory和冲突检测。即使你不用Memanto,也应该把memory按type分桶,写入时检查冲突。这两件事对长程Agent的稳定性提升是质变级别的。
第三,HNSW不是唯一选项。如果你的Agent需要"即写即查",调研一下二值化向量+穷举搜索的方案。在百万级文档以下,这条路的工程复杂度可能比HNSW + 异步rebuild低得多。
至于要不要用Memanto本身——它有pip包(pip install memanto),但绑定了Moorcheh.ai的cloud服务(要API key)。这是一个云服务+SDK的商业模式,不是真正可自部署的开源方案。如果你的团队对数据外发敏感,可能更适合自己实现一遍它的核心思路。
最后一段碎碎念
我看完Memanto最大的感受是:Agent记忆这个赛道终于有人开始做减法了。
过去一年大家都在堆——堆图谱、堆reflection、堆multi-query、堆recursive。Memanto反过来证明了一件事:当底层的retrieval engine足够好的时候,上面那些复杂的pipeline其实是可以砍掉的。
这件事让我想起RAG刚兴起那两年,整个圈子都在堆reranker、堆query expansion、堆HyDE这些花活。然后2024年开始大家发现,把retrieval的recall做扎实,加上一个稍强的LLM做in-context filtering,比堆一堆中间组件要简单也要有效。
Agent记忆的故事可能也是同样的弧线——从"堆图谱"到"做减法",从"复杂pipeline"到"高质量的单次retrieval"。
Memanto可能不是最终形态,但它指出了一个正确方向。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新AI前沿,关注我