AggAgent:把并行轨迹当环境来交互,智能体聚合的新范式
你有没有遇到过这种情况——让一个Agent做深度研究,跑了8次,8条轨迹里其实藏着正确答案,但你怎么把它们"拼"出来?Majority Voting?要是多答案任务,投票直接废了。Best-of-N?模型自己标的confidence在长文本生成任务上根本不准。把8条轨迹全塞进context窗口?每条动辄十万token,8条拼一起直接OOM。
这就是并行扩展(parallel scaling)在智能体任务上的核心瓶颈:并行跑容易,聚合难。
Princeton的Danqi Chen团队给出了一个很漂亮的方案——AggAgent,把聚合本身也做成一个智能体任务,让聚合Agent像调查员一样,拿着轻量工具去"翻阅"并行轨迹,按需提取信息,交叉验证,最终综合出答案。6个基准、3个模型家族,AggAgent全面碾压所有现有聚合方法,平均提升最高5.3个点,深度研究任务直接涨10.3个点。
而且开销极低——8路并行只多花5.7%的额外成本,而对比方法Summary Aggregation要花41%。
📖 核心摘要
并行测试时扩展在数学推理上已经被验证有效,但智能体任务带来了独特挑战:轨迹长、多轮、带工具调用,输出是开放式的。现有聚合方法要么只看最终答案丢了轨迹信息,要么压缩轨迹导致信息损失,要么直接塞进context直接爆窗口。AggAgent的思路是把并行轨迹当成一个"环境",聚合Agent配备4个轻量工具(获取解、关键词搜索、读取片段、提交答案)在这个环境里按需导航和综合信息。全程保真、低成本,聚合开销受限于单次Agent推演的context窗口。
📝 论文信息
- 标题:Agentic Aggregation for Parallel Scaling of Long-Horizon Agentic Tasks
- 作者:Yoonsang Lee, Howard Yen, Xi Ye, Danqi Chen
- 机构:Princeton University
- 链接:arxiv.org/abs/2604.11753
- 提交日期:2026年4月13日
🎯 为什么需要这篇论文
先聊聊并行扩展这件事。在数学推理领域,test-time compute scaling已经不是什么新鲜概念了——从Self-Consistency的majority voting,到Best-of-N加上reward model打分,再到DeepSeek-R1那样的learning-based aggregation,思路很清晰:多跑几次,挑最好的,或者综合几次的结果。
但把这些方法搬到智能体任务上,问题来了。
智能体任务的轨迹和CoT推理完全不一样。一道数学题的推理链可能几千token,一个深度研究Agent的轨迹动辄几万甚至十几万token,里面穿插着搜索、访问网页、提取信息的工具调用和返回结果。更关键的是,正确信息可能分散在不同轨迹的不同位置——轨迹A在第3步找到了关键证据,轨迹B在第17步发现了矛盾点,轨迹C的最终答案虽然错了但中间某段推理特别有价值。
你想想看,这种情况下怎么聚合?

图1:三种聚合方法的对比。上面是3条并行轨迹,下面从左到右分别是Solution Aggregation(只看最终答案)、Summary Aggregation(压缩轨迹再聚合)、AggAgent(用工具按需翻阅轨迹,保真低成本)
论文用一张表把现有方法的局限性总结得很清楚:
| 方法 | 任务通用 | 非启发式 | 利用轨迹信息 | 全保真 | 聚合成本 |
|---|---|---|---|---|---|
| Majority Voting | ✗ | ✗ | ✗ | ✗ | 零 |
| Weighted MV | ✗ | ✗ | ✗ | ✗ | 零 |
| Best-of-N | ✓ | ✗ | ✗ | ✗ | 零 |
| Fewest Tool Calls | ✓ | ✗ | ✗ | ✗ | 零 |
| Solution Agg | ✓ | ✓ | ✗ | ✗ | 低 |
| Summary Agg | ✓ | ✓ | ✓ | ✗ | 高 |
| AggAgent | ✓ | ✓ | ✓ | ✓ | 低 |
这张表已经说明了核心问题:没有一种现有方法同时做到任务通用、非启发式、利用轨迹信息、全保真、低成本。 AggAgent是唯一全优解。
🏗️ AggAgent怎么做
核心思路:把轨迹当环境
AggAgent的设计哲学很简洁——既然Agent天生就会跟环境交互,那为什么不把"一堆并行轨迹"也变成一个环境呢?
具体来说,AggAgent收到的初始信息是:问题\(q\) + 每条轨迹的元数据(步数、token数、工具使用统计)。轨迹本身不在context里,而是作为"环境"存在内存中,Agent按需检索。
这个设计直接解决了"8条轨迹塞不进context"的问题——Agent不需要一次性加载所有内容,而是像翻书一样,想看哪段看哪段。
四个工具
AggAgent配备了4个轻量级工具:
-
get_solution(traj_id):获取轨迹的最终解。不指定traj_id则返回所有\(K\)个解。这一步让Agent快速了解各轨迹的结论,发现共识和分歧。 -
search_trajectory(traj_id, query, role, k):在单条轨迹内做关键词搜索,按ROUGE-L排序返回top-k匹配的步骤。这是最常用的工具——先粗定位,再细看。 -
get_segment(traj_id, start_step, end_step):读取轨迹中连续一段步骤的完整内容,包括thinking block和工具返回结果。当关键词搜索不够时,才深入阅读。 -
finish(solution, reason):提交最终答案和理由。
从粗到细的调查流程
这个工具设计体现了一个很自然的"从粗到细"工作流:
- 先扫全局:调一次
get_solution,看看\(K\)条轨迹各自的结论是什么 - 发现分歧:哪些轨迹答案一致?哪些不一致?不一致的地方值得深入调查
- 定位证据:用
search_trajectory关键词搜索,找到关键论断对应的步骤 - 深入验证:对搜索结果不够确定的,用
get_segment读取完整上下文 - 综合出答案:交叉验证完毕,调
finish提交
整个过程就像一个侦探在翻阅8份调查报告——先看每份报告的结论,发现矛盾点后去翻对应章节,确认关键证据。
而且这些工具全部在内存中操作,不涉及外部API调用,零额外API成本和延迟。
🧪 实验设置
6个基准,分两大类
智能体搜索(答案型任务): - BrowseComp:高难度事实问答,需要多步网络浏览 - BrowseComp-Plus:BrowseComp的控制评估版,用本地知识库替代网络搜索 - HLE:跨学科专家级问题 - DeepSearchQA:多答案查询,需要找全所有合法答案
深度研究(长文本生成任务): - Healthbench-Hard:医学领域长文本回答 - ResearchRubrics:开放式研究任务,按多标准评分
3个模型家族
- GLM-4.7-Flash(30B)
- Qwen3.5-122B-A10B(122B)
- MiniMax-M2.5(229B)
每个模型跑8条独立轨迹(\(K=8\)),聚合时用同一个模型。Agent框架用的是通义千问的DeepResearch,支持原生function calling,128K context窗口,最多100次工具调用。
📊 实验结果
主实验:全面领先
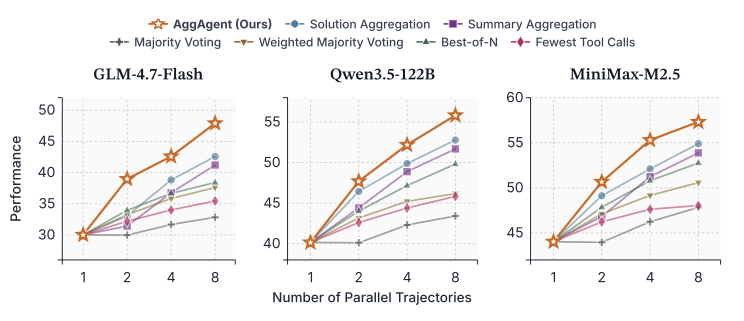
图2:AggAgent在6个基准上的平均表现,随并行轨迹数K的变化。三个模型上都是最优。
来看\(K=8\)的核心数据,这张表值得细看:
| 任务 | Pass@1 | MV | WMV | BoN | FewTool | SolAgg | SummAgg | AggAgent |
|---|---|---|---|---|---|---|---|---|
| GLM-4.7-Flash | ||||||||
| BrowseComp | 27.4 | 32.7 | 50.7 | 51.3 | 41.3 | 53.3 | 55.3 | 56.0 |
| BrowseComp-Plus | 49.1 | 59.3 | 68.7 | 68.7 | 62.0 | 70.7 | 70.7 | 71.3 |
| HLE | 25.0 | 26.5 | 27.7 | 31.0 | 27.1 | 32.9 | 34.8 | 37.4 |
| DeepSearchQA | 32.4 | -- | -- | 35.3 | 33.3 | 46.0 | 47.3 | 49.3 |
| Healthbench-Hard | 8.7 | -- | -- | 9.9 | 8.9 | 15.7 | 7.4 | 28.0 |
| ResearchRubrics | 37.5 | -- | -- | 37.7 | 35.2 | 36.8 | 31.7 | 45.3 |
| 平均 | 30.0 | 32.8 | 37.6 | 39.0 | 34.7 | 42.6 | 41.2 | 47.9 |
| Qwen3.5-122B | ||||||||
| 平均 | 40.2 | 43.4 | 46.2 | 49.8 | 45.8 | 52.8 | 51.7 | 55.8 |
| MiniMax-M2.5 | ||||||||
| 平均 | 44.0 | 47.8 | 50.6 | 52.8 | 48.0 | 54.9 | 53.9 | 57.3 |
几个关键观察:
AggAgent比最强基线SolAgg平均高2.4-5.3个点。 这说明只看最终答案确实丢信息,AggAgent通过翻阅轨迹找回了不少被丢弃的关键证据。
深度研究任务上差距更大。 以GLM-4.7为例,Healthbench-Hard上AggAgent拿到28.0,而SolAgg只有15.7,SummAgg更是惨到7.4。ResearchRubrics上AggAgent 45.3 vs SolAgg 36.8。长文本生成任务特别需要轨迹中的细节信息,压缩或丢弃都会导致质量严重下降。
Summary Aggregation在深度研究上翻车了。 这点挺有意思——SummAgg在搜索任务上表现还行,但在Healthbench-Hard上只有7.4,甚至不如Pass@1的8.7。轨迹压缩对长文本生成是致命的,一压缩,细节和连贯性全丢了。
启发式方法在多答案/长文本任务上直接废掉。 Majority Voting和Weighted MV对DeepSearchQA、Healthbench-Hard、ResearchRubrics根本不适用(表中的"--"),因为这些任务的答案没法直接投票。
成本和延迟:Pareto最优
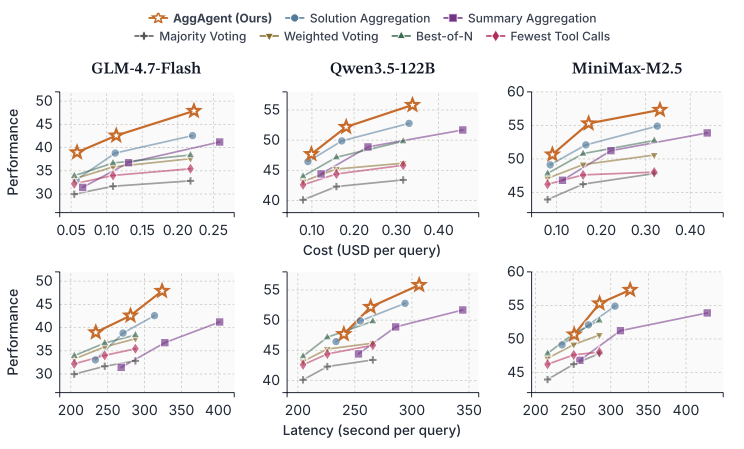
图3:三种聚合方法的成本(上)和延迟(下)vs 性能。AggAgent在每个模型上都是Pareto最优。
这张图最能说明AggAgent的性价比。以GLM-4.7为例:
- \(K=8\)时,AggAgent的额外聚合成本只占rollout成本的5.7%
- 同样条件下,Summary Aggregation占41%
- Solution Aggregation占3.7%,但性能差一大截
更令人惊讶的是,随着\(K\)增加,AggAgent的聚合成本并没有线性增长。论文给出了解释:更多轨迹意味着更强的支撑证据,有时反而让聚合变得更容易,部分抵消了额外计算。
更强的聚合模型 = 更好的效果
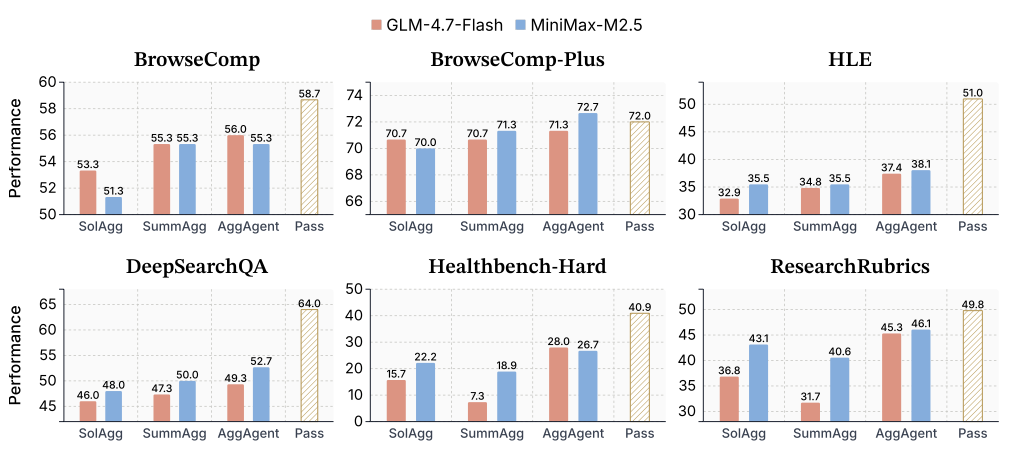
图4:用MiniMax-M2.5替代GLM-4.7做聚合,蓝柱是强聚合器,红柱是同模型聚合。
作者做了一个很有工程价值的实验:用弱模型(GLM-4.7)做8路rollout,用强模型(MiniMax-M2.5)做聚合。
结果很清楚——强模型做聚合确实有帮助,而且AggAgent受益最大。用MiniMax做聚合的AggAgent甚至在BrowseComp-Plus上超过了Pass@8——聚合不只是在"选最好的",而是真的在综合出超越任何单条轨迹的答案。
这个发现指向一个很实用的部署策略:非对称模型分配——用便宜的小模型并行跑8条轨迹,用强模型做聚合。毕竟聚合只消耗一次推理的成本,但能显著提升最终质量。
🔬 深入分析
合成 vs 选择:为什么合成更好
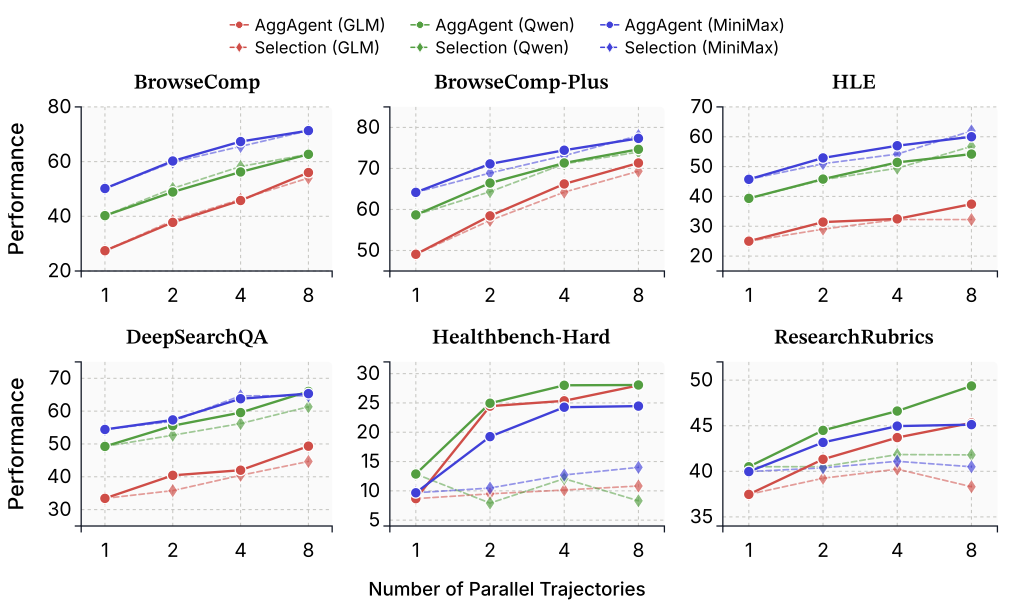
图5:AggAgent(合成新答案)vs 选择最佳轨迹的对比。实线是AggAgent,虚线是选择变体。
一个自然的疑问:AggAgent综合出一条新答案,和直接选一条最好的轨迹,效果差多少?
消融实验的结论是:合成整体优于选择,在深度研究任务上优势特别大。
原因很直觉——在搜索任务上,轨迹通常"要么对要么错",选择还行得通。但在深度研究上,质量是分散的:轨迹A的研究框架好,轨迹B的数据引用准,轨迹C的分析角度独特。没有单条轨迹全局最优,但合成可以从每条轨迹中取最好的部分。
这其实呼应了一个更深层的问题:开放式任务的正确性是组合性的,不是选择性的。
工具使用模式
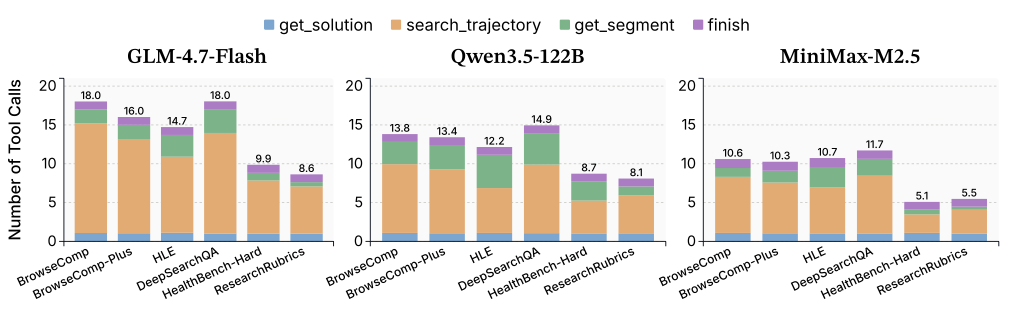
图6:AggAgent平均每次查询的工具调用次数。search_trajectory占了大头,get_segment使用较少,体现粗到细的策略。
工具使用统计也验证了"从粗到细"的工作流假设:
search_trajectory占工具调用的大头——先搜关键词定位get_solution和finish各约调1次——开头扫一遍答案,结尾提交get_segment用得相对少——只在关键词搜索不够时才深入阅读完整上下文
还有一个有趣的发现:越强的模型工具调用越少。 MiniMax-M2.5比GLM-4.7用了更少的工具调用就达到了更好的效果,说明强模型更善于判断"哪些信息值得深挖"。
四种关键行为

图7:AggAgent展现的四种关键行为:少数派答案识别、分歧解决、跨轨迹合成、启发式信号利用。
定性分析揭示了AggAgent的四种核心能力:
- 少数派答案识别:8条轨迹里只有2条给了正确答案,AggAgent能通过交叉验证发现少数派才是对的
- 分歧解决:不同轨迹的结论相互矛盾,AggAgent深入查阅证据后做出裁决
- 跨轨迹合成:所有轨迹的最终答案都是错的,但AggAgent从不同轨迹中各取正确片段,拼出正确答案
- 启发式信号利用:AggAgent会参考majority和confidence作为线索,但不会盲从
第3种行为最打动我——这证明了AggAgent不只是"在已有的好答案里挑",而是真的在做知识组合。
🤔 我的判断
说实话,这篇论文的idea并不复杂——"把轨迹当环境,给聚合Agent配工具",听起来甚至有点trivial。但就是这种简单的insight,往往是最有价值的。
亮点:
- 问题定义精准。 并行扩展在Agent任务上的聚合问题确实是一个被忽视的痛点,现有方法要么丢信息要么爆窗口,这是一个真实的工程瓶颈。
- 设计优雅。 4个工具的从粗到细设计,不是拍脑袋想出来的,而是对应了人类调查员的工作方式。而且全部在内存操作,没有外部API开销。
- 性价比惊人。 5.7%的额外成本换来5.3个点的平均提升和10.3个点的深度研究提升,这个ROI在生产环境中非常有吸引力。
- 非对称模型分配。 弱模型rollout + 强模型聚合的思路,对实际部署很有指导意义。
但也有值得追问的地方:
- 工具设计的手工性。 4个工具是人工设计的,为什么是这4个?能不能让模型自己发明工具?或者用RL来优化工具的使用策略?目前是zero-shot用off-the-shelf LLM,如果对聚合Agent做fine-tuning效果会不会更好?论文只是提到了这个方向但没实验。
- 只验证了搜索和研究类任务。 6个基准都是信息检索和生成为主的,那在软件工程(SWE-bench)或网页操作(WebArena)这种动作空间更大的场景下,AggAgent的"翻阅轨迹"策略还work吗?这些任务的轨迹可能更多是"做了什么操作"而非"找到了什么信息",搜索关键词的策略可能需要调整。
- 与同期工作的对比不够充分。 KARL是同期工作,把最终答案喂回rollout Agent继续推理——这其实也是一种agentic聚合,只是没有利用完整轨迹。论文只提了一句,没有实验对比。如果能和KARL直接PK一下会更convincing。
不过话说回来,这篇论文最值钱的地方不在于某个具体技术细节,而在于它确立了一个范式:聚合本身也是智能体任务。 这个框架是可扩展的——你可以换更强的聚合模型、加更多工具、甚至训练专门的聚合Agent。AggAgent只是这个范式的一个起点,后续还有很大的探索空间。
如果你在做多Agent系统或者深度研究产品,这个思路值得认真试试。5.7%的成本加10个点的效果提升,这笔账怎么算都划算。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新AI前沿,关注我