记忆增强的动态奖励塑形:MEDS如何让LLM不再"重蹈覆辙"
核心摘要
大模型强化学习有个老大难问题:模型不是随机犯错,而是反复掉进同一个坑。现有的熵正则化只能鼓励"随机性",但管不了"重复犯错"。复旦团队的MEDS框架给出了一个直接方案——给奖励函数装上"记忆",用逐层logit做推理指纹,HDBSCAN聚类识别高频错误模式,越常见的错误惩罚越重。在5个数学推理基准、3个基座模型上,pass@1最高提4.13分,pass@128最高提4.37分。思路简洁,理论也有保证,值得一看。
一、痛点在哪:模型犯错不是随机的
搞过大模型RL训练的人都知道一个心累的现象:on-policy采样的时候,模型特别喜欢反复生成同一类错误答案。不是今天错A明天错B那种随机散布,而是几百个step下来,模型对某道题就是死盯着一条错路走到底。
这在GRPO、DAPO这些主流RLVR方法里都挺常见的。你把reward signal设计得再精细,模型该犯的错还是一个不少地重复犯。为啥?因为这些方法有个共同盲区:奖励函数是"无记忆"的——它只看当前这个回答对不对,根本不知道这个错误你已经看过八百遍了。
现有的熵正则化能缓解一点问题,但它干的事情是鼓励当前策略分布更"随机"——往采样里掺点噪声,让输出不那么确定。问题是,这跟"阻止重复犯错"压根不是一回事。你可以在很随机的策略下依然反复犯同一个错,只要那个错误在策略里概率够高。
打个比方,熵正则化就像告诉学生"答案可以随便猜",而MEDS要干的是"你上次这道题猜错了A,这次再猜A就扣更多分"——完全不同的逻辑。
MEDS的核心思路很简单直接:让奖励函数记住历史错误,越常见的错罚越狠,逼模型去探索新的解法。
从技术脉络看,这个想法跟RL领域里经典的reward shaping一脉相承。Ng等人在1999年就证明了potential-based reward shaping不改变最优策略,但那是针对单步MDP的。在LLM的on-policy RL场景下,奖励塑形的约束条件更复杂——你不仅要保证不改正确答案的奖励,还得在多步采样之间维持信号的一致性。MEDS的做法是只对错误响应施加惩罚,正确答案的奖励原封不动,这在理论上保证了真实任务回报不降。
二、MEDS框架:三步走
MEDS的全称是Memory-Enhanced Dynamic reward Shaping,由三个阶段串联而成:
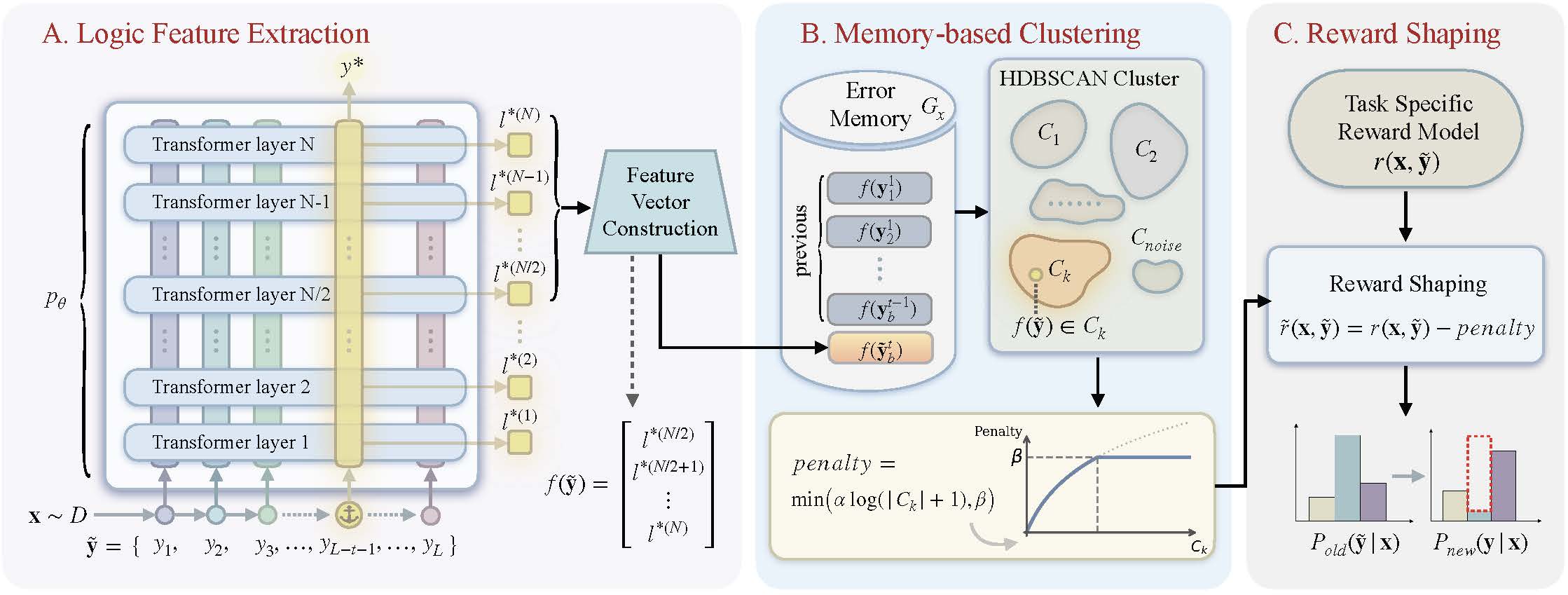
阶段A:逻辑特征提取——用logit当"推理指纹"
对每个采样的rollout,MEDS从模型前向传播中提取最终答案第一个token在各Transformer层的logit值。
具体来说,假设模型有\(N\)层Transformer,答案的第一个token是\(y^*\),那么第\(n\)层对应\(y^*\)位置的logit值记为\(l^{*(n)}\)。MEDS取后一半层(第\(N/2\)到第\(N\)层)的logit拼接起来,再做L2归一化:
这个设计有几个讲究:
-
为啥取后半段层? 前面的层主要编码底层语义信息(比如识别"这是关于除数的问题"),后面层的logit变化才真正反映推理结构的差异。论文的消融实验也验证了这一点——取末尾14层比用全部28层效果更好。从机理上理解,Transformer的后层负责将中间表示解码为输出分布,这个阶段的logit差异最能体现"模型选择了哪条推理路径"。
-
为啥取第一个答案token? 因为最终答案的生成是所有推理步骤汇聚的结果,这个位置的logit浓缩了整个推理链条的信息。论文的Figure 3很好地展示了这一点——推理结构相近的响应,其3层logit向量几乎重合;而推理结构不同的响应,即使最终答案相同,logit向量也明显分叉。
-
额外开销几乎为零。 这些logit本来就是前向传播的副产品,不需要额外跑一次forward。跟那些需要额外调用一个判别模型来做reward shaping的方法比,这点太香了——既省计算又省显存。
阶段B:基于记忆的聚类——HDBSCAN识别高频错误
对每个prompt \(x\),MEDS维护一个错误记忆库 \(G_x\),存储该prompt所有历史错误响应的logit特征向量:
其中\(b\)是每步每个prompt的采样数,\(t\)是训练步数。然后用HDBSCAN对这些特征做密度聚类:
选HDBSCAN而不是K-Means是有道理的:第一,聚类数\(K\)不需要预先设定,动态决定;第二,它天然支持噪声点——不是所有错误都能归入某个清晰的簇,有些确实就是孤立的;第三,HDBSCAN基于密度聚类,对形状不规则的簇也能处理,不像K-Means只能找球形簇。HDBSCAN最小簇大小设为2,最小样本数设为1,距离度量用欧氏距离。
阶段C:动态奖励塑形——越常见的错罚越重
当一个错误响应被分到簇\(C_k\)后,MEDS根据簇大小计算惩罚:
这里\(\alpha\)控制惩罚强度,\(\beta\)设上限防止惩罚过大。取对数是让惩罚增长别太猛,设上限是保底。实验中,Qwen3-1.7B和Qwen2.5-Math-7B使用\(\alpha=0.1\)、\(\beta=0.2\),而较大的Qwen3-8B使用更保守的\(\alpha=0.02\)、\(\beta=0.04\)——模型越大,同样的惩罚强度影响越显著,所以系数要调小。
直觉上:如果一个错误模式出现了100次,另一个只出现2次,前者的惩罚要重得多——你该花精力去探索新路径了,而不是在第101次重复同样的错误。
整个MEDS流程可以用下面这张图直观理解:
三、理论保证:惩罚重复错误不会让期望回报下降
光有直觉不够,MEDS还给了一个定理:
定理1: 设有两个不同的奖励信号\(\mu_1 = r(x,y)\)和\(\mu_2 = r(x,y) - \lambda c(y)\),其中\(c(y)\)是重复错误的指示函数,随错误出现次数单调递增。令\(q_1\)和\(q_2\)分别为这两个奖励信号下的更新策略,\(J(q) = \mathbb{E}_{x,y \sim q}[r(x,y)]\)为真实任务奖励。则有:
换句话说,加上重复错误惩罚后,策略在真实任务奖励上的期望表现不会变差。直觉理解:重复犯错的响应在当前策略下概率质量高,给它额外降权等于把概率重新分配给探索不足的区域。惩罚只作用于重复错误,正确答案不受影响,所以真实回报至少不降。
证明思路利用了重加权吉布斯分布和协方差不等式,详见论文附录B。
四、实验结果:全面碾压
主实验
论文在5个数学推理基准(AIME24、AMC23、MATH500、Minerva、OlympiadBench)上测了3个基座模型(Qwen3-1.7B、Qwen2.5-Math-7B、Qwen3-8B),对比GRPO、DAPO和带熵奖励的组优势PPO(GRPO w/ Entropy Adv)。训练数据是DAPO-Math-17K加上MATH数据集难度3-5级的子集,统一用Qwen-Math模板格式化。所有RL训练基于veRL框架,在H200上完成。每个prompt采样16个rollout,prompt级别batch size为512。
Qwen3-8B(最强模型)上的结果最能说明问题:
| 方法 | AIME24 p@1 | AIME24 p@128 | AMC23 p@1 | MATH500 p@1 | OlympiadBench p@1 | Average p@1 |
|---|---|---|---|---|---|---|
| DAPO | 45.42 | 73.33 | 81.37 | 89.18 | 52.77 | 63.11 |
| MEDS | 45.78 | 76.67 | 82.62 | 92.51 | 61.12 | 66.72 |
几个亮点:
- 在Qwen3-8B上,OlympiadBench的pass@128从DAPO的70.81直接拉到82.67,相对提升17%——这是整篇论文最大的单点增益。这说明对大模型来说,探索多样性崩塌的损失比小模型更严重,MEDS的收益也更显著。
- MEDS在所有5个数据集、所有3个模型上都是最优,一致性很强。不是某个数据集上偶然好,而是整体压着其他方法打。
- 即使是1.7B的小模型,MEDS也能把Average pass@1从DAPO的46.6拉到52.49,提了快6个点。这还挺出乎意料的——小模型容量有限,你可能会担心惩罚重复错误会不会让本来就窄的搜索空间更窄,但实际上它反而拓宽了探索范围。
Qwen2.5-Math-7B上的结果:
| 方法 | AIME24 p@1 | AMC23 p@1 | MATH500 p@1 | Average p@1 |
|---|---|---|---|---|
| DAPO | 32.27 | 72.71 | 85.61 | 55.61 |
| MEDS | 34.32 | 74.38 | 86.33 | 56.47 |
这个模型不带显式推理过程(没有thinking token),MEDS照样有效。
消融实验:聚类特征怎么选很关键
论文在Qwen2.5-Math-7B上对比了不同的logit特征构建方式:
| 方法 | Average p@1 | Average p@128 |
|---|---|---|
| DAPO(无聚类) | 55.61 | 82.85 |
| MEDS-single cluster | 55.14 | 82.60 |
| MEDS-28-diff | 55.78 | 82.28 |
| MEDS-14-diff | 55.52 | 83.38 |
| MEDS-28 | 56.17 | 82.17 |
| MEDS-14 | 56.47 | 84.00 |
几个发现:
- single cluster(把所有错误归一类)反而比DAPO还差。这很关键——说明不是"加个惩罚就有效",你得把错误分对类,不同类型给不同力度才管用。一刀切反而添乱。这个结果也挺有启发的:它告诉我们,"奖励塑形"这个动作本身不是万能的,关键是塑形信号的质量。错误的分组信息比没有分组信息还糟糕。
- 末尾14层 > 全部28层。后半段层的logit对推理结构更敏感,前面的层主要编码语义,加进来反而是噪声。
- 直接拼接 > 相邻层差分。MEDS-14比MEDS-14-diff效果好,说明原始logit值比层间差值更有信息量。差分操作可能抹掉了一些绝对量级的信息,而这些量级差异恰恰能区分推理路径。
Logit聚类和LLM标注的一致性
论文用Claude-Haiku-4.5对800个错误响应做了人工标注级别的聚类,然后跟logit聚类对比。结果是61.2%的一致性——不算完美,但考虑到logit聚类零额外模型开销,这个性价比已经很高了。
而且论文还发现一个有趣的现象:聚类质量排名和下游性能排名高度一致。也就是说,更好的聚类→更大的性能提升,这进一步验证了MEDS核心机制的合理性。
五、案例分析:logit聚类到底在看什么
论文给了个很好的case study来说明logit聚类不只是看答案字符串。
问题:找一个有三个不同正因子且因子和为2022的最小"好数"。
两个响应A1和B1都输出了相同的错误答案1342,但它们的推理结构不同: - A1:锁定\(p^2\)假设→直接数值枚举 - B1:考虑\(p^2\)形式→又尝试\(p_1 \cdot p_2\)形式→回退到枚举
logit聚类把A1分到Cluster A,B1分到Cluster B——虽然答案相同,但推理路径不同,logit向量能区分开。反过来,A1和A2答案不同(1342 vs 1351),但因为推理路径相似,被归入同一簇。
这个案例很直观地展示了logit做"推理指纹"的价值:它捕捉的是你怎么想错的,不只是你答错了什么。光看答案字符串,A1和B1完全一样——都是1342,应该归为一类。但logit说不对,这两个响应虽然殊途同归到了同一个错误答案,但走的是两条不同的弯路,应该分开处理。这恰恰是字符串匹配做不到的。
六、多样性分析:MEDS确实在推动探索
论文从两个维度验证多样性提升:
- LLM标注评估:用Claude对采样响应做Within-Step Diversity和Across-Step Diversity打分,MEDS在两个维度上都高于基线。
- Top-1 Eigen Ratio:计算logit协方差矩阵最大特征值占所有特征值之和的比率。这个指标越小,说明表示空间越分散,探索越充分。MEDS在训练后期该指标持续低于基线。
这两个指标从不同角度说明同一件事:MEDS让模型的采样行为更分散了,不再死盯着几条老路走。
七、聊聊局限性和我的看法
坦率说,MEDS虽然效果扎实,但有几个值得注意的地方:
1. 只用了一个随机种子。 论文所有实验都是单种子结果,没有方差估计或统计显著性检验。对于RL这种方差天然就大的场景,这确实是个硬伤。你不知道4.13的pass@1提升有多稳定,还是刚好跑出了个好结果。在顶会审稿里,这一点大概率会被审稿人抓住。
2. 只取了答案第一个token的logit。 中间推理步骤的信息完全没用到。对于一个step-by-step的数学推理过程,只用最终答案位置的logit可能丢掉了很多中间环节的推理结构差异。这可能是为什么logit-LLM一致性只有61%的原因之一——剩下的39%里,说不定有不少中间步骤的差异没被捕获。一个自然的改进方向是对中间推理步骤也做logit提取,但计算开销和效果之间的权衡需要仔细考量。
3. 逐prompt记忆的局限。 每个prompt独立维护记忆库,跨prompt的通用错误模式没法识别。比如"遇到排列组合就忘除以全排列"这种跨问题的系统性偏差,MEDS是抓不到的。要扩展到跨prompt共享记忆,又会面临记忆库膨胀和特征空间对齐的问题。
4. 表征漂移问题。 训练过程中策略在变,早期rollout的logit和后期的可能不在同一个表示空间里了。HDBSCAN对历史特征和当前特征做聚类,但论文没有讨论这个分布漂移对聚类质量的影响。直觉上,早期的logit向量跟后期的可能已经不太可比了,但在记忆库里它们却被一视同仁。
5. 惩罚函数形式缺乏对比。 \(\min(\alpha \log(|C_k|+1), \beta)\)这个选择有没有跟其他形式做过消融?比如幂律、逆频率优势等。论文没有展示。对数+截断是一个直觉上合理的选择,但不一定是唯一甚至最优的形式。
不过话说回来,MEDS的核心贡献不是把每个细节都做到极致,而是提出了一个思路清晰、即插即用的方案:给RL奖励函数装上记忆,让重复错误付出更高代价。这个方向的可行性被验证了,后续的改进空间还很大。
八、总结
MEDS解决的不是"模型不聪明"的问题,而是"模型不长记性"的问题。在RL训练中,奖励函数天生就是短视的——只看当前对错,不看历史重复。MEDS通过三个简洁的组件——logit特征提取、HDBSCAN聚类、密度感知惩罚——给奖励函数装上了"记忆",让模型对高频错误付出更高代价,从而推动更广泛的探索。
从实验数据看,这个思路确实work:5个数据集3个模型上的一致性提升,最大单点17%的相对增益。理论保证也有——惩罚重复错误不会损害真实任务回报。代码也已开源,基于veRL框架构建,接入成本低。
回过头看,MEDS和最近一些关注RLVR探索效率的工作(比如Recycling Failures用离策略指导挽救探索、DyJR用Jensen-Shannon散度维持多样性)在精神上是相通的:都是意识到纯on-policy采样在后期效率急剧下降,需要主动干预。但MEDS的切入点更本质——它不只是在采样策略上做文章,而是直接追问"为什么奖励信号无法驱动模型跳出重复错误",然后从奖励塑形的角度给出回答。
如果你在做大模型的RL训练,特别是遇到采样多样性崩塌的问题,MEDS值得一试。
论文信息: - 标题:The Past Is Not Past: Memory-Enhanced Dynamic Reward Shaping - 作者:Yang Liu, Enxi Wang, Yufei Gao, Weixin Zhang, Bo Wang, Zhiyuan Zeng, Yikai Zhang, Yining Zheng, Xipeng Qiu - 机构:复旦大学 & 上海创新研究院 - arXiv:2604.11297 - 代码:https://github.com/Linxi000/MEDS
觉得有启发的话,欢迎点赞、在看、转发。跟进最新AI前沿,关注我