30行代码,就是一个完整的AI Agent——Claude Code源码精读(一)
核心摘要
大多数人谈起 Claude Code,想到的是"能写代码的 AI 助手"。但如果你看它的源码,会发现最核心的机制出奇地简单:一个 while True 循环 + 一套工具调度表,不到 30 行 Python,就是一个完整 Agent 的骨架。本文是 Claude Code 源码精读系列的第一篇,从最底层的 Agent Loop 出发,逐步拆解工具系统和任务规划机制,看清这套系统的地基。
🎯 为什么 LLM 自己跑不起来?
做过 API 调用的人都知道:ChatGPT/Claude 默认是"一问一答"。你问它"帮我列出这个目录下所有 Python 文件",它会给你一段 ls 命令,但它自己跑不了。
这就是问题所在:语言模型能推理代码,但碰不到真实世界——不能读文件、跑测试、看报错。
解法也很直接:让外部程序替它跑命令,把结果喂回去,再问它下一步。这个"外部程序"就是 Agent Loop(Agent 循环)。
🔧 第一层:最简 Agent——30行骨架
整个 Agent 的本质,就是下面这张图:
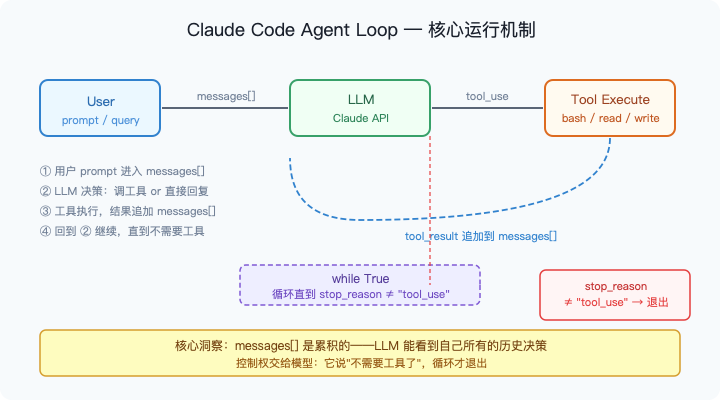
图1:Agent Loop 的完整数据流。User prompt 进入累积的 messages[],LLM 决定是否调工具,工具结果追加回 messages[],循环直到 stop_reason 不等于 "tool_use"。
LLM 调用工具 → 工具执行 → 结果喂回 LLM → LLM 决定下一步,直到不需要调用工具为止。
代码实现:
def agent_loop(query):
messages = [{"role": "user", "content": query}]
while True:
response = client.messages.create(
model=MODEL, system=SYSTEM, messages=messages,
tools=TOOLS, max_tokens=8000,
)
messages.append({"role": "assistant", "content": response.content})
# 模型没有调用工具 → 任务结束,退出
if response.stop_reason != "tool_use":
return
# 执行所有工具调用,收集结果
results = []
for block in response.content:
if block.type == "tool_use":
output = run_bash(block.input["command"])
results.append({
"type": "tool_result",
"tool_use_id": block.id,
"content": output,
})
messages.append({"role": "user", "content": results})
关键只有两点: 1. messages 是累积的——每次对话的历史全在里面,LLM 看得到自己之前的决策 2. 退出条件只有一个:stop_reason != "tool_use"——模型主动"交卷"
这就是所有后续机制的基础。 不管是多 Agent 协作、上下文压缩,还是任务系统,底下都是这个不变的循环。
🔧 第二层:工具系统——加工具不改循环
只有 bash 工具时,所有操作都走 shell。cat 截断不可预测,sed 遇到特殊字符就崩,更重要的是——bash 是无边界的,没有路径限制。
Claude Code 的解法是引入专用工具,但关键洞察是:加工具不需要改循环。
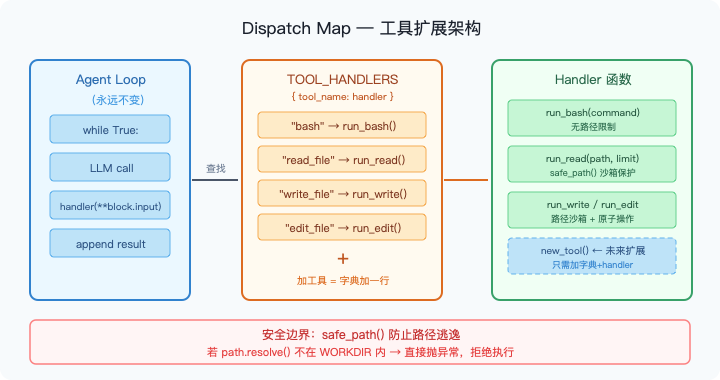
图2:工具调度架构。Agent Loop 永远不变;新工具只需在 TOOL_HANDLERS 字典加一行 + 写一个 handler 函数,Handler 内部通过 safe_path() 保证路径安全。
dispatch map:一个字典替代所有 if/else
TOOL_HANDLERS = {
"bash": lambda **kw: run_bash(kw["command"]),
"read_file": lambda **kw: run_read(kw["path"], kw.get("limit")),
"write_file": lambda **kw: run_write(kw["path"], kw["content"]),
"edit_file": lambda **kw: run_edit(kw["path"], kw["old_text"], kw["new_text"]),
}
循环中的分发只有三行:
handler = TOOL_HANDLERS.get(block.name)
output = handler(**block.input) if handler else f"Unknown tool: {block.name}"
加一个新工具 = 在字典里加一行 + 写一个 handler 函数。循环永远不变。
路径沙箱:工具层面的安全边界
def safe_path(p: str) -> Path:
path = (WORKDIR / p).resolve()
if not path.is_relative_to(WORKDIR):
raise ValueError(f"Path escapes workspace: {p}")
return path
把安全逻辑封装在工具层面,而不是依赖 bash 命令的行为。这是 Claude Code 工程哲学的体现:每一层只负责自己的边界。
| 组件 | 初始版本 | 引入工具系统后 |
|---|---|---|
| 工具数 | 1(仅 bash) | 4(bash/read/write/edit) |
| 分发方式 | 硬编码 | dispatch map 字典 |
| 路径安全 | 无 | safe_path() 沙箱 |
| Agent loop | — | 不变 |
🧠 第三层:TodoWrite——让模型不偏航
为什么模型会"跑偏"?
做一个 10 步重构任务,很多时候 Agent 完成 1~3 步之后就开始即兴发挥。原因不是模型笨,是上下文被工具结果淹没了。
每次工具调用的输出都会追加到 messages 里。10 个文件读取 + 10 次命令 = 20 条 tool_result,轻松吃掉几万 token。System prompt 的影响力就被稀释了——模型还在处理任务,只是忘了任务的全貌。
解法:给模型一个一直盯着的"便条纸"
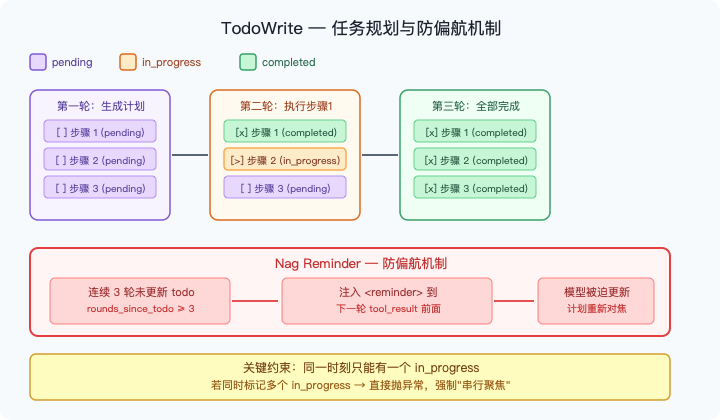
图3:TodoWrite 的完整机制。任务状态从 pending → in_progress → completed 依次流转;若连续 3 轮不更新 todo,系统自动注入 <reminder> 制造问责压力;关键约束:同一时刻只能有一个 in_progress。
TodoWrite 的核心是 TodoManager,维护一个带状态的清单,并通过两个机制确保模型一直盯着它:
机制一:同一时间只能有一个 in_progress
def update(self, items: list) -> str:
in_progress_count = 0
for item in items:
if item.get("status") == "in_progress":
in_progress_count += 1
if in_progress_count > 1:
raise ValueError("Only one task can be in_progress")
self.items = validated
return self.render()
这个约束强制模型"聚焦"——同一时刻只能宣称自己在做一件事。
机制二:Nag Reminder——追着模型问
if rounds_since_todo >= 3 and messages:
last["content"].insert(0, {
"type": "text",
"text": "<reminder>Update your todos.</reminder>",
})
模型连续 3 轮不更新 todo,系统就把提醒注入到下一轮 tool_result 前面。不是惩罚,是"问责压力"——你不更新计划,就会被追着问。
为什么插在 tool_result 前面而不是单独发一条?因为模型在看到最新工具输出的同时也看到了提醒,两者被当成"同一时刻的信息"处理,不会被后面的输出冲淡。
效果:一个"自我监督"的规划机制,不需要外部人类干预,仅靠框架层的规则维持任务进度。
📊 三层基础机制总览
把这三层机制的演进放在一起看:
基础版:while True + bash
↓
引入工具系统:while True + dispatch map + 4 tools + safe_path
↓
引入任务规划:while True + dispatch map + 5 tools + TodoManager + nag reminder
这三层加起来,已经是一个可以完成多步代码任务的基础 Agent。后面所有机制——Subagent、上下文压缩、多 Agent 团队——都是在这个基础上叠加的,循环本身始终不变。
💡 几个反直觉的设计选择
1. 为什么用累积消息而不是每次清零?
模型需要看到自己的历史决策,才能做出一致的下一步。清零意味着"失忆"——之前读了什么文件、改了什么,全忘。
2. 为什么退出条件是 stop_reason != "tool_use" 而不是其他?
这把控制权完全交给了模型——模型说"我不需要再调工具了",循环才结束。不设轮次限制,只看模型的主动表态。
3. 为什么"只能一个 in_progress"如此有效?
多任务并行看似高效,实际上会让模型把注意力分散到多件事上,最终每件事都做不彻底。串行聚焦的完成率反而更高。
🔗 下一篇预告
这一层解决了"单个 Agent 怎么跑"的问题。但当任务越来越大,上下文窗口就成了瓶颈——读 30 个文件、跑 20 条命令,轻松突破 100k token。
下一篇讲 Claude Code 的三个关键进阶机制:
- Subagent:怎么用独立上下文执行子任务,让父 Agent 保持干净
- Skill 系统:按需加载领域知识,不塞满 system prompt
- 三层上下文压缩:micro_compact + auto_compact + reactive compact,实现"无限会话"
觉得有启发的话,欢迎点赞、在看、转发。跟进最新 AI 前沿,关注公众号:机器懂语言