DeepSeek-V4 技术报告精读:1.6T 参数、49B 激活、1M 上下文,开源模型的"算力性价比"被重新定义
一句话先抛结论:DeepSeek-V4 不是去抢 Gemini-3.1-Pro 的 SOTA 王座,而是把"百万 token 上下文"从一项摆设,做成了单 token FLOPs 只剩 V3.2 的 27%、KV cache 只剩 10% 的可日常调用的能力。代价是落后顶级闭源模型大约 3–6 个月,但在 SimpleQA、Codeforces、长文本检索这几个赛道,开源阵营的天花板被它实打实抬起来了。
一、为什么这篇报告值得认真看
说实话,看到 DeepSeek-V4 是 preview 版的时候,我第一反应是"这次主角应该不是 benchmark 了"。
果然——整篇 60 页的技术报告,前 25 页几乎全在讲怎么把注意力的 FLOPs 和 KV cache 砍下来。模型有两个尺寸:
- DeepSeek-V4-Pro:1.6T 总参数 / 49B 激活,61 层
- DeepSeek-V4-Flash:284B 总参数 / 13B 激活,43 层
两者都原生支持 1M token 上下文。在 1M context 下,Pro 版的单 token 推理 FLOPs 只有 V3.2 的 27%,KV cache 只有 10%;Flash 版更狠——FLOPs 10%、KV cache 7%。
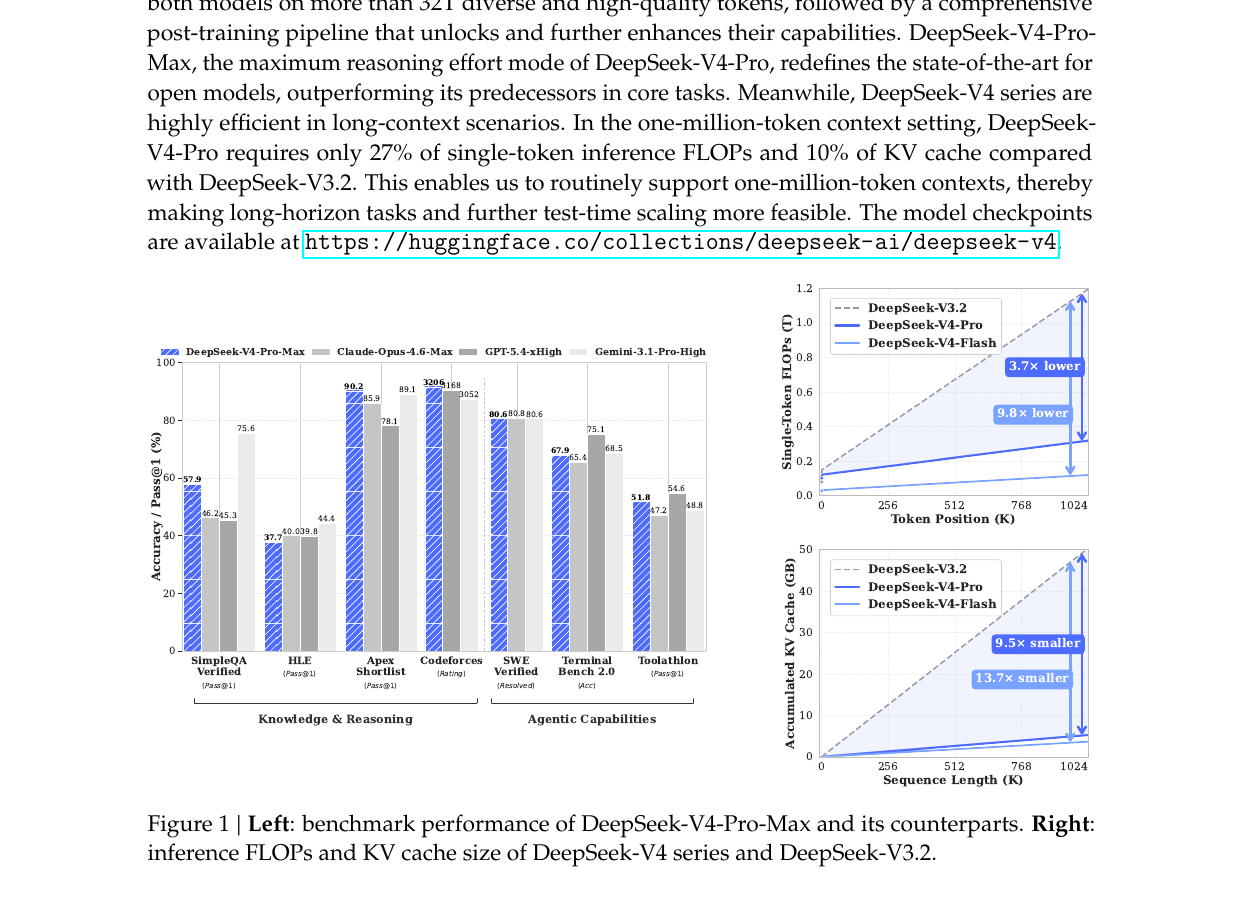
图 1(论文 Figure 1):左半部分是 V4-Pro-Max 与 Opus-4.6-Max / GPT-5.4-xHigh / Gemini-3.1-Pro-High 在 7 个核心 benchmark 上的对比(V4-Pro-Max 用蓝色柱);右半部分是单 token FLOPs 与累积 KV cache 随序列长度的变化——可以直观看到 V4-Pro 相比 V3.2 在 1M token 处大约 3.7× 更低 FLOPs,9.5× 更小 KV cache,Flash 版甚至到 9.8× / 13.7×。这两条曲线才是这篇 paper 真正的卖点。
理解了这个底色,再看后面的 benchmark 数据才不会被带跑偏。
二、核心摘要
DeepSeek-V4 的故事可以拆成三件事:
-
架构上:用 CSA(Compressed Sparse Attention) 和 HCA(Heavily Compressed Attention) 交替组成 hybrid attention。CSA 把每 4 个 token 的 KV 压成 1 个再做稀疏 top-k 选择;HCA 更狠,每 128 个 token 压成 1 个 KV entry,但走 dense attention。两者交替,长上下文的 FLOPs 被砍到原来的零头。配套换上 mHC(Manifold-Constrained Hyper-Connections)替代普通残差,并用 Muon 优化器做主干训练。
-
基础设施上:自研 MegaMoE 单 fused kernel 把 EP 通信彻底藏进计算后面;用 TileLang DSL + Z3 SMT 做内核开发;MoE 专家权重直接走 FP4 量化感知训练;KV cache 上盘存储用来吃掉 shared prefix 的预填充。
-
后训练上:抛弃了 V3.2 的 mixed RL,改成 "领域专家 SFT + GRPO 训练" → "On-Policy Distillation 蒸馏成统一模型" 的两段式范式,并配上一套 GRM(Generative Reward Model)+ rubric 解决难验证任务的奖励信号问题。
效果上:V4-Pro-Max 在开源阵营里事实上独占第一,SimpleQA-Verified 直接把 K2.6/GLM-5.1 拉开 20 个点,Codeforces Rating 3206 排到全球人类选手第 23 位;但在 MMLU-Pro、GPQA、HLE 等知识性硬题上,距离 Gemini-3.1-Pro-High 还有 3–4 个点的真实差距,作者自己都坦白"trail by 3–6 months"。
一句话:这不是一篇"抢 SOTA"的论文,是一篇"把架构革命落地"的工程报告。 想看花哨指标可能会失望,但想理解下一代 LLM 怎么把 1M context 做成默认配置的人,这篇必须细读。
三、论文信息
- 标题:DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence
- 机构:DeepSeek-AI
- 联系:research@deepseek.com
- 模型权重:https://huggingface.co/collections/deepseek-ai/deepseek-v4
- 版本:Preview Version
- 预训练规模:Pro 版 33T tokens,Flash 版 32T tokens
四、问题动机:百万 context 不是 vanity,是 reasoning scaling 的下一阶门槛
先把作者真正想解决的问题摆清楚。
reasoning model(DeepSeek-R1 / o-series 那一波)开了一个新范式:test-time scaling——把推理算力堆上去,正确率就涨。但这个范式有个 hard ceiling:vanilla attention 的复杂度是 O(n²)。
你想想看,长程 agent 任务、跨多文档分析、code agent 跑几十轮工具调用,动辄就上 256K、512K,再往上就直接被 KV cache 撑爆了显存。reasoning scaling 与 long-context 这两件事,本质上撞在了同一个瓶颈上——注意力机制本身。
之前的方案不是没有:MiniMax 的 lightning attention、Qwen 的 YaRN 外推、Hymba 的 hybrid head,乃至 DeepSeek 自己 V3.2 提出的 DSA(DeepSeek Sparse Attention)。但要么是"勉强能跑 1M,但实际成本无法承受",要么是"长 context 性能严重退化"。
DeepSeek-V4 的目标其实很朴素:把 1M context 做成可以默认开启的配置,而不是只在 demo 里跑一跑。
五、方法核心:CSA + HCA 混合注意力是怎么省下 90% KV cache 的
5.1 整体架构一眼
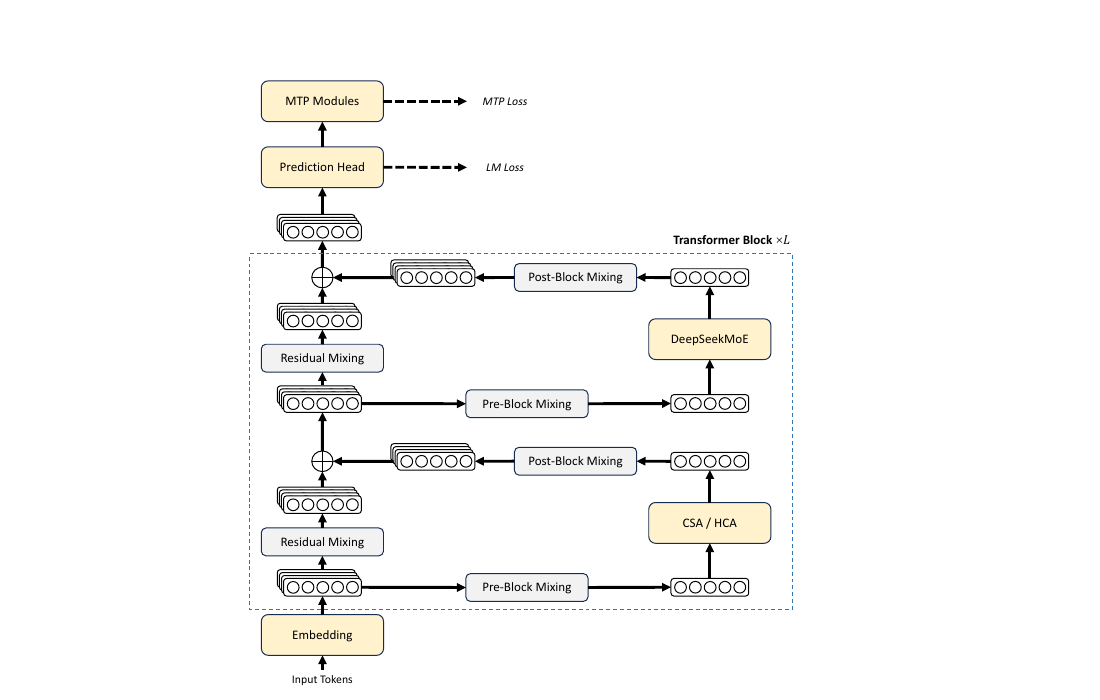
图 2(论文 Figure 2):DeepSeek-V4 整体架构。每个 Transformer Block 内部,attention 层在 CSA 与 HCA 之间交替,FFN 层是 DeepSeekMoE,前后用 mHC(Manifold-Constrained Hyper-Connections)替代传统残差做 Pre-Block / Post-Block / Residual Mixing。MTP 模块依然挂在最顶端做多 token 预测。
整体看起来还是 V3 那一套——MoE + MTP——但里头的两个关键 box 全换了:注意力换成了 CSA/HCA hybrid,残差换成了 mHC。
5.2 CSA:先压缩,再稀疏 top-k
CSA 的核心 idea 用一句话讲清:先把 KV 沿序列维度压成原来的 1/m,再用 lightning indexer 选 top-k,最后做共享 KV 的 MQA。

图 3(论文 Figure 3):CSA 核心架构。最下面 KV token 的隐状态先经 token-level compressor 压成 compressed KV entries;中间用 lightning indexer 计算每个 query 与每个压缩块的索引分数,做 top-k 选择;最右边再叠一个 sliding window 分支补回局部细粒度依赖。
关键参数:
- DeepSeek-V4-Flash:m=4(4 token 压成 1),top-k=512
- DeepSeek-V4-Pro:m=4,top-k=1024
- 两者都用 64 路 indexer query head,indexer head dim=128,indexer 的注意力计算走 FP4 精度
值得注意的是,CSA 实际是把"DSA(DeepSeek-V3.2 提出的稀疏注意力)"嵌在了"压缩之后的序列"上。也就是说双层效率叠加——先把序列长度 ÷4,再在压缩后的序列上只看 top-k。这才是 FLOPs 暴跌的根因。
至于为什么不直接做 top-1024 在原始序列上?想想看就明白:原始序列 1M 上做 top-1024 的索引扫描本身就是 O(n×n_indexer),照样不便宜。先粗压再选,把绝大部分计算挡在了一个 1/m 的搜索空间外面。
5.3 HCA:极端压缩,但走 dense attention

图 4(论文 Figure 4):HCA 核心架构。压缩比 m'=128(远大于 CSA 的 4),但不做 top-k 选择,而是直接对所有压缩后的 KV 做 dense MQA。同样补一个 sliding window 分支。
HCA 的逻辑反过来:既然你想存得更少,那就压得更狠。每 128 个 token 压成一个 KV entry,1M token 直接变成 7.8K entries——这个量级再做 dense attention 完全可以接受。
为什么不全用 HCA?因为 128:1 的压缩肯定丢信息。CSA 的压缩比小、选择性强,适合保留细粒度;HCA 适合保留全局粗粒度。Pro 版 61 层里两者交替使用,在不同层不同粒度都被覆盖,这套 hybrid 才能 work。
CSA / HCA 都额外补一条 sliding window attention(n_win=128) 分支。原因也很直白:CSA/HCA 严格按 causal 来,query 只能看到 preceding compressed block,自己所在 block 内的最近几个 token 反而看不到——这显然不合理,所以补了一个固定窗口的 dense 分支兜底。
5.4 mHC:把残差矩阵约束在 Birkhoff polytope 上
这块是 DeepSeek-V4 比较"理论"的一笔。
普通 Hyper-Connections(HC)把残差流的宽度从 ℝ^d 扩成 ℝ^{n_hc × d},引入三个线性映射 A, B, C 做残差更新。问题是堆深以后训练数值不稳定,loss spike 频发。
mHC 的核心约束:让残差变换矩阵 B 落在双随机矩阵流形(Birkhoff polytope)上:
这个约束的意义是 \(\|B_l\|_2 \leq 1\)——残差变换永远是非扩张的,前向反传都不会让信号炸掉。而且 \(\mathcal{M}\) 在矩阵乘法下封闭,所以堆 60 层照样稳。
实现上,他们用 Sinkhorn-Knopp 算法做 20 步行列归一化把 B 投到 \(\mathcal{M}\) 上。算力开销不大,工程可控。
老实说,mHC 这部分我读得有点犹豫——把矩阵投到双随机流形上去做残差控制,理论很漂亮,但 20 步 Sinkhorn 在每一层每一步训练里都要跑,整体引入的 wall-clock 成本是不是真的 negligible?论文没有给详细的 ablation,我估计后续社区会有人单独验证这一点。
5.5 Muon 优化器:用上 hybrid Newton-Schulz
主干换成了 Muon(Embedding、Prediction Head、RMSNorm 仍用 AdamW)。Muon 的关键是用 Newton-Schulz 迭代把动量矩阵正交化。
DeepSeek 在这里的小创新是 hybrid Newton-Schulz:前 8 步用 (a,b,c)=(3.4445, -4.7750, 2.0315) 系数快速收敛奇异值到 1 附近,最后 2 步切到 (2, -1.5, 0.5) 精确稳定到 1。这是个工程细节,但对训练稳定性帮助应该不小。
另外有一个细节挺有意思:因为 attention 的 query 和 KV 都做了 RMSNorm,attention logits 不会爆炸,所以他们没用 Liu et al. 2025 的 QK-Clip。这是相比 Kimi 那边 Muon 落地方案的一个差异点。
5.6 训练稳定性:两个"野路子"
训练 trillion 级 MoE 不稳定是常态,DeepSeek-V4 也碰到了。他们用了两个 trick:
-
Anticipatory Routing:在 step t 用当前参数 \(\theta_t\) 算特征,但路由用历史参数 \(\theta_{t-\Delta t}\) 算并提前缓存。解耦主干和路由网络的同步更新,能避免 loss spike 的死循环。系统层做了流水线优化,额外 wall-clock 开销控制在 ~20%,且只在检测到 spike 时才启用,平时不影响。
-
SwiGLU Clamping:把 SwiGLU 的线性分量 clamp 到 [-10, 10],gate 上限也卡 10。简单粗暴但有效——直接抹掉 outlier,从源头消灭异常激活。
这两个 trick 作者自己都说"underlying mechanisms remain insufficiently understood"。我觉得这是 paper 难得的一处坦诚——能用、不知道为什么 work,先记下来给社区一起研究。
六、基础设施:MegaMoE、TileLang、FP4、On-Disk KV Cache
这块技术细节很多,挑几个有意思的说:
-
MegaMoE 单 fused kernel:把 MoE 层的 Dispatch / Linear-1 / Linear-2 / Combine 全部融进一个 pipeline kernel,按 expert 切 wave 调度。理论加速 1.92×,实测 1.50–1.73×,RL rollout 等长尾场景能上 1.96×。已开源(DeepGEMM PR #304)。
-
TileLang + Z3 SMT solver:把 TileLang 的整数表达式翻译成 Z3 的 QF_NIA(quantifier-free non-linear integer arithmetic),用 SMT 做 layout inference / memory hazard / bound analysis。用形式化方法做编译优化,编译时间只多几秒但解锁了变量 tensor shape 上的 vectorization。这个思路在工业级 DSL 里我之前没怎么见过,蛮新鲜。
-
FP4 量化感知训练:MoE expert 权重直接用 FP4 (MXFP4) 存储和计算。训练时通过 FP4 → FP8 lossless dequant 复用现有 FP8 mixed precision 框架。在当前硬件上 FP4 × FP8 和 FP8 × FP8 算力相同,但未来硬件理论上能做到 1.33× 更快。
-
On-Disk KV Cache:把压缩后的 CSA/HCA KV entry 全存盘,shared prefix 命中时直接从 SSD 读。SWA 的 KV 不压缩量大,给了三种策略(全缓存 / 周期 checkpoint / 零缓存重算),不同部署场景按需选。这是把"长上下文 + 多轮"做成线上服务必须解决的工程问题,他们直接开放了三种 trade-off 方案。
七、后训练:把 mixed RL 整个换成 OPD
这是 DeepSeek-V4 与 V3.2 在 post-training 上最大的方法学切换:完全放弃了 V3.2 的 mixed RL 阶段,改用多教师 On-Policy Distillation。
7.1 第一阶段:领域专家训练
针对每个目标域(数学、代码、agent、指令遵循等),独立训练一个 expert 模型:
- SFT:高质量域内数据做 supervised fine-tuning
- GRPO:用域内 reward signal 做强化学习
这一步会得到 10+ 个 specialized experts。
对于难验证任务(如开放式问答、写作),他们用 GRM(Generative Reward Model)替代传统 scalar reward model——actor 网络本身就是 GRM,joint 优化"打分能力"和"生成能力"。这个设计的好处是只需要少量 diverse 人工标注,模型靠自己的推理能力泛化。
7.2 第二阶段:On-Policy Distillation 合并
学生模型 \(\pi_\theta\) 自己采样轨迹,对每个 expert 计算反向 KL,加权累加:
特别强调一点:他们用 full-vocabulary logit distillation,不是常见的 token-level KL 估计。理由是 token-level 简化方差太大、训练不稳定。但 |V|>100k 全量 logits 在十几个 trillion 级 teacher 上根本存不下——他们的解法是只缓存 last-layer hidden state,训练时按需通过对应 prediction head 重算 logits。再加上按 teacher index 排序 mini-batch,保证同一时刻设备上只有 1 个 teacher head。
老实说,OPD 替代 mixed RL 是一个非常激进的方法学转变。mixed RL 的优势是"边对齐边混合",而两段式蒸馏的风险是"专家擅长的能力可能在合并时被洗掉"。但从最终 benchmark 看,效果反而上了一个台阶——这背后的关键应该是 GRM + rubric 的奖励信号设计,把"难验证任务"的 RL 信号做扎实了。
7.3 三档 reasoning effort 模式
V4 系列原生支持三档:
| Mode | 特点 | 典型场景 | 输出格式 |
|---|---|---|---|
| Non-think | 快、直觉 | 日常 / 紧急 / 低风险 | </think> summary |
| Think High | 完整推理 | 复杂规划 / 中等风险 | <think>...</think> summary |
| Think Max | 推到极限 | 探边界 / 高风险 | 注入特定 system prompt + thinking |
Think Max 注入的 prompt 这里值得贴一下,挺有意思:
Reasoning Effort: Absolute maximum with no shortcuts permitted. You MUST be very thorough in your thinking and comprehensively decompose the problem to resolve the root cause, rigorously stress-testing your logic against all potential paths, edge cases, and adversarial scenarios. Explicitly write out your entire deliberation process, documenting every intermediate step, considered alternative, and rejected hypothesis to ensure absolutely no assumption is left unchecked.
某种意义上是把"prompt engineering 让模型更深思考"这件事固化到了模型的行为模式里。
八、实验结果:放在两张图前面,把数据掰开聊
接下来是这次最关键的部分。我用用户截给我的两张图来做对比分析。
8.1 全景对比图(含 V4-Flash)
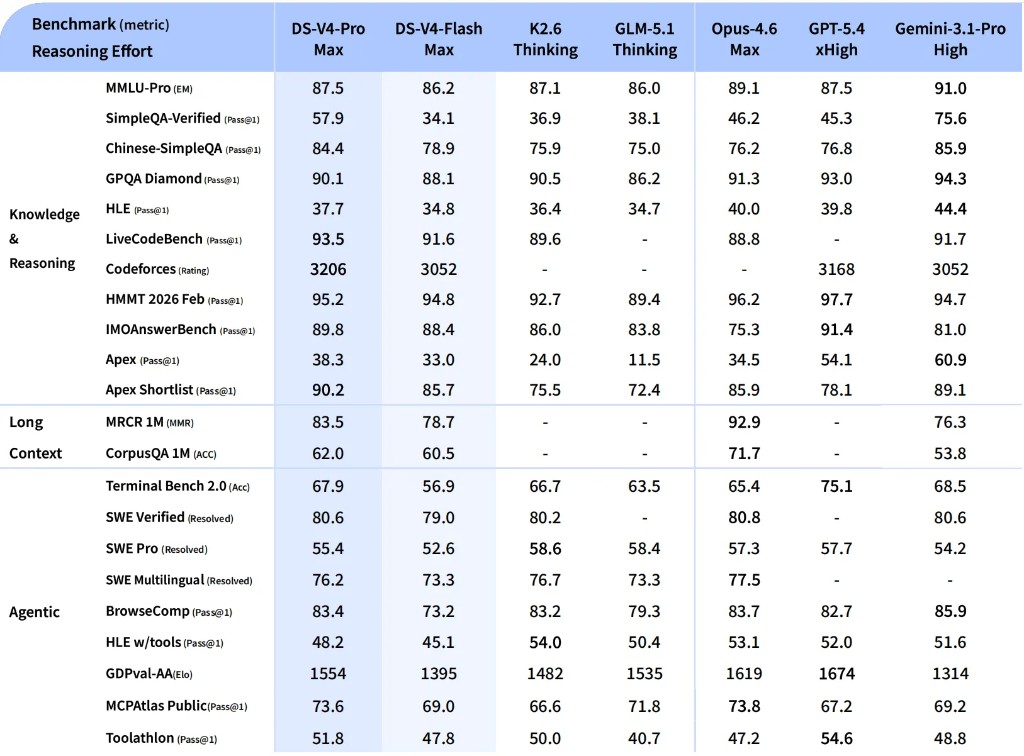
图 5:DeepSeek-V4-Pro-Max 与 DeepSeek-V4-Flash-Max 同时与 K2.6 / GLM-5.1 / Opus-4.6-Max / GPT-5.4-xHigh / Gemini-3.1-Pro-High 的全维度对比(蓝底两列是 DeepSeek 自家模型)。
8.2 对手视角的标准对比表(论文 Table 6)
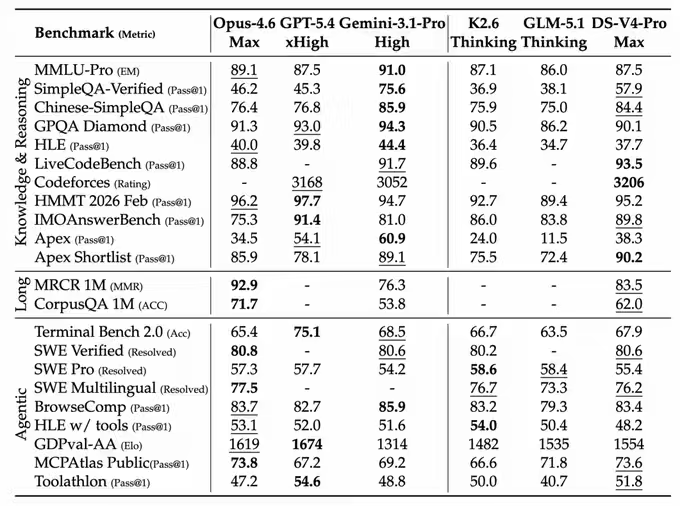
图 6(论文 Table 6):以闭源前沿 Opus-4.6-Max / GPT-5.4-xHigh / Gemini-3.1-Pro-High 为参照系,对照 K2.6-Thinking / GLM-5.1-Thinking 与 DS-V4-Pro-Max 的同台对决。粗体为最优,下划线为次优。 这才是评估 V4 在闭源主导格局里"实际站位"的视角。
下面分几个维度,结合两张图一起看。
知识 & 事实(Knowledge)
| 任务 | DS-V4-Pro-Max | DS-V4-Flash-Max | K2.6 Th | GLM-5.1 Th | Opus-4.6 Max | GPT-5.4 xHigh | Gemini-3.1-Pro High |
|---|---|---|---|---|---|---|---|
| MMLU-Pro | 87.5 | 86.2 | 87.1 | 86.0 | 89.1 | 87.5 | 91.0 |
| SimpleQA-Verified | 57.9 | 34.1 | 36.9 | 38.1 | 46.2 | 45.3 | 75.6 |
| Chinese-SimpleQA | 84.4 | 78.9 | 75.9 | 75.0 | 76.2 | 76.8 | 85.9 |
| GPQA Diamond | 90.1 | 88.1 | 90.5 | 86.2 | 91.3 | 93.0 | 94.3 |
| HLE | 37.7 | 34.8 | 36.4 | 34.7 | 40.0 | 39.8 | 44.4 |
几个值得拎出来说的细节:
-
SimpleQA-Verified 上 V4-Pro-Max 拿了 57.9,把 K2.6/GLM-5.1 拉开了 20 个点,把 Opus/GPT-5.4 也拉开 12 个点。开源模型的事实知识天花板被实打实抬起来了。这背后我猜是 33T tokens 预训练中"长尾知识 + 多语言"那块投入产生的效果。但跟 Gemini-3.1-Pro 的 75.6 对比——还差 17 个点,这是个真实的代差,不能光看开源排名。
-
Chinese-SimpleQA 上 V4-Pro-Max 84.4 几乎追平 Gemini 的 85.9,但碾压 Opus/GPT-5.4 的 76 左右。中文事实知识这一块 DeepSeek 是真有积累,跟训练语料分布直接相关。
-
MMLU-Pro / GPQA / HLE 这种学术硬题,Gemini-3.1-Pro-High 几乎全包,V4-Pro-Max 比 K2.6/GLM-5.1 略好一点点,但跟 Gemini 还差 4–7 个点。作者自己也承认"trail by 3–6 months"——这个判断是诚实的。
代码与数学
| 任务 | DS-V4-Pro-Max | DS-V4-Flash-Max | K2.6 Th | GLM-5.1 Th | Opus-4.6 Max | GPT-5.4 xHigh | Gemini-3.1-Pro High |
|---|---|---|---|---|---|---|---|
| LiveCodeBench | 93.5 | 91.6 | 89.6 | - | 88.8 | - | 91.7 |
| Codeforces (Rating) | 3206 | 3052 | - | - | - | 3168 | 3052 |
| HMMT 2026 Feb | 95.2 | 94.8 | 92.7 | 89.4 | 96.2 | 97.7 | 94.7 |
| IMOAnswerBench | 89.8 | 88.4 | 86.0 | 83.8 | 75.3 | 91.4 | 81.0 |
| Apex | 38.3 | 33.0 | 24.0 | 11.5 | 34.5 | 54.1 | 60.9 |
| Apex Shortlist | 90.2 | 85.7 | 75.5 | 72.4 | 85.9 | 78.1 | 89.1 |
Codeforces Rating 3206——这个数字真的让我愣了一下。在一个公认极度依赖训练数据曝光度的赛道上,V4-Pro-Max 实测排到全球人类选手第 23 位,比 GPT-5.4-xHigh 的 3168 还高,比 Gemini-3.1-Pro-High 的 3052 高 154 分。
LiveCodeBench 也是开源天花板(93.5),超过 Gemini。这说明 DeepSeek 在"竞赛代码"这个细分赛道上的训练数据 + RL 信号配方真的很猛。
但要客观看:Apex 这种偏数学竞赛题,V4 跟 GPT-5.4-xHigh / Gemini-3.1-Pro-High 还差 16–22 分。说明数学的"硬创造性推理"这一块,开源仍有差距。
注意 Apex Shortlist 的 90.2 是 SOTA——这个 benchmark 的题大多数模型都做不出来,开源模型平均不到 75,V4-Pro-Max 一下做到 90.2,是真的硬实力。
Agent 与工具调用
| 任务 | DS-V4-Pro-Max | K2.6 Th | GLM-5.1 Th | Opus-4.6 Max | GPT-5.4 xHigh | Gemini-3.1-Pro High |
|---|---|---|---|---|---|---|
| Terminal Bench 2.0 | 67.9 | 66.7 | 63.5 | 65.4 | 75.1 | 68.5 |
| SWE Verified | 80.6 | 80.2 | - | 80.8 | - | 80.6 |
| SWE Pro | 55.4 | 58.6 | 58.4 | 57.3 | 57.7 | 54.2 |
| BrowseComp | 83.4 | 83.2 | 79.3 | 83.7 | 82.7 | 85.9 |
| HLE w/ tools | 48.2 | 54.0 | 50.4 | 53.1 | 52.0 | 51.6 |
| MCPAtlas Public | 73.6 | 66.6 | 71.8 | 73.8 | 67.2 | 69.2 |
| Toolathlon | 51.8 | 50.0 | 40.7 | 47.2 | 54.6 | 48.8 |
agent 这块的故事比知识更复杂:
- SWE Verified 几乎所有模型挤在 80 附近——这个 benchmark 已经趋于饱和,分数差异不大。
- MCPAtlas Public 上 V4-Pro-Max 73.6,跟 Opus-4.6 的 73.8 几乎并列第一。MCPAtlas 是测真实 MCP 服务调用的,这个比 SWE 更能体现"真实工具使用泛化能力"。论文作者自己也强调这一点:"indicating that our model has excellent generalization capability and does not perform well only on internal frameworks."
- BrowseComp、Terminal Bench 上 V4-Pro 跟 GPT-5.4 / Gemini 还有 1–7 分的差距,主要在长程任务收敛能力上。
长上下文(Long Context)
| 任务 | DS-V4-Pro-Max | Opus-4.6 Max | Gemini-3.1-Pro High |
|---|---|---|---|
| MRCR 1M | 83.5 | 92.9 | 76.3 |
| CorpusQA 1M | 62.0 | 71.7 | 53.8 |
这是 DeepSeek-V4 真正的主场:在 MRCR(in-context retrieval)和 CorpusQA(更接近真实场景的 1M 检索 QA)上:
- 超过 Gemini-3.1-Pro 7–9 个点——这是非常硬的胜利,因为 Gemini 是公认长上下文最强的闭源模型之一。
- 不及 Opus-4.6 大约 9–10 个点——Opus 的 1M 上下文实现确实是当前天花板。
但更重要的是论文给的 Figure 9:V4-Pro-Max 在 128K 之内几乎是平的曲线(~0.91 MRR),到 1M 才掉到 0.82。这个稳定性曲线是工程价值最高的部分——一个能在 1M 不显著掉分的模型,意味着 long-horizon agent 任务可以放心丢上去。
九、批判性视角:哪些地方值得多打几个问号
我这里说几个读完之后觉得"作者讲得有点轻,但其实需要更多 evidence"的点:
1. mHC 的真实成本
20 步 Sinkhorn 投影,每层每步都跑,作者只说"开销不大"。但在 1.6T 参数 + 61 层的规模下,这个 overhead 究竟占训练时间多少?没给数字。我会想知道一个clean ablation:去掉 mHC 用普通 HC 是不是真的不能 work,还是只是收敛慢一点?这关系到这个组件值不值得加。
2. Anticipatory Routing 听起来更像"经验补丁"
"用历史参数算路由,用当前参数算特征"——这背后理论解释作者没给。我猜测可能跟 token routing 与 MoE expert weights 之间的"循环负反馈"有关,但作者明确说"underlying mechanisms remain insufficiently understood"。这种 hack 在 trillion-MoE 这种规模上的可复现性是个问号——别的团队照搬不一定 work,因为不知道是哪个具体细节在起作用。
3. OPD 替代 mixed RL 的真实效果对比
报告里没看到一个直接的 ablation:同样的数据、同样的算力、用 mixed RL 训出来 vs 用 OPD 训出来,差几个点?没有这个对比,就只能"相信作者的设计选择",无法判断是 OPD 真的好,还是 GRM/rubric 那一套奖励信号设计带来了大部分增益。
4. Codeforces 3206 这个数字怎么算的?
值得细看:他们自己 collect 了 14 场 Codeforces Div 1 contests(May–Nov 2025)作为 internal benchmark,每题采 32 个 candidate,随机抽 10 个组成 submission sequence,按 OpenAI 2025 的 penalty scheme 算 contest rank 再换算 Elo。
这个 protocol 本身没问题,但有几个细节:32 个 candidate 取 10 个最好的能不能进——其实是 sample without replacement 不是 best-of-10,并且算的是"期望评分"(average over all possible orderings)。所以这个 3206 是"概率意义上"的评分,不是单次比赛拿 3206。这点作者没特别强调。如果换"best-of-N pass-1 rate"我估计数字会更高,但同时跟人类比也更不公平。
5. GPT-5.4 / K2.6 / GLM-5.1 部分数据缺失
看 Table 6 有大量 "-"。论文解释是"their APIs were too busy to return responses"。这其实是个 awkward 的状态——你最强的对手在某些题上没数据,那"DS-V4-Pro 在 LiveCodeBench 拿第一"这个判断就需要打个折扣。Codeforces Rating 上 GPT-5.4 是 3168 不是 "-",所以 V4-Pro 比 GPT-5.4 多 38 分这个比较是成立的,但其它 benchmark 要小心。
十、Flash 还是 Pro?你应该用哪个
从 Table 7 看,结论很清晰:
- 知识密集型任务 Pro 大幅胜出(SimpleQA-Verified Pro 57.9 vs Flash 34.1)——参数规模决定知识容量。
- 数学、代码任务 Flash 给到 Max 模式可以追到 Pro 90% 水平(HMMT Flash-Max 94.8 vs Pro-Max 95.2)——reasoning 任务更吃 thinking budget 而非参数。
- Agent 复杂任务 Pro 仍优(Terminal Bench 2.0 Pro 67.9 vs Flash 56.9)——长程规划吃参数。
- 简单工具调用 Flash 已经够用(MCPAtlas Flash-Max 69.0 vs Pro-Max 73.6 差距小)。
实操建议:日常 chatbot、简单 agent、代码辅助 → Flash 性价比远胜;研究、长文档分析、高难度推理 → 上 Pro。
十一、几个工程上很值得 borrow 的点
如果你也在做 LLM 训练或服务,这篇 paper 真正的"金子"在基础设施部分:
- MoE 单 fused kernel 的 wave-based scheduling(MegaMoE 已开源)——把 Dispatch / Combine / Linear-1 / Linear-2 全部融成一个 pipeline kernel,按 expert wave 切。1.5–1.96× 加速,且对带宽要求更宽容。
- TileLang + Z3 SMT——做 DSL 编译时引入形式化验证,能解锁更多 tensor shape 上的 vectorization。这个思路对自研推理引擎 / 训练 kernel 库的团队是个新方向。
- On-Disk KV Cache + 三种 SWA 策略——shared prefix 缓存上盘,并按 SSD I/O 模式给三种 trade-off 方案。对长上下文 Agent 服务化是必备的。
- Anticipatory Routing 检测式启用——不要默认开启,loss spike 才启用,恢复后退回。把"昂贵的稳定性 trick"做成自适应这个思路通用。
- GRM + rubric 替代 scalar RM——actor 自己当 reward model,joint 训。对难验证任务的 RL 这个范式比传统 RLHF 更省人力。
- OPD 的 last-layer hidden state 缓存——做 multi-teacher 蒸馏的内存压缩思路,比缓存 logits 优 100 倍以上。
十二、几个收尾的判断
关于 DeepSeek-V4 的真实定位:
- 不是 SOTA——明确比 Gemini-3.1-Pro / GPT-5.4 落后 3–6 个月,作者自己也承认。
- 是开源新天花板——SimpleQA、Codeforces、长上下文这几个赛道,开源阵营被它实打实抬起来了。
- 是工程报告而非算法 paper——核心贡献在系统架构和效率优化,算法层面更多是组合既有工作(DSA、Muon、HC)。
- 是下一代 1M-context 服务化的范式提案——27% FLOPs / 10% KV cache 这个数字,是把 1M 从"demo 玩具"做成"日常调用"的门槛突破。
对行业的影响:
如果你是开源模型团队,这篇报告里的 hybrid CSA/HCA + on-disk KV cache + GRM + OPD 这套组合拳很可能会被广泛采纳。Kimi、智谱、Qwen 接下来的版本估计都会跟进类似设计。
如果你是闭源前沿模型团队(OpenAI / Anthropic / Google),DeepSeek-V4 不构成正面威胁,但它在 Codeforces 3206 和 SimpleQA 上的表现说明开源跟闭源的"应用层差距"在 6 个月内可能会被进一步压缩到边缘场景。真正的差距越来越集中在最难的学术推理(HLE / GPQA Diamond / Apex 数学)和最复杂的多模态/长程 agent 上。
如果你是上层应用开发者,Flash 版的性价比是这次最大的礼物——13B 激活、284B 总参数、原生 1M 上下文、在 Think Max 模式下能在数学 / 代码任务追到 Pro 的 90%。基本可以替代你之前用 GPT-4o 做的大部分轻量推理 + 长文档场景。
最后一句感想:DeepSeek 这次没去抢"最聪明"的 title,而是把"最能跑得起 1M 上下文"这件事做扎实了。这种工程优先的路线在大模型行业目前的内卷格局里,反而可能是更稳的一招。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新 AI 前沿,关注我