Anthropic Managed Agents: 把"脑"和"手"拆开,Agent 基础设施才算真正成熟
你有没有碰到过这种情况——费了好大劲给 Agent 写了一套 harness(工具编排、上下文管理、错误恢复那些),换个模型一跑,发现之前加的一堆"补丁"全成了累赘?
Anthropic 自己就踩了这个坑。他们之前发现 Claude Sonnet 4.5 有个毛病:快到上下文窗口极限的时候会"紧张"——开始走捷径、提前收尾、用"剩下的留给用户"糊弄你。这个行为他们起了个很传神的名字:context anxiety(上下文焦虑)。于是在 harness 里加了 context reset 机制来治。
结果呢?换成 Opus 4.5 一跑,这个毛病没了。之前加的 reset 变成了 dead weight。
这就是 harness 工程的宿命:你写的每一行 harness 代码,都是在假设模型"做不到某件事"。但模型在进步,这些假设会过时。
Anthropic 最新发布的 Managed Agents 就是为了解决这个问题。不是又一套 Agent 框架,而是一套面向长期演进的 Agent 运行时基础设施——把 Agent 的组件虚拟化成稳定接口,底层实现随便换,上层不用动。
坦率讲,这篇工程博客可能是 2026 年迄今为止对 Agent 基础设施思考最深的一篇文章。
📖 文章信息
- 标题:Scaling Managed Agents: Decoupling the brain from the hands
- 作者:Lance Martin, Gabe Cemaj, Michael Cohen(Agents API 团队)
- 机构:Anthropic
- 日期:2026年4月8日
- 链接:anthropic.com/engineering/managed-agents
🎯 核心问题:为什么现有 Agent 架构注定要被推翻?
做过 Agent 开发的人大概都有体会:Agent 系统最脆弱的不是模型,而是围绕模型搭建的那套脚手架——harness。
Harness 里面塞满了各种"假设":
- 模型不会自己管理上下文 → 加上下文压缩/重置
- 模型容易跑偏 → 加各种 guardrail 和检查点
- 模型做不了多步规划 → 加 plan-then-execute 框架
这些假设在某个特定模型版本上是合理的,但问题在于,模型的能力在以月为单位地提升。上个月需要 harness 帮忙做的事,这个月模型自己就能做了。你的 harness 代码不但没帮忙,反而成了绊脚石。
Anthropic 的判断是:与其不断修修补补,不如从架构层面解决——把 Agent 的组件虚拟化成一组稳定的接口,让实现可以自由更换。
这个思路其实很"操作系统"。几十年前,操作系统通过虚拟化硬件(进程、文件)解决了"为尚未发明的程序做设计"的问题。read() 系统调用不管你底层是 1970 年代的磁盘还是现代 SSD,接口不变。Managed Agents 走的是同一条路。
🏗 架构设计:三个虚拟化组件
Managed Agents 把 Agent 拆成了三个独立的虚拟化组件:
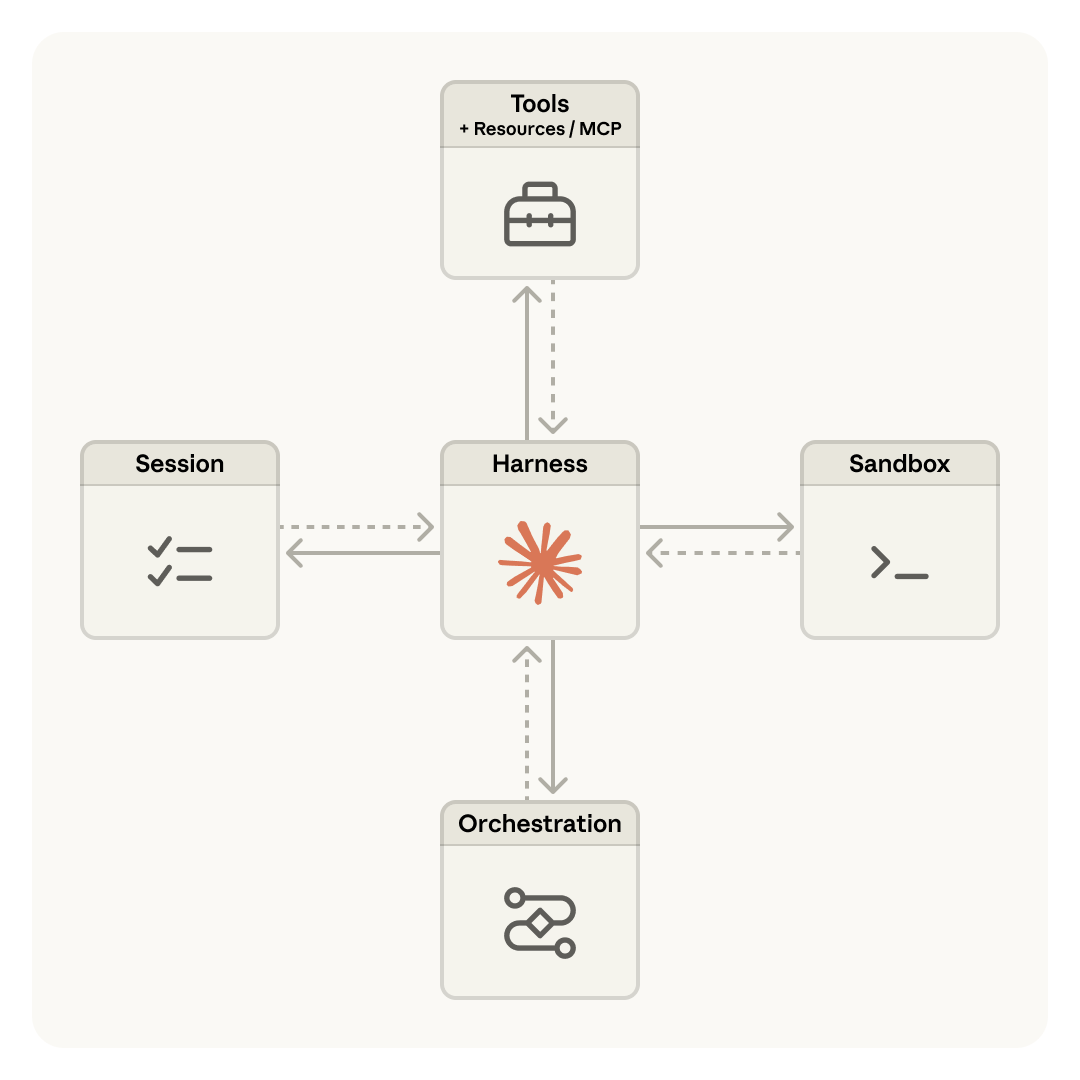
Managed Agents 的核心架构:Harness 作为中枢,通过标准化接口连接四个外围组件。每个组件都可以独立替换和扩展。
Session:不是上下文窗口,而是事件日志
Session 是一个 append-only 的事件日志,存储在 harness 外部。它记录了 Agent 运行过程中发生的一切——每次模型调用、每次工具执行、每次结果返回。
关键接口:
getSession(session_id) -> (Session, Event[])
getEvents(session_id) -> PendingEvent[] // 未处理的事件
emitEvent(id, event) // 追加事件
这个设计的精妙之处在于:Session 不等于 Claude 的上下文窗口。上下文窗口是 Claude 当前"看到"的内容,而 Session 是外部的持久化存储。Harness 可以从 Session 里按需取切片,做变换,再喂给 Claude。
你想想看,这解决了一个很实际的问题:传统做法是在 Claude 的上下文窗口里做"不可逆的裁剪决策"——删掉的信息就再也找不回来了。但有了外部 Session,harness 可以随时回溯、重读、甚至从某个特定时间点重新开始。
Harness:无状态的"脑"
Harness 是调用 Claude 并路由工具调用的循环——也就是"脑"。关键变化是它变成了无状态的。
Harness 不再绑定在某个容器里。它从 Session 读取状态,执行一轮推理,把结果写回 Session,然后可以随时被替换。挂了?新起一个,从 Session 恢复。
Sandbox:可替换的"手"
Sandbox 是代码执行环境——容器、虚拟机、甚至手机模拟器都行。
文章里有句话让我印象比较深:"agnostic as to whether the sandbox is a container, a phone, or a Pokémon emulator"。Sandbox 只要能 provision 和 execute,什么形态都行。
🔧 从"宠物"到"牲畜":解耦如何解决实际工程问题
Anthropic 最初的设计是把 Session、Harness、Sandbox 塞进一个容器里。结果碰到了经典的分布式系统问题:
容器挂了,Session 就没了。 而且你根本分不清到底是 harness bug、网络故障还是容器崩溃导致的问题。
这就是分布式系统里经典的"pets vs cattle"问题。当你的容器是"宠物"(pet)——每一个都精心呵护、不能丢——你就完蛋了。你需要的是"牲畜"(cattle)——坏了一个,随时换新的,业务不受影响。
解耦之后的效果非常直接:
| 指标 | 改进幅度 |
|---|---|
| Time-to-First-Token (p50) | 下降约 60% |
| Time-to-First-Token (p95) | 下降超过 90% |
p95 延迟砍了 90% 以上,这个数相当炸裂。
原因也很直觉:解耦之后,容器只在真正需要代码执行时才拉起。推理可以立即开始(从 Session 日志恢复状态),不用等 Sandbox 初始化完。
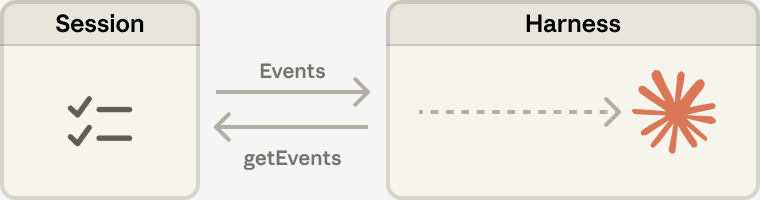
Session 和 Harness 之间的交互:Harness 通过 getEvents 拉取待处理事件,推理后再把新事件写回 Session。
🔐 安全架构:凭证永远不进 Sandbox
解耦带来的另一个好处是安全边界变得非常清晰:Claude 生成的代码在 Sandbox 里跑,但凭证永远不进 Sandbox。
两种认证模式:
模式一:资源绑定认证。 Git 仓库的 access token 在 Sandbox 初始化阶段就配好了 local remote,Agent 直接 push/pull 就行,不需要也看不到 token。
模式二:Vault 代理认证。 OAuth token 存在外部 vault 里,MCP 工具调用通过一个 proxy 层访问——proxy 从 vault 取凭证,发起真实请求,Agent 全程接触不到 token。
这个设计解决了一个我在做 Agent 安全时一直头疼的问题:你怎么让 Agent 有权限用工具,但又不让它能把凭证"偷走"? Anthropic 的答案是物理隔离——凭证和代码执行不在同一个进程空间里。
🧠 上下文管理:从"不可逆裁剪"到"按需切片"
传统 Agent 的上下文管理是这样的:窗口快满了 → 让模型总结/压缩 → 删掉旧内容 → 继续。这是一个不可逆决策,删错了就再也找不回来。
Managed Agents 的做法完全不同。Session 作为外部持久化日志,Harness 可以:
- 从上次读取的位置继续:正常推进
- 回溯到某个特定事件之前:需要重新审视之前的决策
- 重读之前的上下文切片:需要回忆某个早期的信息
- 对事件流做变换后再喂给 Claude:过滤、聚合、摘要都行
这就像从"只有一个编辑器 buffer,存满了就得删"变成了"有一个无限的 git log,随时 checkout 任意版本"。
📊 扩展架构:多脑多手
解耦之后,扩展变得非常自然:
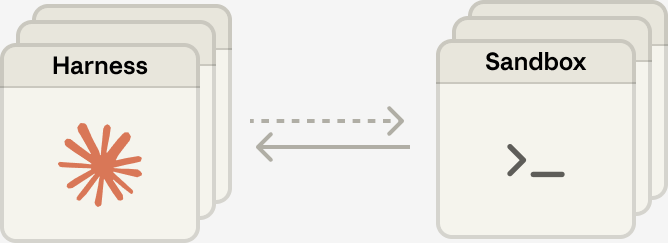
多 Harness 对多 Sandbox:无状态的 Harness 可以水平扩展,每个 Harness 可以连接多个 Sandbox。
多脑(Many Brains):Harness 是无状态的,可以随意水平扩展。不需要为每个"脑"维护一个容器。
多手(Many Hands):一个 Harness 可以连接多个 Sandbox,每个 Sandbox 是一个独立的工具。而且 Harness 之间还能互相传递工具——这就为 multi-agent 协作打开了大门。
跨 VPC 部署:因为组件之间通过接口通信而非共享内存,可以跨 VPC 部署,不需要 network peering。
🔬 完整的接口设计
这张图是整篇文章的精华——Managed Agents 的七个核心组件及其接口:

七个组件的接口规范。每个接口都足够抽象,可以被不同的实现满足——Postgres 可以做 Session,cron job 可以做 Orchestration,MCP server 可以做 Tools。
几个值得注意的设计选择:
- Session 的 "Satisfied by" 是 "Any append-only log":Postgres、SQLite、甚至内存数组都行。门槛低得惊人。
- Orchestration 就是一个
wake(session_id) -> void:cron job、消息队列、甚至一个 while-loop 都算。 - Sandbox 的接口只有两个:
provision和execute。极简。
这种设计哲学很 Unix:每个组件做一件事,通过标准接口组合。
🤔 我的判断
亮点:
-
操作系统类比不是噱头,是真的在这么做。 把 Agent 组件虚拟化、通过稳定接口隔离实现——这是我见过的对 Agent 基础设施最有远见的架构设计。大多数 Agent 框架还在纠结"用 LangChain 还是 CrewAI",Anthropic 已经在想"怎么设计一套接口让底层框架随便换"了。
-
Session 外置这个决策太对了。 上下文管理从"不可逆裁剪"变成"按需切片",一下子解锁了很多之前不可能的 capability——回溯、重放、分支。这对长时间运行的 Agent 任务来说是质的提升。
-
安全模型很工程化。 不是靠 prompt injection 防御(那些方法都不靠谱),而是通过物理隔离解决凭证安全问题。"凭证不进 Sandbox"这一条规则,比任何花哨的安全检测都管用。
-
p95 延迟降 90% 这个数据很能打。说明解耦不只是架构美感,是真的有性能收益。
让我皱眉的地方:
-
这是个全托管服务。 Managed Agents 跑在 Anthropic 的平台上,不是你自己的基础设施。对于数据敏感的企业来说,这个门槛可能比技术难度更高。文章没有讨论 self-hosted 的可能性。
-
接口设计的"极简"是双刃剑。
execute(name, input) -> String——所有工具调用返回 String?对于结构化输出、流式传输、大文件传递这些场景,这个接口够用吗?实际工程中可能需要更多的语义。 -
multi-agent 的协作模式还很模糊。 文章提到 Harness 之间可以传递工具,但没有展开讨论协调机制、状态同步、冲突解决这些问题。multi-brain 的故事才刚开了个头。
-
跟 Claude Code 的关系没有讲清楚。 最近 Claude Code 源码泄露事件中暴露了它的 harness 架构(4700+ 文件的 TypeScript 工程),跟 Managed Agents 的设计理念高度一致——但文章里完全没有提及两者的关系和演进脉络。
-
缺乏第三方验证。 性能数据都是 Anthropic 自己报的,没有外部 benchmark。p50 降 60%、p95 降 90% 的基准是什么?跟什么对比?这些信息不够透明。
💡 工程启发
如果你也在做 Agent 基础设施,这篇文章有几个核心 takeaway:
1. Harness 里的每一行代码都有保质期。 当你写 if model can't do X, then harness does X 的时候,要想清楚这个假设的半衰期。模型能力进步的速度比你想的快。最好的 harness 代码是那些跟模型能力无关的——比如安全隔离、事件持久化。
2. Session 外置是值得抄的设计。 不管你用什么 Agent 框架,把 Agent 的运行历史存到一个外部的 append-only log 里,比塞在上下文窗口里好太多了。你获得的是:可回溯、可恢复、可分析。
3. 安全边界画在进程隔离上,不要画在 prompt 上。 "不要泄露凭证"这种指令在 prompt 里写一百遍也不如物理隔离一次管用。
4. 接口设计要比实现活得长。 这是整篇文章最重要的工程哲学。如果你的 Agent 系统跟某个特定的 LLM API、某个特定的工具框架绑定太紧,换一下就要大改——那你的架构就有问题了。
📝 对比:Managed Agents vs 其他 Agent 框架
| 维度 | Managed Agents | LangGraph / CrewAI 等 | 自建 Agent 系统 |
|---|---|---|---|
| 核心理念 | 组件虚拟化 + 稳定接口 | 框架 + 编排逻辑 | 自由度最高 |
| 状态管理 | 外部 Session(append-only) | 框架内置状态机 | 自定义 |
| 部署模式 | 全托管 | 自部署 | 自部署 |
| 模型绑定 | Claude only | 可换模型 | 可换模型 |
| Harness 更新 | 平台侧自动演进 | 手动升级框架 | 手动维护 |
| 安全模型 | 物理隔离 | 依赖框架实现 | 自定义 |
| 适用场景 | 长时间运行的复杂任务 | 中等复杂度编排 | 特殊需求 |
说到底,Anthropic 这篇文章真正在讲的不是"我们做了一个 Agent 服务",而是"Agent 基础设施应该怎么设计才能在模型快速迭代的时代活下来"。
答案是:把脑和手分开,让接口比实现活得长。
这个设计哲学不只适用于 Anthropic 的产品。任何做 Agent 系统的团队都值得认真想想:你的架构里,哪些部分是跟当前模型能力绑定的"假设代码",哪些部分是真正能长期存活的"基础设施代码"?
前者要做好随时被删的心理准备。后者才是你真正的资产。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新AI前沿,关注我