推理偷工减料?上下文是如何悄悄"缩短"大模型思考过程的
论文标题:Reasoning Shift: How Context Silently Shortens LLM Reasoning
作者:Gleb Rodionov
机构:Yandex
论文链接:https://arxiv.org/abs/2604.01161
日期:2026年4月1日
🎯 核心摘要
你让同一个推理模型解同一道数学题,但在题目前面加了一段无关文字,或者是在多轮对话的第二轮提问——模型的推理链居然短了一半,自我检查行为大幅减少,在困难任务上的准确率也跟着下降了。这篇来自 Yandex 的 working paper 揭示了一个被忽视的脆弱性:推理模型的"深度思考"能力并不稳定,它会被上下文条件悄悄地压缩。论文在 Qwen3.5-27B、GPT-OSS-120B、Gemini 3 Flash Preview、Kimi K2 Thinking 四个模型上系统验证了这一现象,推理 token 数最多缩减 50%,而"Wait"、"But"、"Alternatively"等自我验证标志词的出现频率也大幅降低。这不是一篇提出新方法的论文,而是一个针对推理模型鲁棒性的实验观测报告——它的价值在于揭示了一个工程实践中可能被反复踩到的坑。
📖 问题:推理模型真的在"认真思考"吗?
过去两年,大模型的推理能力突飞猛进。从 OpenAI o1 到 DeepSeek-R1,通过强化学习训练出来的"思考模式"让模型能在回答前产生大量推理 token,进行自我验证、回溯和纠错。这种 test-time scaling 策略在竞赛数学和编程任务上效果惊人。
与此同时,模型的上下文窗口也在疯狂扩展——从几千 token 到几十万、上百万。更长的上下文意味着更复杂的 Agent 工作流、多轮对话历史、以及不可避免的无关信息积累。
这就引出了一个关键问题:当推理模型面对的不再是一个"干净"的单独问题,而是被包裹在大量无关上下文中时,它还会像独立解题那样认真思考吗?
已有研究表明长上下文会降低模型的检索能力、多跳推理能力,甚至单纯的输入长度就能拖垮性能。但之前的工作关注的是"最终答案对不对",这篇论文的切入点不同——它关注的是推理过程本身是否发生了变化。
🧪 实验设计:三种"干扰"场景
论文设计了四种对照条件,用同一批数学题测试模型在不同上下文环境下的表现:
| 条件 | 设置描述 | 核心变量 |
|---|---|---|
| Baseline | 标准单轮对话,直接给数学题 | 无干扰(对照组) |
| Subtask | 一条消息里同时给两道独立数学题 | 任务共存 |
| Long input | 数学题前插入 64000 token 莎士比亚戏剧文本 | 无关前缀 |
| Multi-turn | 多轮对话,前几轮是其他数学题,评估最后一轮 | 对话历史 |
这里有个精巧的设计:Long input 场景中插入的是莎士比亚戏剧——和数学完全无关,模型不可能从中获得任何有用信息。这就排除了"模型被干扰信息误导"的解释,纯粹测试上下文长度和存在对推理行为的影响。
评测基准:主实验用 IMOAnswerBench(国际数学奥林匹克级别的难题),辅助实验用 MATH500。用 Gemini 3 Pro Preview 做自动评判。
推理模型覆盖:Qwen3.5-27B、GPT-OSS-120B、Gemini 3 Flash Preview、Kimi K2 Thinking,四个不同来源的推理模型,thinking budget 统一设为 80000 token。
📊 主实验结果:推理链普遍被"压缩"
IMOAnswerBench 主表
| 模型 | Baseline 准确率 | Baseline token数 | Subtask 准确率 | Subtask token数 | Long input 准确率 | Long input token数 | Multi-turn 准确率 | Multi-turn token数 |
|---|---|---|---|---|---|---|---|---|
| Qwen3.5-27B | 74.5 | 28,771 | 62.4 | 20,165 | 67.8 | 16,415 | 67.0 | 17,404 |
| GPT-OSS-120B | 73.8 | 24,180 | 64.0 | 17,408 | 64.0 | 11,876 | 69.3 | 19,831 |
| Gemini 3 Flash | 82.8 | 23,090 | 67.0 | 13,653 | 80.3 | 19,879 | 82.5 | 21,693 |
| Kimi K2 Thinking | 74.8 | 29,615 | 65.0 | 19,630 | 70.8 | 23,380 | 72.8 | 30,421 |
几个关键发现:
1. 推理 token 数大幅下降——所有模型都中招。 GPT-OSS-120B 在 Long input 场景下推理 token 数从 24180 降到 11876,缩减了 51%。Qwen3.5-27B 的 Long input 推理 token 从 28771 降到 16415,缩减了 43%。
2. 准确率下降幅度因模型而异。 Gemini 3 Flash 在 Long input 下几乎没有掉点(82.8→80.3),但 Subtask 场景掉了 15.8 个点。Qwen3.5-27B 在所有非 Baseline 场景都有 7-12 个点的下降。
3. Subtask 场景的双重伤害最严重。 当模型被要求同时解两道题时,不仅推理变短,而且第二道题的准确率普遍低于第一道——Qwen3.5-27B 的第二题只有 58.0%,比 Baseline 掉了 16.5 个点。
下面这张散点图直观展示了 Qwen3.5-27B 在 IMOAnswerBench 上每道题的推理 token 数对比(X轴 Baseline,Y轴 Long input),绝大多数点都落在 y=x 对角线下方:
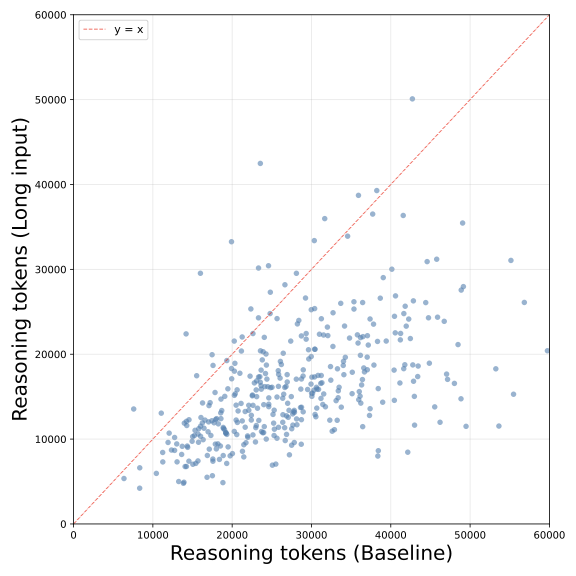
Qwen3.5-27B 在 IMOAnswerBench 上每道题的推理token数:X轴为 Baseline,Y轴为 Long input。点几乎全部在对角线下方,说明添加无关上下文后推理链系统性缩短。
GPT-OSS-120B 的散点分布更加极端,Long input 下的压缩更明显:
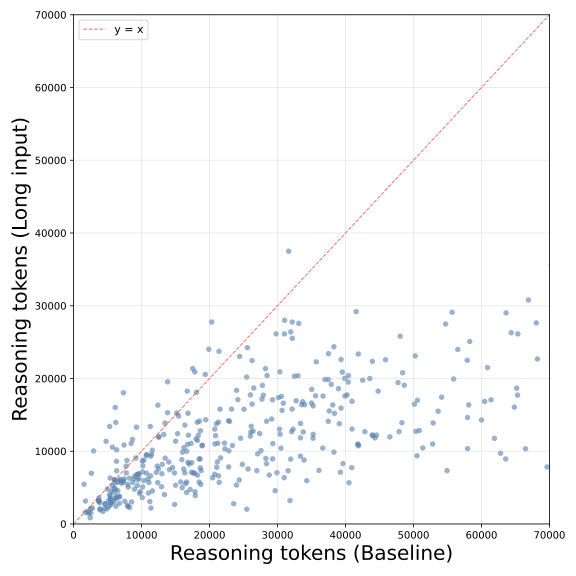
GPT-OSS-120B 的推理token散点分布:Long input 场景下的缩减比 Qwen 更为剧烈。
🔬 深入分析:推理是怎么被"缩短"的?
推理变短了,但变短的方式是什么?是模型更快地找到答案了,还是找到答案之后不再"反复检查"了?
第一个答案出现的位置几乎不变
论文用 Qwen3-32B 在 MATH500 上做了细粒度分析。尽管 Baseline 的平均推理长度(3824 token)远超 Long input(2741 token),但模型首次给出候选答案的位置几乎相同——Baseline 平均 925 token,Long input 平均 939 token,中位数都在 400 token 附近。
这说明推理链变短不是因为模型更快地到达了答案,而是因为模型在找到答案后省略了后续的自我验证步骤。
状态转移分析:自我检查被跳过
论文采用了 Venhoff et al. (2025) 的分析框架,把推理链中的每一句话分类为:问题设置、计划生成、事实检索、主动计算、结果整合、不确定性管理、最终回答。然后比较两种条件下这些类别之间的转移概率差异。
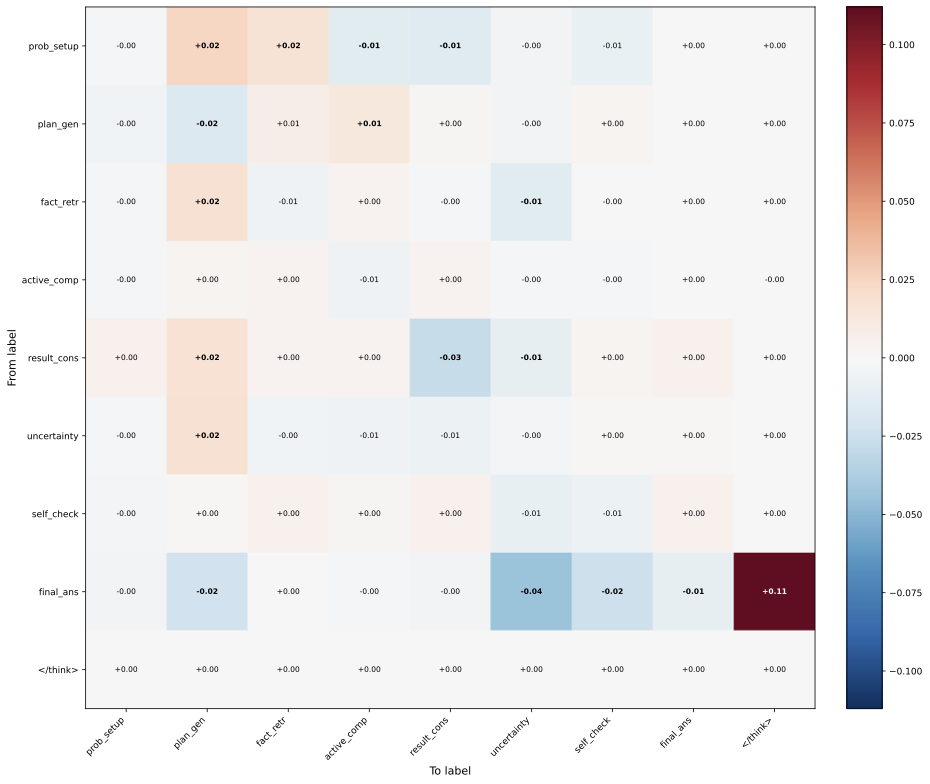
推理步骤之间的转移概率差异热力图(Long input - Baseline),Qwen3-32B,MATH500。红色表示 Long input 相比 Baseline 转移概率更高,蓝色表示更低。
这张热力图中最显眼的数值出现在右下角:从"最终回答"到"结束思考"的转移概率,Long input 比 Baseline 高了 0.11(即 68% vs 57%)。换句话说,在 Baseline 条件下,模型给出最终答案后有 43% 的概率会继续检查;而在 Long input 下,这个概率降到了 32%。模型更倾向于"给完答案就收工"。
与此同时,从"最终回答"到"不确定性管理"和"自我检查"的转移概率在 Long input 下分别降低了 0.04 和 0.02——模型不再反问自己"等等,这样对吗?"
重采样实验:因果验证
为了排除"推理链内容本身导致提前结束"的可能性,论文做了一个精巧的重采样实验。取 Long input 条件下产生的推理链,去掉最后 50 个 token,然后分别在不同的上下文条件下让模型继续生成。结果:
| 标志 | Baseline(0 token前缀) | 128 token 前缀 | 16k token 前缀 |
|---|---|---|---|
</think>(结束推理) | 21% | 26% | 46% |
| "Wait" | 11% | 10% | 5% |
| "Alternatively" | 17% | 11% | 5% |
| "But" | 46% | 38% | 20% |
| "Maybe" | 23% | 17% | 9% |
同样的推理前缀,只是更换了上下文条件,模型就从"等等让我再想想"变成了"好了直接结束"。 这是很有说服力的因果证据:上下文条件本身在压制模型的自我验证行为。
📈 上下文长度与推理缩短的剂量效应
推理被压缩不是一个"有或没有"的阈值效应,而是与插入的无关 token 数量呈现近似线性的关系。
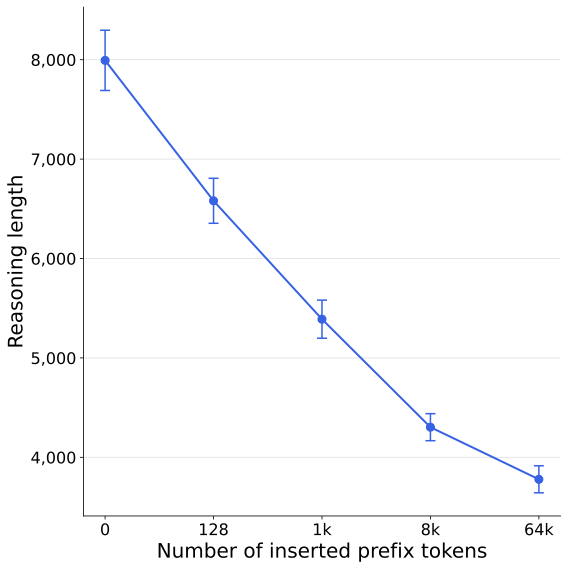
Qwen3.5-27B 在 MATH500 上的平均推理长度随 Long input 前缀token数的变化。仅插入128个无关token就让推理缩短了18%,到64k token时缩短了53%。
这张图揭示了一个工程上很重要的事实:不需要塞几万 token 的垃圾信息,仅仅几百个 token 的无关前缀就足以产生明显影响。 这意味着在实际的 Agent 系统中,系统提示、工具调用结果、历史对话等"正常积累"的上下文,就可能已经在悄悄地缩短模型的推理深度。
🧠 不是思考模式独有的问题,但思考模式更严重
论文还用 Qwen3.5-27B 在 MATH500 上对比了 thinking 和 non-thinking 两种模式的表现。
| 模式 | Baseline token 数 | Long input token 数 | 缩减比例 |
|---|---|---|---|
| Non-thinking(响应长度) | 1,664 | 1,348 | 19% |
| Thinking(推理链长度) | 8,003 | 3,762 | 53% |
两种模式都会受影响,但 thinking 模式的缩减幅度是 non-thinking 的近 3 倍。下面两张对比图很直观:
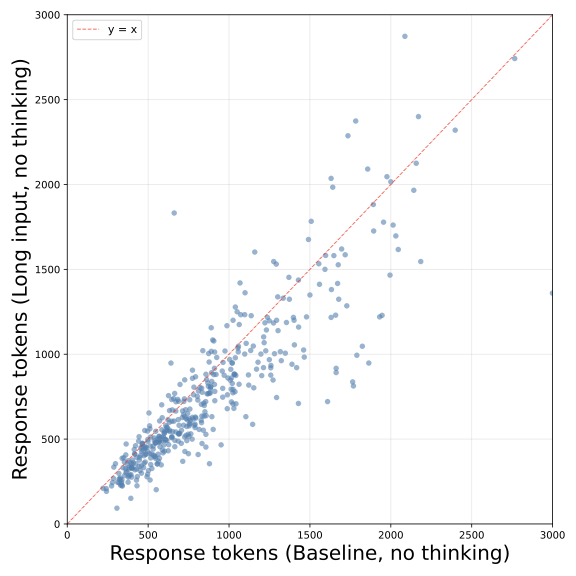
Qwen3.5-27B MATH500 Non-thinking 模式:散点分布更接近对角线,缩减幅度相对温和。
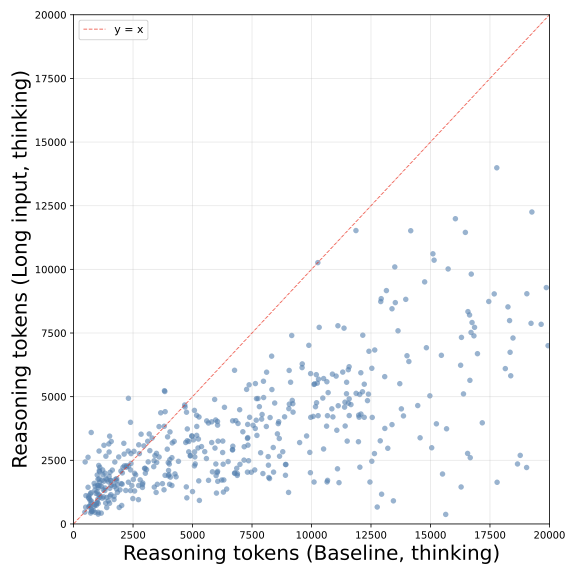
Qwen3.5-27B MATH500 Thinking 模式:散点大面积落在对角线下方,推理被大幅压缩。
这个对比很有意思——思考模式下模型原本会做大量的自我检查和回溯,而这些"可选"的认知行为恰恰是最先被上下文压力裁掉的部分。
🏗️ 后训练阶段的影响
论文还用 OLMo3-7B 的不同后训练检查点做了消融,看推理偏移在哪个训练阶段最为严重:
| 模型 | Baseline 准确率 | Baseline token | Subtask token | Long input token | Multi-turn token |
|---|---|---|---|---|---|
| OLMo3-7B-Instruct | 95.5 | 1,522 | 1,487 | 1,635 | 1,266 |
| OLMo3-7B-Think-SFT | 96.0 | 4,456 | 3,470 | 3,547 | 3,705 |
| OLMo3-7B-Think-DPO | 97.4 | 4,140 | 3,021 | 3,693 | 3,538 |
| OLMo3-7B-Think(最终版) | 96.4 | 5,227 | 3,126 | 3,888 | 3,587 |
这里的 MATH500 问题相对简单(所有版本准确率都 >93%),但推理链长度差异很明显。从 Instruct 到 Think-SFT 到 Think-DPO 到 Think 最终版,推理链越来越长——但非 Baseline 场景下的缩减比例也越来越大。Think 最终版在 Subtask 下的推理 token 从 5227 降到 3126,缩减了 40%。
这暗示了一个不太乐观的可能性:推理能力越强的模型,其推理行为可能越脆弱——因为更长的推理链中有更大比例是"可裁减"的自我验证,而这些恰好是上下文压力首先压缩的部分。
🤔 批判性分析
这篇论文揭示的问题真实吗?
从实验数据来看,推理链缩短的现象是真实且跨模型一致的。四个不同来源的模型(阿里 Qwen、开源 GPT-OSS、Google Gemini、月之暗面 Kimi)都表现出相同趋势,排除了单个模型特异性的解释。重采样实验也提供了初步的因果证据。
局限性在哪?
场景过于合成。 论文的三种干扰条件(莎士比亚前缀、两题并列、多轮对话)虽然清晰可控,但距离真实 Agent 系统的上下文环境还有距离。真实场景中的上下文更复杂:有工具返回结果、有部分相关的历史信息、有系统级指令——这些是否会产生同样的推理偏移,还需要进一步验证。
只覆盖了数学领域。 编程、自然科学、逻辑推理等其他需要深度思考的领域是否有同样的现象?考虑到数学推理的标准化程度较高,结论向其他领域的迁移不能理所当然地假定。
分析深度有限。 论文只对 Qwen3-32B 做了详细的推理链分析。不同模型的推理风格可能差异很大——GPT-OSS-120B 缩减最明显但原因可能和 Qwen 不同,论文没有深入讨论。
没有提出解决方案。 这是一篇纯观测性的工作,不包含任何缓解策略。论文在 Discussion 中提到了递归自调用、上下文压缩等方向,但没有实验验证。
和已有工作的关系
Du et al. (2025) 已经证明单纯的输入长度就能降低 LLM 性能,但那项工作关注的是最终准确率。本文的增量贡献在于揭示了推理过程的结构性变化——不只是"答错了",而是"思考方式变了"。Su et al. (2025) 关于 overthinking/underthinking 的研究表明模型本就不擅长根据问题难度校准推理深度,而本文发现上下文条件还会进一步削弱这种校准能力。
💡 对工程实践的启示
虽然这是一篇研究论文而非工程指南,但它对 LLM-based Agent 系统设计有直接的警示意义:
1. Agent 的上下文管理至关重要。 如果你的 Agent 在多步任务中积累了大量历史上下文,模型在后续子任务上的推理深度可能已经悄悄下降了。这不是"能力不够",而是上下文环境改变了模型的推理行为。
2. 子任务隔离可能是必要的。 论文数据显示,把两道独立题合并到一个 prompt 会显著降低表现。对于 Agent 中的可分解子任务,采用独立上下文调用(或递归自调用)可能比在一个长 session 中连续处理更可靠。
3. 推理 token 数不是万能指标,但它的突然缩短值得警觉。 如果你在监控 Agent 系统的推理行为,发现随着对话进行推理 token 数持续下降,这可能不是模型"更熟练"了,而是模型在偷工减料。
📝 总结
这篇论文的核心发现可以用一句话概括:推理模型的"深度思考"能力比我们想象的更脆弱——上下文中的无关信息就能让模型从"反复检查"切换到"一锤定音",即使模型并没有被这些信息真正干扰。
这不是一个需要"修复"的 bug,更像是当前 test-time scaling 范式下推理行为的一个结构性特征。它提醒我们:在评价推理模型的能力时,不能只看单独问题上的峰值表现,还要考察在真实使用条件下——多轮对话、长上下文、复合任务——推理质量能否保持稳定。
对于正在构建 Agent 系统的工程师来说,这项研究至少值得一个 action item:审视你的 Agent 在执行多步任务时,后续步骤的推理是否被前面积累的上下文悄悄"稀释"了。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新AI前沿,关注公众号:机器懂语言