AI写的论文到底有多少幻觉?东京大学提出首个系统评估框架PaperRecon
你有没有注意到一个越来越尴尬的现象——AI写论文的能力越来越强,文章写得"看起来"漂亮极了,但你细看数据、细看方法描述,总能找到一堆编的。
这不是个案。去年ICLR就曝出过批量AI生成论文的投稿事件,审稿人发现这些论文"读起来流畅、结构完整",但实验数据经不起推敲、方法描述和实际代码对不上。问题是——没人能系统性地告诉你:AI写的论文到底"写得好不好"、"编了多少"。
东京大学的团队提出了 PaperRecon——据我所知是第一个专门评估AI写作论文质量的系统性框架。核心思路非常聪明:给AI一篇已有论文的压缩摘要,让它"重建"整篇论文,然后把重建结果和原文逐项对比。评估被分解成两个正交维度:表现力(Presentation)和幻觉(Hallucination)。
关键发现相当扎眼:Claude Code写出来的论文表现力更强,但平均每篇论文超过10个幻觉;Codex幻觉少(约3个),但写作质量明显差一截。这个trade-off,其实揭示了当前AI写作最核心的困境——写得好和写得对,还做不到同时兼顾。
📖 论文信息 - 标题:Paper Reconstruction Evaluation: Evaluating Presentation and Hallucination in AI-written Papers - 作者:Atsuyuki Miyai, Mashiro Toyooka, Zaiying Zhao, Kenta Watanabe, Toshihiko Yamasaki, Kiyoharu Aizawa - 机构:The University of Tokyo(东京大学) - 发表:2026年4月,投稿 COLM 2026 - 链接:arXiv:2604.01128 | 项目主页
🎯 问题动机:为什么需要评估AI写的论文?
AI驱动的科研自动化这两年爆发得很快。从 AI Scientist 到 DeepScientist,再到各种端到端的 AI 研究管线,"让AI自己做研究、自己写论文"已经不是幻想了。
但风险也在同步增长。最直接的问题是:AI写出来的论文,审稿人看不出问题。
之前的研究已经指出,AI审稿人(LLM-as-a-judge)在评估论文质量时有个要命的缺陷——编造了更多内容的论文,反而可能拿到更高的审稿分。这听起来很荒谬,但逻辑上说得通:编造的内容往往"自圆其说",读起来比真实但粗糙的描述更流畅。
现有的评估手段要么只关注表面问题(比如引用格式错误),要么依赖AI审稿打分(已经被证明不靠谱),缺少一个能够系统性地拆解"写得好不好"和"编了多少"的框架。
PaperRecon 就是为了填这个空。
🏗️ 方法核心:论文重建 + 双轴评估
核心思路
PaperRecon 的设计很有巧思。它不是直接让AI从零写一篇论文然后评判好坏——那样没有ground truth,评估只能靠主观判断。
它的做法是论文重建(Paper Reconstruction):
- 预处理:从一篇已有论文中提取压缩信息——一个结构化的
research_overview.md(平均463词),加上原文的图表、参考文献、代码(如果有的话) - 写作:让 coding agent(如 Claude Code 或 Codex)基于这些最小资源重建完整论文
- 评估:把生成的论文和原文逐项对比
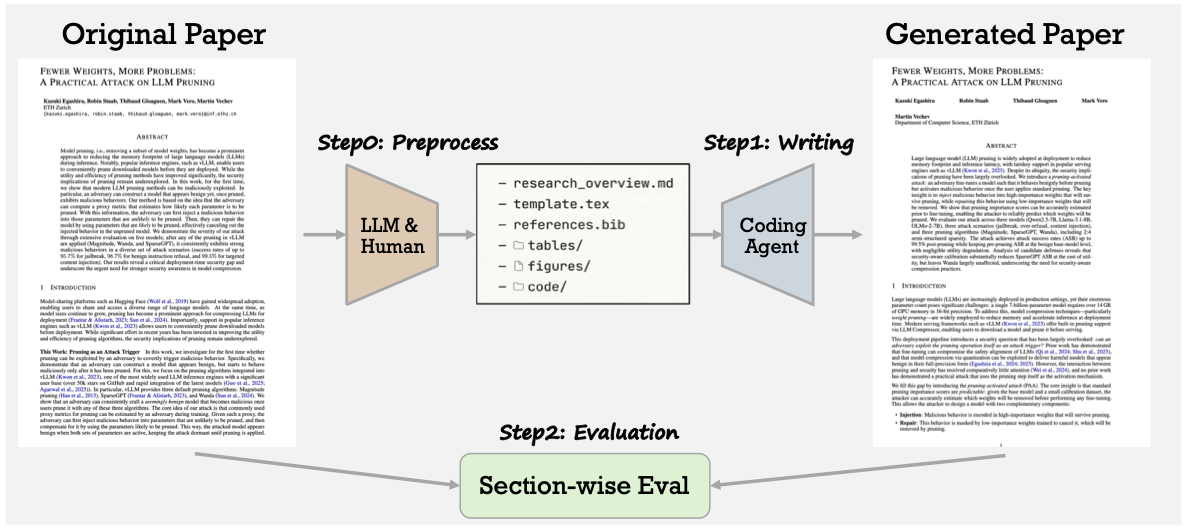
图1:PaperRecon整体流程。左侧是原始论文,中间通过LLM和人工提取出overview、模板、表格、图片等最小资源,右侧coding agent基于这些资源重建完整论文,最后与原文做section级对比评估。
这个设计的精巧之处在于:通过"重建"而非"创造",你就有了一个明确的参照物——原文。这样就能精准地衡量agent写了什么、漏了什么、编了什么。
双轴评估:表现力 × 幻觉
评估被分解为两个正交维度,这是论文最核心的设计:
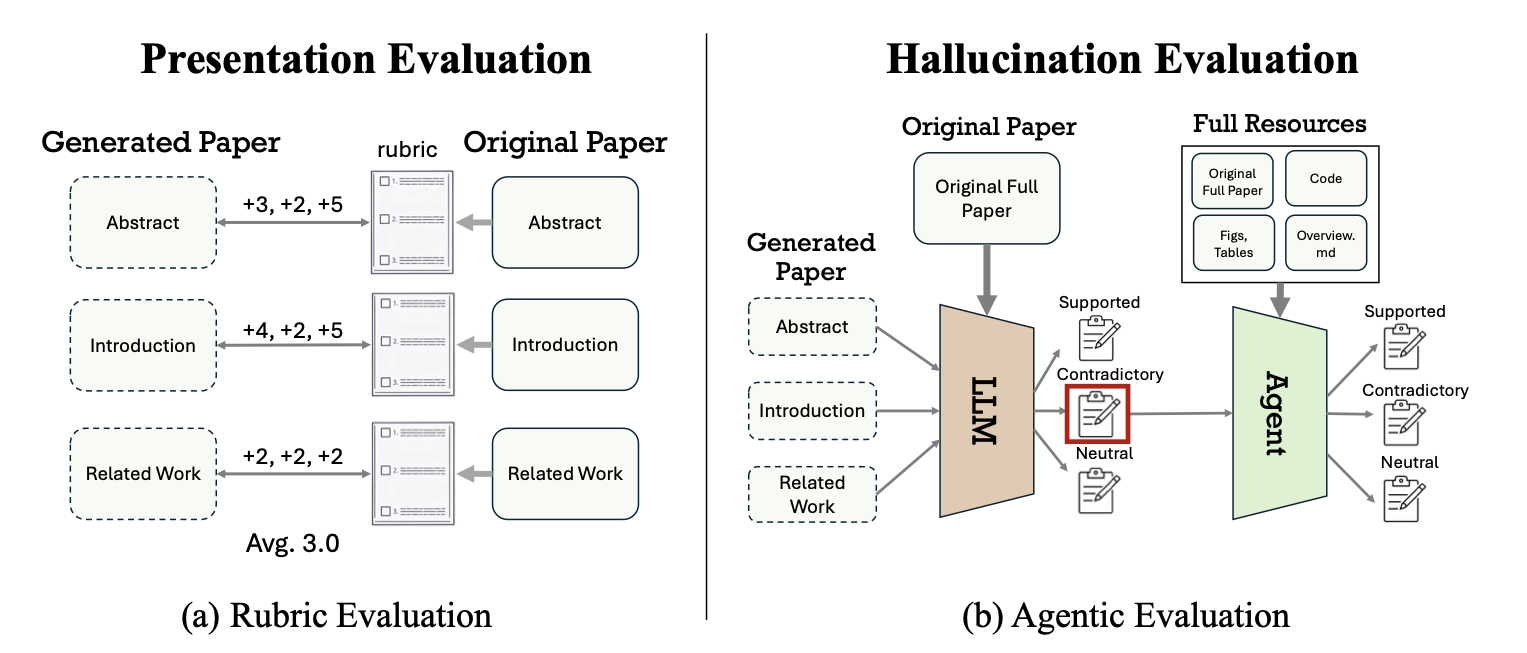
图2:左半部分是Rubric评估流程:对每个section预先构建评分标准(rubric),用LLM逐项打分(1-5分);右半部分是幻觉评估流程:两阶段设计,先用LLM提取并分类所有声明(claim),再用coding agent复核,减少误报。
表现力评估(Rubric Evaluation)
作者没用简单的LLM-as-a-judge——他们在预实验中发现这种方法的区分度太差。取而代之的是Rubric评估:
- 对每篇原始论文的每个section,预先构建一份评分标准(rubric),列出这个section应该包含的关键要素
- 比如Abstract的rubric可能包含"问题动机:提升视觉-语言模型的推理能力",Experiment的rubric可能包含"评估覆盖视觉推理和通用图像理解基准"
- 每个rubric元素按 1-5 分评估(5=完全准确描述,1=完全缺失)
- rubric先用GPT-5.4生成,再经人工审核修正
每个section的平均rubric元素数量:Abstract 10.3个,Introduction 13.3个,Related Work 12.6个,Method 14.2个,Benchmark Construction 14.6个,Experiment 14.3个。
此外,图表也被纳入了rubric评估: - 图片评估:检查生成论文中的图片是否出现在正确的section上下文中 - 表格评估:对比生成表格和原始表格的数值准确性、结构对齐度和内容一致性
幻觉评估(Hallucination Analysis)
这是两阶段设计:
第一阶段——Claim提取与分类:用GPT-5.4从生成论文的每个section中提取所有具体、可验证的声明(claim),并分为三类: - Supported:原文中直接陈述或可逻辑推导 - Neutral:原文中没有,但不矛盾(合理的补充说明) - Contradictory:与原文直接冲突——这才是幻觉
对于Contradictory类的claim,进一步区分严重程度:major(错误数值、编造结果、方法描述错误)和 minor(过度概括、用词不精确)。
第二阶段——Agent复核:把所有被标记为Contradictory的claim汇总,交给 Claude Code(Sonnet 4.6)重新验证,它会拿到原文的完整资源(LaTeX源码、代码、图表)来复查,把误判修正回Supported或Neutral。
这个两阶段设计挺务实的:第一阶段做粗筛(宁可多抓),第二阶段用agent精查(减少假阳性),而且只需要一次agent调用,控制了计算成本。
引用评估(Citation-Level Evaluation)
额外还有一个引用维度:比较生成论文和原文的引用key集合,计算Precision、Recall、F1,以及检测hallucinated citations(引用了bib文件中不存在的key)。
📊 PaperWrite-Bench:51篇论文的评测基准
作者构建了 PaperWrite-Bench,包含51篇2025年之后发表在顶会的论文,覆盖范围挺广:
| 领域 | 会议 | 论文数 | 小计 |
|---|---|---|---|
| ML | ICLR'26, NeurIPS'25, ICLR'25, ICML'25, AAAI'25 | 7+6+4+2+2 | 21 |
| CV | CVPR'25, ICCV'25, CVPR'26 | 16+3+2 | 21 |
| Multimedia | ACMMM'25 | 5 | 5 |
| NLP | ACL'25, NAACL'25 | 3+1 | 4 |
| 总计 | 51 |
51篇论文中,32篇提出新方法,12篇引入新基准,7篇两者兼有。
对比之前的类似基准:OpenAI的PaperBench(20篇ICML 2024论文)和Exp-Bench(56篇),这些基准主要评估AI复现实验结果的能力,论文大多来自2024年左右。PaperWrite-Bench则聚焦于写作能力评估,且时间更新。
🧪 实验结果:写得好 vs 写得对的trade-off
实验设置
评估了三种coding agent: - Claude Code(单agent):Sonnet 4 / Sonnet 4.6 - Codex(单agent):GPT-5 / GPT-5.4 - Claude Code Agent Teams(多agent):Sonnet 4.6
写作pipeline故意保持简单:只包含一个编译反馈循环(LaTeX报错时让agent修正)和一个页数调整步骤。目的是测量agent在最基本设置下的写作表现。
主实验:表现力评估
| Agent | Model | Abs. | Intro. | Rel. | Meth. | Bench. | Exp. | Avg. |
|---|---|---|---|---|---|---|---|---|
| Codex | GPT-5 | 4.00 | 3.58 | 2.32 | 2.89 | 3.25 | 3.53 | 3.26 |
| Codex | GPT-5.4 | 4.06 | 3.87 | 2.72 | 3.51 | 3.79 | 3.64 | 3.59 |
| ClaudeCode | Sonnet 4 | 4.10 | 3.88 | 2.48 | 3.23 | 3.63 | 3.66 | 3.49 |
| ClaudeCode | Sonnet 4.6 | 4.37 | 4.12 | 3.08 | 3.69 | 3.84 | 4.00 | 3.86 |
| ClaudeCode-Teams | Sonnet 4.6 | 4.28 | 4.05 | 3.07 | 3.62 | 3.99 | 3.97 | 3.82 |
几个值得注意的点:
- Claude Code全面压制Codex。在所有section上,Claude Code(Sonnet 4.6)都拿到了最高或接近最高分,平均3.86 vs Codex最好的3.59。
- Related Work是所有agent的短板。最高才3.08分——这其实可以理解,Related Work需要对文献脉络有深刻理解,纯靠overview很难重建。
- 最好的agent也只有3.86分(满分5分),说明离"忠实重建"还差得远。
- Claude Code-Teams(多agent)相比单agent Claude Code并没有明显优势,甚至某些section略低。我对这个结果有点意外,可能多agent协作在这种结构化写作任务上的收益有限。
主实验:幻觉评估
| Agent | Model | Abs. | Intro. | Rel. | Meth. | Bench. | Exp. | Total |
|---|---|---|---|---|---|---|---|---|
| Codex | GPT-5 | 0.3 | 0.6 | 0.3 | 3.8 | 1.9 | 3.4 | 10.2 |
| Codex | GPT-5.4 | 0.1 | 0.3 | 0.2 | 1.3 | 0.2 | 0.9 | 3.0 |
| ClaudeCode | Sonnet 4 | 0.2 | 0.5 | 0.5 | 5.4 | 0.8 | 4.7 | 12.0 |
| ClaudeCode | Sonnet 4.6 | 0.2 | 0.8 | 0.6 | 4.7 | 0.5 | 3.6 | 10.4 |
| ClaudeCode-Teams | Sonnet 4.6 | 0.3 | 0.6 | 0.8 | 3.9 | 0.5 | 3.8 | 9.8 |
这张表就很刺激了。
Codex(GPT-5.4)每篇论文平均只有3个幻觉,Claude Code(Sonnet 4.6)有10.4个。 差了3倍多。
幻觉的分布也很有意思:Method和Experiment是幻觉重灾区。这其实符合直觉——这两个section需要精确描述技术细节和实验数据,稍微"发挥"一下就容易编错。相比之下,Abstract和Introduction因为是高度概括性的内容,幻觉反而很少。
坦率地讲,Claude Code虽然写得好但编得多这个结论,对我来说是有点反直觉的。你可能会猜:是不是因为它"写得多"所以"错得多"?但作者评估的是major contradictory claims——直接和原文矛盾的硬错误,不是细节上的差异。这说明Claude Code在追求表现力的过程中,确实更容易"自信地编造"技术细节。
引用评估
| Agent | Model | Prec. | Recall | F1 | Hal. |
|---|---|---|---|---|---|
| Codex | GPT-5 | 0.89 | 0.27 | 0.39 | 0.0 |
| Codex | GPT-5.4 | 0.86 | 0.43 | 0.56 | 0.0 |
| ClaudeCode | Sonnet 4 | 0.75 | 0.24 | 0.34 | 3.5 |
| ClaudeCode | Sonnet 4.6 | 0.83 | 0.58 | 0.67 | 0.2 |
| ClaudeCode-Teams | Sonnet 4.6 | 0.84 | 0.56 | 0.66 | 0.2 |
同样的模式:Codex引用精度高且零幻觉引用,但召回率低(引用不够多)。Claude Code引用覆盖面广(F1最高0.67),但会编造引用(Sonnet 4甚至平均3.5个幻觉引用/篇)。
🔬 消融实验与深入分析
Overview长度的影响
| Overview | Rubric(Sonnet 4) | Rubric(Sonnet 4.6) | Hal.(Sonnet 4) | Hal.(Sonnet 4.6) |
|---|---|---|---|---|
| Default(463词) | 3.49 | 3.83 | 8.8 | 9.8 |
| Long(1492词) | 3.64 | 4.17 | 5.8 | 2.3 |
给的信息越详细,写得越好、编得越少。Sonnet 4.6搭配Long overview时,幻觉从9.8降到2.3——从"满纸荒唐"降到"基本靠谱"。这也从侧面验证了评估指标的合理性。
这个结论对工程实践的启示很直接:如果你真的要用AI写论文(比如作为辅助工具),给它提供的上下文信息越充分,输出质量越高、风险越低。
不同领域的表现差异
| 领域 | 论文数 | Rubric ↑ | Hal. ↓ |
|---|---|---|---|
| ML | 21 | 3.58 | 8.3 |
| CV | 21 | 3.63 | 10.1 |
| MM | 5 | 3.47 | 10.7 |
| NLP | 4 | 3.77 | 6.0 |
NLP论文的重建质量最高、幻觉最少。作者分析原因是NLP论文更偏向findings-based的研究风格,方法中的数学公式和复杂技术描述相对少——你想想看,"好写"的论文agent自然也写得更好。
CV和MM论文的幻觉数量明显更高(10+),大概是因为这些领域的方法部分通常涉及更多的架构细节和数值,agent更容易编造。
人类验证
表现力验证:用72对生成论文做了人类成对比较,Kendall's \(\tau_b = 0.578\)(\(p \lt 0.001\)),说明rubric评估和人类专家判断有较强相关性。
幻觉验证:从GPT-5、GPT-5.4和Sonnet 4.6的生成论文中抽取了97个被标记为major contradictory的claim,人工复核发现 96%确实是真正的幻觉。精度相当高。
💡 我的判断
这篇论文做对了什么
- 评估框架的设计有品味。把"写得好"和"写得对"拆成两个正交维度来评估,这个直觉是对的。之前的工作要么只看审稿分(容易被漂亮但虚假的内容骗过),要么只检查表面错误(引用格式之类),都不够。
- 论文重建这个任务设计很聪明。给了你一个ground truth来做对比,避免了开放式评估中"没有标准答案"的困境。
- trade-off的发现很有价值。Claude Code写得好但编得多,Codex谨慎但表现力差——这不仅是对这两个工具的评测,更揭示了当前LLM在生成场景中的一个结构性矛盾。
有什么可以挑战的
- 评估的评估问题。rubric是先用GPT-5.4生成再人工修正的,幻觉检测也依赖LLM。那这些评估工具自身的幻觉怎么办?人工验证覆盖了97个case(精度96%),但这只验证了幻觉检测的精度,没有验证召回——可能还有很多幻觉没被抓到。
- overview压缩了多少信息? 平均463词的overview要重建一篇完整论文,信息丢失是不可避免的。所以"重建不准确"到底是agent写作能力不行,还是给的信息本来就不够?Long overview的消融实验部分回答了这个问题,但没有完全消除这个concern。
- 51篇论文的样本量和领域覆盖。NLP只有4篇、MM只有5篇,这些领域的结论稳健性值得打个问号。
- 写作pipeline过于简单。作者自己也承认了,只用了编译反馈循环和页数调整。实际场景中,AI写作通常会配合检索增强、多轮修改、人工干预等,这里评估的更像是agent的"裸写"能力。
对工程实践的启发
- 如果你在用Claude Code或类似工具辅助写作,Method和Experiment部分必须人工逐句复核。幻觉密度在这里最高。
- 给agent提供的上下文越丰富越好。Long overview把幻觉从10降到2-3,信息充分性对输出质量的影响是决定性的。
- 这个评估框架本身是可复用的——如果你在构建自己的AI写作pipeline,PaperRecon的rubric + 两阶段幻觉检测是一个值得借鉴的评估范式。
📝 收尾
PaperRecon 是一个及时且必要的工作。AI写论文已经从"实验性玩具"走向了"真实投稿",但我们对AI写作的质量和风险的理解还远远不够。这篇论文给出了一个可操作的评估框架,并且用数据揭示了一个重要的事实:当前最强的coding agent,写出来的论文平均每篇有3-12个编造的硬错误。
这个数字应该让所有想用AI"一键生成论文"的人冷静一下。
但同时也要看到积极的一面:模型升级确实在减少幻觉(GPT-5到GPT-5.4,从10.2降到3.0)。方向是对的,只是离终点还远。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新AI前沿,关注公众号:机器懂语言