Agent-World:当智能体训练终于不用再"假装"在跟世界打交道
最近调一个 MCP-based 工具调用智能体的时候,我又一次碰到了那个老问题:在内部沙盒里 reward 跑得贼漂亮,一上 MCP-Mark 这种真实 server 的评测,立刻拉胯。文件改坏了、订单走漏了一步、状态没追上来——一连串现实里 agent 必须处理的细节,全是训练数据里从没出现过的。
Agent RL 这两年发力很猛,但有个绕不开的瓶颈,就是真实有状态的训练环境太稀缺。模型在 toy 环境里学会的"工具调用",到了真实 MCP server 跟前几乎像是另一种语言。Agent-World 这篇论文给我的感觉是,它没在 RL 算法上玩花样,而是把问题往后推了一步:先把一个真正接近现实的 agent 训练场建出来——1978 个真实环境、19822 个工具,再让 agent 在这个不断扩张的训练场里持续做"自我诊断 → 定向补课"的闭环。
读完之后我的第一反应是:这是把"环境本身"当成可扩展资产、而不是把 RL 算法当成主角的一种思路。值不值得深挖?我觉得值,尤其是你正在做通用 agent 的话。
核心摘要
LLM 越来越被期待变成"通用 agent"——不是聊天,是真的去操作 MCP server、改数据库、跑工具链。但训练通用 agent 现在有两个拦路虎:一是没有足够多、足够真的有状态环境;二是没有机制让 agent 在训练过程中持续发现自己哪里不会,再针对性补课。
Agent-World 提出了一个组合拳:(1) Agentic Environment-Task Discovery——用一个 deep-research agent 自动从 web 上挖主题对齐的真实数据库、生成可执行工具集,再用图遍历和程序合成两条路径合成可验证任务;(2) Continuous Self-Evolving Agent Training——多环境 RL + 一个会动态出题的"自演化竞技场",由诊断 agent 找出当前 policy 的弱环境,定向重生成训练数据,再继续训。
效果上,Agent-World-8B/14B 在 23 个 benchmark 上稳压一众环境扩展类 baseline,在 BFCL V4 上 14B 版本 55.8% 甚至追平 DeepSeek-V3.2-685B(54.1%)。环境数量从 0 → 2000 时,平均分从 18.4% 提到 38.5%,扩展曲线非常清晰。
我的判断:算法层(GRPO 直接拿来用)几乎没有创新,但环境工程层做得相当扎实。这是典型的"把脏活累活做透就能拿到结构性优势"的路子,对正在做 agent 落地的团队,参考价值不在于 RL 公式,而在于环境数据的产线设计。
论文信息
- 标题:Agent-World: Scaling Real-World Environment Synthesis for Evolving General Agent Intelligence
- 作者:Guanting Dong, Junting Lu, Junjie Huang, Wanjun Zhong, Longxiang Liu, Shijue Huang, Zhenyu Li, Yang Zhao, Xiaoshuai Song, Xiaoxi Li, Jiajie Jin, Yutao Zhu, Hanbin Wang, Fangyu Lei, Qinyu Luo, Mingyang Chen, Zehui Chen, Jiazhan Feng, Ji-Rong Wen, Zhicheng Dou
- 机构:中国人民大学高瓴人工智能学院,字节跳动 Seed
- 日期:2026-04-20
- 链接:arXiv:2604.18292

图 1:Agent-World 概念架构与扩展曲线。左侧的循环展示了"环境合成 → 任务合成 → 多环境 RL → 自演化诊断"的闭环,右上的柱状图对比了 8B/14B 模型与 235B、685B 大模型;右下显示训练环境数量带来的近乎线性的能力增长。
为什么这事值得做:现有环境合成的两个硬伤
先说清楚问题。Agent RL 的算法(PPO / GRPO / DAPO)这一两年其实挺成熟了,瓶颈反而是数据——更具体地说,是有状态、可执行、能验证的多轮交互数据。
主流做法分两条路:
第一条是 simulator 派。让 LLM 自己"扮演"环境,模拟每次工具调用的返回。代表是 webworld、sim 系列。优点是无限可扩展,缺点是 LLM 一旦没见过的领域就开始幻觉,agent 在里面学到的"经验"很大概率是 LLM 自己的偏见。
第二条是 programmatic 派。用数据库 + 可执行 Python 工具搭真实沙盒。代表是 EnvScaler、AWM、AutoForge。这条路真实性高,但工具链通常依赖少数开源 SDK,复杂度上不去,agent 一旦面对 GitHub / Notion / Postgres 这种真实 MCP server,立刻原形毕露。
Agent-World 直接指出第二条路存在的两个真实痛点:
痛点一:环境要么是 LLM 凭空编的,要么靠少量开源工具拼凑,跟真实交互逻辑差距大,而且复杂度上不去,长程、状态密集的任务训不出来。
痛点二:环境构得再多,没有机制告诉你 agent 现在哪里不会,更别说定向补课了。"造环境"和"用环境训"是断开的两件事。
我自己之前做过类似的工作——给 agent 跑一些自动合成的工具任务。最大的感受是:任务越合成,越漂亮,越像实验室;上线一跑,一堆"逻辑没毛病但完全不像人类会问"的任务。这种数据训出来的 agent,在线上分布偏移面前会很脆。
Agent-World 这篇关键的判断是:真正有价值的环境,得直接锚到现实世界本身。它的做法是从 Smithery 这样的 MCP 注册表起步,再让 agent 自己跑去 web 上挖真实数据库、生成可执行工具——而不是让 LLM 凭空编一个 fake server。
方法核心
Agent-World 的整体设计可以拆成两块拼图:环境–任务发现和自演化训练。
拼图一:Agentic Environment-Task Discovery
这一块是整篇论文最值钱的工程贡献。它把"造环境"这件事变成了一个 agent 自动化流水线,核心步骤是这样的:

图 2:Environment-Task Discovery 完整流水线,从主题采集到任务生成全自动。下半部分给出了一个 Memory Bank MCP Server 的具体例子,包含文件结构、工具 schema 和任务/校验脚本。
Step 1:环境主题采集
光靠 LLM 想象主题肯定不行。论文从三个来源采集了 ~3.5K 个种子主题:
- MCP Servers(~2.8K):直接抓 Smithery 上的真实 MCP server 规格,每个都带结构化 JSON 描述。
- Tool Documentations(~0.5K):扫开源 tool-use 数据集,把工具反向映射到主题。
- Industrial PRDs(~0.2K):用产业 PRD 文档作为主题锚,因为 PRD 自带行业背景和系统接口。
这一步是"真实性"的关键来源——所有后续合成都锚在真实的 MCP / 工具生态上,不是凭空捏的。
Step 2:Agentic Database Mining
给定一个主题,启动一个装备了 search、browser、code interpreter、OS 工具的 deep-research agent \(\mathcal{G}\),让它自动去 web 上挖结构化数据,然后用 OS 工具落盘成可查询的数据库:
但单次挖出来的 DB 通常太单薄,所以又叠了一个database complexification 步骤 \(\phi\),迭代 N 轮把数据库扩张、丰富:
我觉得这个细节挺重要的——很多人做合成数据,第一遍跑出来不行就直接放弃了。Agent-World 的处理是"再让 agent 想想还能补什么",相当于把 deep research 的 iteration 显式化。
Step 3:工具生成与验证
DB 有了,工具集还得生成。再起一个 coding agent \(\psi\),给它 (主题, DB),让它产出工具实现 + 单元测试集:
每个工具至少要满足三条才能保留:(1) Python 编译通过;(2) 测试集通过率 \gt 0.5;(3) 该环境至少有一个有效工具+一个有效测试。这个过滤其实挺严的——0.5 的门槛把模糊地带的工具直接砍掉了。
Step 4:分层环境分类
还有一件特别细心的事:把环境按层级聚类。先用 hierarchical clustering 聚成 50 个二级类,然后人工合并到 20 个一级类。最终:20 个一级类 / 50 个二级类 / 1978 个三级环境。

图 3:环境分类体系覆盖面。能看到分布是真的杂——从 DevOps、API 网关、Web 提取,到云平台、关系型数据库、消息通知、代码执行……几乎是真实工业环境的一个缩影,而不是合成数据典型的"长尾稀疏"。
这里有个我比较欣赏的点:分类不是为了好看,是为了后面分层采样做评测竞技场——你要诊断 agent 哪里不会,至少得知道每一类环境的覆盖度,否则诊断出来的"弱点"可能只是采样偏差。
Step 5:可验证任务合成(两条腿走路)
环境有了,任务怎么来?论文用了两种互补策略:
(a) Graph-Based Task Synthesis——先合成有效的工具调用序列,再"逆向"出任务描述。
为每个环境构建一个工具图 \(G = (V, E)\),节点是工具,边表示调用依赖: - 强依赖(\(w=3\)):B 的输入严格依赖 A 的输出(比如 create_order → get_order_details); - 弱依赖(\(w=2\)):B 的输入可以来自 A,也可以从其他途径拿; - 独立边(\(w=1\)):无参数依赖,纯粹保证图连通。
然后在图上做有偏 random walk,权重越大越容易被选中。走出来的工具序列 \(\tau\) 进沙盒执行,根据真实返回的字段格式,让 LLM "反向"写一个完全不暴露工具名和 schema 的自然语言任务描述 \(q_{final}\),同时生成 JSON 标准答案 \(a^*\) 和评分 rubric \(R\)。
任务难度怎么扩?加长 random walk 的最大步数 + 提高弱依赖/独立边的采样概率 + 重写描述去掉所有暴露线索——逼 agent 必须从抽象目标里推出工具链。
(b) Programmatic Task Synthesis——直接生成可执行 Python 解题脚本。
graph-based 方法擅长线性流程,但真实任务经常需要条件分支、循环、聚合。所以加了一条程序合成路径:让 LLM 给定工具 schema,先生成一个复杂任务,再生成一段端到端 Python 解题脚本(带 for / if-else / 统计聚合)。脚本在沙盒里跑通就拿到 ground truth,再生成一段 verification script \(V_{code}\) 用来评估候选答案。
不管哪条路径,论文都强制要求至少 5 次独立 ReAct 解答中有 2 次成功才保留任务,确保任务"难,但还是可解的"。
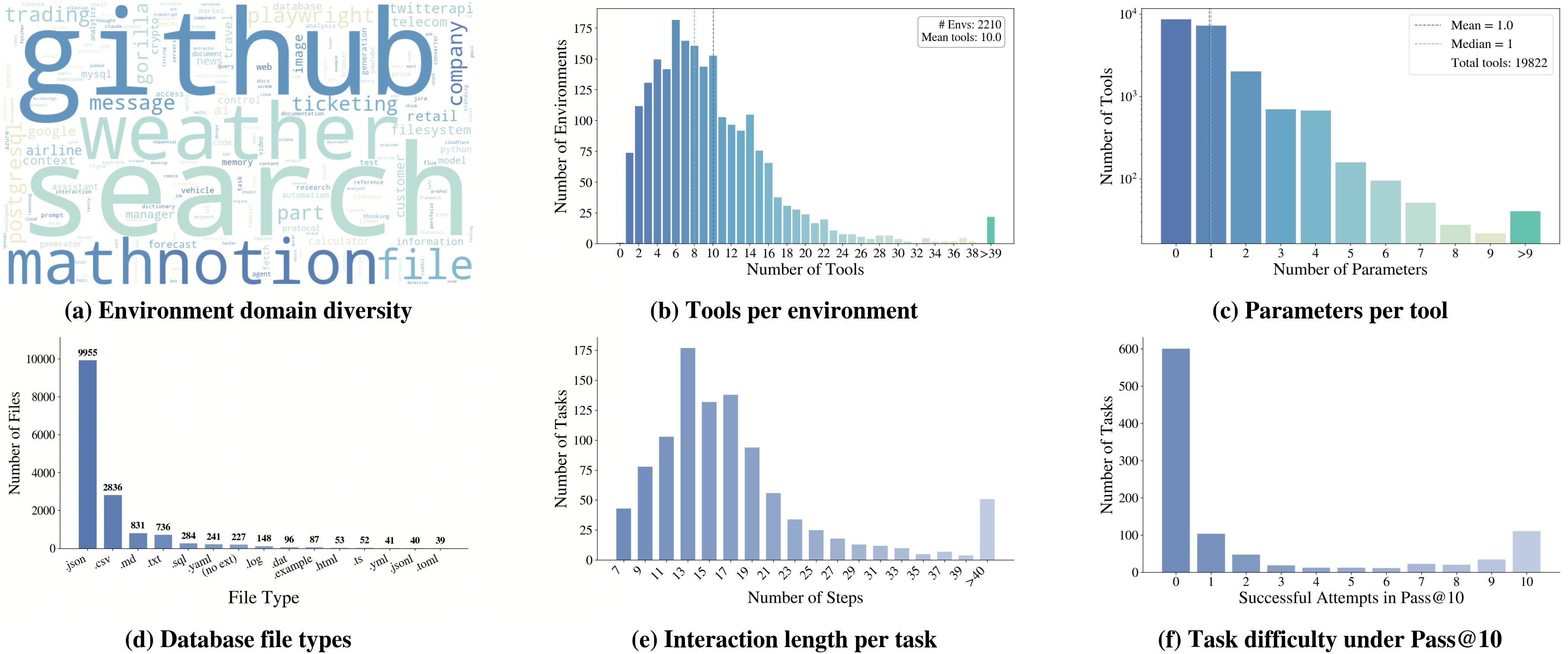
图 4:六个子图揭示了 Agent-World 数据的几个特点——环境多样性高、工具丰富、数据库格式贴近真实、任务交互长且难。最值得说的是 (f):在强模型 Pass@10 测试下,大量任务依然失败率极高,说明合成的不是"刷分玩具",是真有挑战。
拼图二:Continuous Self-Evolving Agent Training
环境和任务造好了,怎么用?这是 Agent-World 的第二个核心。

图 5:Self-Evolving Agent Training 的两个组件。Multi-Env RL 强调的是"agent–tool–database"三体闭环;Arena 强调的是把环境生态本身变成持续诊断与补课的工具。两者通过 RL 阶段衔接,形成真正意义上的 co-evolution loop。
多环境 Agent RL
Rollout 闭环涉及三个组件:(1) policy model \(\pi_\theta\) 决定下一步动作;(2) tool 接口/runtime 在沙盒里执行;(3) DB state 作为可读写的状态底层。
每一步 agent 同时输出 reasoning 和 tool/action 决策,工具调用直接修改 DB 状态。每个 batch 里每条任务都对应独立且动态的环境,这是它跟单环境 tool-RL 工作的核心差异。
Reward 设计特意做了状态感知。两类任务用两套 reward:
graph 任务用 LLM-as-judge 按 rubric 逐条打分,全过才得 1;程序任务直接跑 verification 脚本验证答案/状态。
需要说一句,这里 reward 是 0/1 的硬阈值——graph 任务必须全部 rubric 过,programmatic 任务必须验证脚本通过。这种 sparse reward 配合 GRPO 一般是比较难训的,但论文后面 training dynamics 显示 reward 还在稳定上涨,说明任务难度梯度做得相对合理。
Policy update 用的是 GRPO,没换花样。Clip 比沿用 DAPO 的 \(\varepsilon_{low}=0.2\)、\(\varepsilon_{high}=0.28\)(不对称 clip 防止熵塌),最大 trajectory 80K token,每步 32 任务 × 8 rollout。
自演化 Agent Arena
这是论文比较"自演化"那个概念的关键。
怎么搭 arena:从 20 个一级类里每类抽 K=5 个环境,组成评测集 \(\mathcal{E}_{\text{arena}}\)。这种分层采样保证覆盖度同时控制成本。
怎么动态出题:每一轮 \(r\),对 arena 里每个环境重新合成一批新任务——既有 graph 也有 programmatic。关键是任务和环境每轮都变,避免过拟合到固定测评。
怎么诊断:跑完测评后,启动一个 diagnosis agent \(\delta\)(带 Python interpreter 和 search 工具),让它分析失败 trace: - 输入:每个 task 的失败 trace、环境维度的错误统计、环境元数据; - 输出:(a) 排序的弱环境集合 \(\mathcal{W}^{(r)}\);(b) 每个弱环境的"任务生成指南" \(\mathcal{G}^{(r)}_{\text{guide}}(m)\),明确说"这个环境 agent 主要错在状态更新、那个环境主要错在工具选择"。
怎么定向补课:拿着诊断报告,回到环境–任务发现流水线(甚至会触发数据库 complexification 把环境本身搞复杂),合成针对性训练集 \(\mathcal{X}^{(r)}_{\text{target}}\),再继续 RL:
整个 loop 把可扩展环境变成了一台自动化课程引擎——agent 哪里弱,环境就在哪里"长出"新任务来折腾它。
我看到这套设计的时候,第一反应是"这其实就是把 active learning + curriculum learning 在 agent RL 上实例化了一遍"。但关键不在于这个想法新不新,而在于它的诊断 → 定向出题这个 loop 真的能跑通,且能持续涨点。下面的实验数据其实就是来回答这个问题。
实验:23 个 benchmark 的"拷打"
实验做得相当全。基线包含三组:
- 闭源前沿:GPT-5.2 High、Claude Sonnet-4.5、Gemini-3 Pro、Seed 2.0;
- 开源大模型 8B–685B:DeepSeek-V3.2-685B、GPT-OSS-120B、Qwen3-8B/14B/32B/235B-A22B;
- 开源环境扩展方法 7B–14B:Simulator-8B、TOUCAN-7B、EnvScaler-8B、AWM-8B/14B、ScaleEnv-8B。
评测覆盖了 23 个 benchmark,主战场是三个 stateful agentic tool-use 套件:MCP-Mark、BFCL V4、τ²-Bench。
主表:Agent-World 在工具调用上的表现
| 方法 | MCP-Mark Avg | BFCL V4 Avg | τ²-Bench Avg |
|---|---|---|---|
| 闭源前沿模型 | |||
| GPT-5.2 High | 53.1 | 62.9 | 80.2 |
| Claude Sonnet-4.5 | 33.3 | 73.2 | 84.7 |
| Gemini-3 Pro | 50.8 | 72.5 | 85.4 |
| Seed 2.0 | 54.7 | 73.4 | 83.0 |
| 开源大模型 | |||
| DeepSeek-V3.2-685B | 36.7 | 54.1 | 80.3 |
| GPT-OSS-120B | 4.7 | – | 55.0 |
| Qwen3-235B-A22B | 5.8 | 47.9 | 58.5 |
| Qwen3-32B | 7.5 | 46.7 | 44.9 |
| Qwen3-14B | 3.4 | 41.0 | 32.4 |
| Qwen3-8B | 2.4 | 40.4 | 26.2 |
| 开源环境扩展方法 | |||
| Simulator-8B | 2.4 | 23.9 | 31.8 |
| TOUCAN-7B | 1.0 | 36.6 | 17.7 |
| EnvScaler-8B | 5.6 | 47.6 | 37.9 |
| AWM-8B | 2.4 | 40.0 | 34.4 |
| AWM-14B | 5.1 | 42.4 | 39.0 |
| ScaleEnv-8B | – | – | 38.5 |
| Agent-World-8B | 8.9 | 51.4 | 61.8 |
| Agent-World-14B | 13.3 | 55.8 | 65.4 |
几个数值我反复核了一遍,确实让人有点意外:
第一,Qwen3-235B-A22B 在 MCP-Mark 上才 5.8%,比 Agent-World-8B 的 8.9% 还低。单纯堆参数堆不出 stateful 工具调用能力——这事过去半年其实已经被很多工作验证了,但看到 235B 直接被 8B 摁住还是挺扎眼的。
第二,Agent-World-14B 在 BFCL V4 上 55.8%,追平了 685B 的 DeepSeek-V3.2 的 54.1%。当然 685B 是通用大模型不是 agent 专精,但这个对比说明环境扩展 + 自演化训练在 agentic 维度确实把 8B/14B 打出了远超尺寸的效果。
第三,对比同尺寸的环境扩展方法(EnvScaler-8B、AWM-8B),Agent-World-8B 在 τ²-Bench 上 61.8% vs 37.9%/34.4%——整整高出 24 个点。这个 gap 之大已经不是 noise 能解释的了,它表明"环境真实性 + 自演化训练"组合带来的提升是结构性的。
第四,Claude/Gemini 这种闭源前沿在 τ²-Bench 上还是占住了 top(85% 左右),Agent-World-14B 65.4% 离他们差着大约 20 个点。这也算诚实——开源 8B/14B 想吃下闭源 hundred-billion 级模型的全部场景,至少现在还做不到。
扩展性:22 张雷达图说"在哪里都不丢人"
光看 tool-use 当然不够。论文在另外 17 个 benchmark 上做了横向扩展:
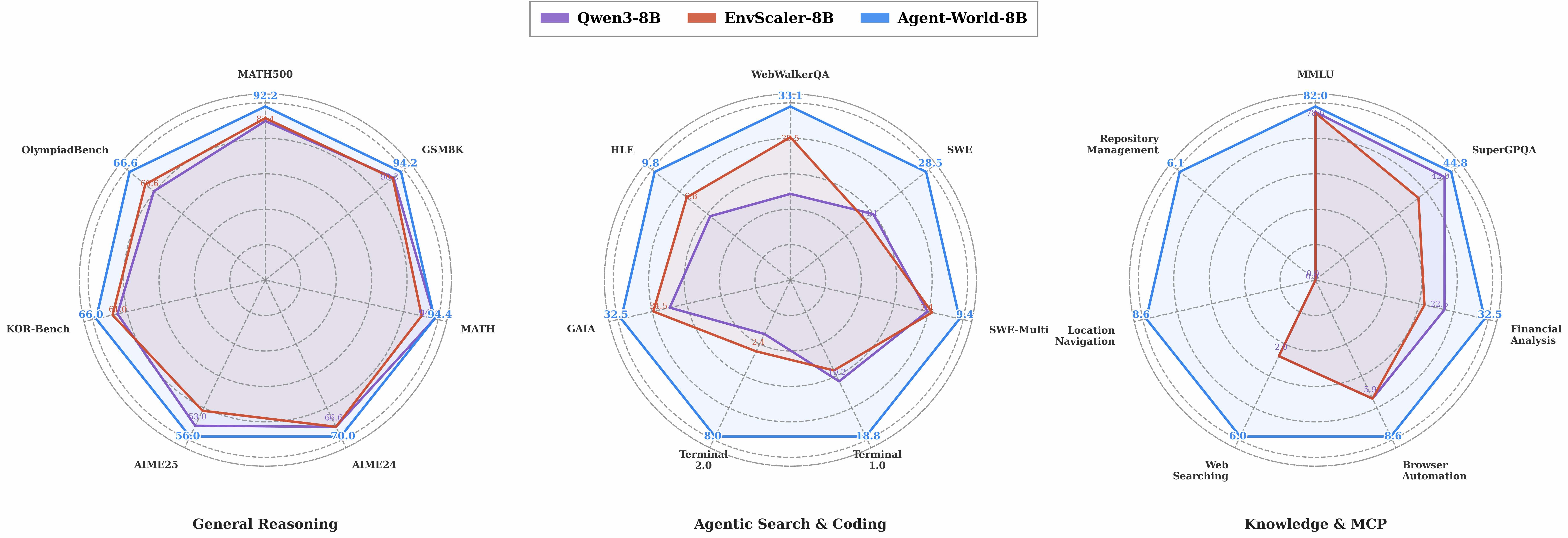
图 6:三个能力维度的雷达对比。最有看点的是 Agentic Search & Coding 一栏——SWE-Bench、Terminal-Bench、GAIA、HLE 这些都是真实软件工程和深度信息检索任务,Agent-World 在这里也领先,说明从"工具调用"学到的能力是真的可迁移,不是 benchmark hack。
我看完这张图之后比较确信的一件事是:Agent-World 的 RL 训练并没有"卷"掉模型的通用推理能力。MATH500、GSM8K、AIME 这些数学 benchmark 上 8B 版本依然保持 90%+ 的水平,证明加 agent RL 不会让基础推理能力塌方——这其实是个挺重要的工程问题,很多 agent RL 工作训完之后通用能力会掉一截。
Advanced AI Assistant:泛化能力压力测试

图 7:在更接近真实助手场景的高难度 benchmark 上,Agent-World 是少有的能在 8B → 14B 上稳定单调提升的方法。这反映了一个被很多人忽略的事实——单纯堆参数不一定能让长程 agent 任务变好,反而可能因为指令遵循/记忆冲突而变差。
环境数量的扩展曲线:典型的 sub-linear 但有效
这是我个人最喜欢的一张图。

图 8:四个子领域上的环境扩展曲线,呈现典型的"前期陡涨 + 后期收益递减但仍正向"的形态。100 → 500 区间增长最猛,2000 之后边际收益变小但没饱和。这个曲线形状基本上跟 LLM 数据 scaling law 的形态一致。
环境从 100 涨到 500 这一段是黄金区间——对于一个新做 agent 训练环境的团队,前期投资 100→500 个真实环境 ROI 最高,后期的 1000→2000 主要是补 fine-grained 的 robustness。
自演化 loop 的实测效果
| 模型 / 轮次 | τ²-Bench | BFCL-V4 | MCP-Mark (Post.) |
|---|---|---|---|
| Agent-World-14B (base) | 60.2 | 52.4 | 29.5 |
| +1 round | 63.5 (+3.3) | 54.9 (+2.5) | 36.3 (+6.8) |
| +2 rounds | 65.4 (+1.9) | 55.8 (+0.9) | 38.1 (+1.8) |
| EnvScaler-8B (base) | 37.9 | 47.6 | 9.5 |
| +1 round | 40.2 (+2.3) | 49.1 (+1.5) | 13.9 (+4.4) |
| +2 rounds | 41.6 (+1.4) | 50.0 (+0.9) | 15.1 (+1.2) |
这张表回答了一个挺关键的问题——self-evolving loop 是不是只对 Agent-World 自己有用?答案是:把同一套 loop 套在 EnvScaler-8B 上,两轮也能涨 +3.7/+2.4/+5.6 个点。说明诊断+定向补课这套机制是可移植的,不绑定 Agent-World 的初始化。
最大的提升出现在 MCP-Mark 上(+8.6%、+5.6%)。这个 benchmark 强调真实 MCP server 的状态追踪,正好是诊断 agent 最容易找到 systematic 错误模式的地方——它会告诉你"agent 在 Postgres 环境下经常忘记 commit"或者"在 GitHub 环境下不会处理 rate-limit",然后定向出题就直接打这些点。
训练动态:稳定但有挑战

图 9:这里有个反直觉的细节——entropy 在涨,不是在跌。这跟传统 RL 直觉相反——通常我们希望 entropy 收敛,但 agent RL 在多环境下,模型遇到的 API 越来越多,需要保持探索新交互模式的能力,所以 entropy 上升反而是健康信号。
这个 entropy 上涨的现象有点意思。我自己之前训 agent RL 的时候也见过——但都是"训崩了往上跳"那种。这里看曲线是平稳上升,说明环境多样性确实给了模型探索空间,没让它退化到死板的几个工具组合里。
我的判断:值得借鉴的不是算法,是产线
读完之后,给我留下深刻印象的是几件事:
第一,算法层几乎没创新,但这是优点不是缺点。GRPO 直接拿来用,clip 配置照搬 DAPO,reward 也是简单的 0/1 verifiable reward。作者把全部精力放在了"数据/环境产线"上——这其实是一种很成熟的工程判断:算法的边际收益已经很有限了,环境的边际收益还非常陡峭。
第二,"诊断 + 定向出题"这个 loop 是真正的杀手锏。但坦率讲,这个想法本身也不算新鲜——curriculum learning 和 active learning 早就有类似思路。它的真正价值是:在 LLM agent 这个新范式下,第一次把这套 loop 完整跑通且证明能持续涨点。EnvScaler-8B 套上同一 loop 也能涨,这点比 Agent-World 自己涨更说明问题。
第三,环境真实性的红利远没吃完。环境从 100→500 区间内的快速涨点说明绝大多数现有环境扩展方法(包括 EnvScaler、AWM)的环境多样性其实远远不够。这给"把环境做厚"留下了大空间。
几个我比较存疑的地方:
-
诊断 agent 本身的可靠性论文给的细节不多。它用的是 GPT-OSS-120B 来做 diagnosis,但 120B 自己在 MCP-Mark 上只有 4.7% 准确率,让一个本身在该任务上表现差的模型来"诊断"agent 的问题,这里有没有循环依赖?我没看到论文做反事实分析,比如换一个不同的诊断模型 loop 是否还能 work。
-
任务保留的 0.5 通过率门槛有点偏高。论文设的是工具单元测试通过率 \gt 0.5 才保留,相当于把一些"难但 valuable"的工具直接砍掉了。在 MCP-Mark 这种真实环境上,0.5 的执行成功率其实已经不算差了。
-
数据库 complexification 的具体细节几乎没展开。这个步骤对最终性能影响应该很大,但论文里就给了一个公式和一段描述。如果开源代码不放这部分,复现难度会非常高。
-
跟简单加大数据多样性的对比缺失。如果只是把 EnvScaler 的训练数据简单加倍/翻三倍,能不能逼近 Agent-World 的效果?这个对照实验如果有就太好了。
对工程落地的几个启发:
-
如果你正在做企业级 agent,与其再搭一个新的 RL 算法 fork,不如把精力放在"真实环境 + 诊断 loop"上——投入产出比可能高一个数量级。
-
MCP server 注册表(Smithery、MCP Atlas)正在变成 agent 训练的重要基础设施。如果你的应用要接 MCP,提前在这些 registry 里挑高质量 server 做训练数据,会比自己造 fake server 强得多。
-
诊断 agent 这种 meta-agent 模式值得复用。哪怕你不做 RL 训练,做 agent 评估的时候也可以引入一个 diagnosis agent 自动归类失败模式——这比人工分析失败 trace 效率高太多。
-
0/1 sparse reward + GRPO + 多环境动态采样这个组合,在 stateful agent RL 上看起来比 PRM-style 复杂奖励更稳。这跟前阵子 KnowRL 等工作的发现是一致的——简单 reward + 高质量环境 \gt 精巧 reward + 简陋环境。
写在最后
这篇论文给我最大的体会是,agent 这个范式正在从"模型 vs 模型"的算力竞赛,转向"环境 vs 环境"的资产竞赛。Anthropic、OpenAI、ByteDance Seed 这些公司搞 agent 越来越像在搞一座"训练用的小型互联网",而不只是在调更好的 RL 算法。
对学术界来说,Agent-World 给了一个相对完整的 reference implementation——从环境采集到自演化 loop 都做齐了。对工业界来说,更值钱的可能是它揭示的几条经验:环境真实性比环境数量重要、诊断 loop 比 reward 设计重要、MCP 生态正在变成 agent 训练的关键底层。
我个人比较期待看到的下一步是:(1) 把 diagnosis agent 换成更弱或更强的模型,看 loop 的鲁棒性;(2) 把 self-evolving loop 跑到 5+ 轮,看 plateau 在哪;(3) 在多 agent 场景(不只是 single agent + tools)里复刻这套 framework。这些都是论文留下的好问题。
如果你也在做通用 agent 训练或 MCP 工具调用方向,这篇论文非常值得仔细读一遍——尤其是附录里的环境卡片(Section 8)和 case study(Section 9),那才是真正的"环境工程黄金"。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新AI前沿,关注我