从零搭一个 AI Agent 框架,到底需要理解什么?
Agent = Reasoning + Acting。一篇从 ReAct 理论到 279 行代码实现的完整拆解——三种思维模式、六大框架选型、上下文工程的核心地位,以及一个能跑 Shell、读写文件、执行 Python 的极简智能体。
🎯 为什么要读这篇
年初爆火的 OpenClaw 给 AI Agent 带来了全新的想象空间。如果说 2025 是 AI Agent 元年,2026 大概率是商用化的开端。但"商用化"三个字说起来轻巧,前提是各行各业能把 Agent 落地到实际业务场景里。
作为工程师,你大概率会面临一个具体问题:怎么选框架?怎么搭架子?Agent 的核心到底是什么?
最近读到一篇实战向的技术长文,作者从理论到实践把这件事讲得很透。理论部分梳理了 Agent 的三大思维模式(ReAct、Plan-and-Execute、Reflection)和六大主流框架的选型逻辑;实践部分直接上手,用 279 行 Python 写了一个能调 Shell、读写文件、跑 Python 代码的极简 Agent。
这篇解读不做逐段翻译,而是结合原文观点和我自己的理解,把关键信息拆开重组。你正在纠结框架选型、想理解 Agent 核心机制、或者打算自己造轮子——应该都能找到想要的东西。
📖 Agent 的三种「思考方式」
在动手写代码之前,得先搞清楚一个根本问题:Agent 是怎么"想"的?
原文梳理了三种核心模式,每种解决不同层面的问题。
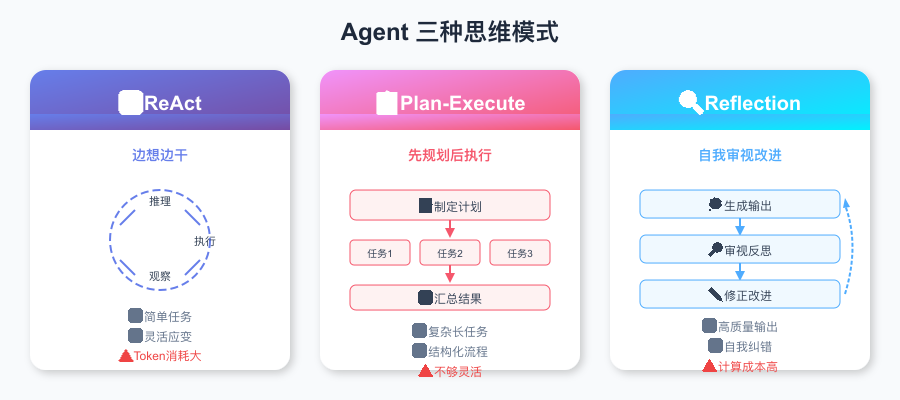
图:ReAct 边想边干、Plan-Execute 先规划后执行、Reflection 自我审视改进——三种模式可以组合使用
ReAct:边想边干
ReAct(Reasoning + Acting)是当前 AI Agent 理论中最具基础性和代表性的模式。它由 Yao 等人在 2022 年的论文《ReAct: Synergizing Reasoning and Acting in Language Models》中提出,核心思想是将推理和行动结合起来。
原文对此的描述非常精练:CoT(Chain of Thought)提升了 LLM 的推理能力,但缺点在于缺少与外部世界的交互,从而缺少外部反馈来拓展知识空间。ReAct 弥补了这一缺陷。
ReAct 智能体的运作基于一个不断迭代的循环过程:
推理(Reasoning)→ 依赖LLM,分析当前状态,决定下一步行动(核心是CoT)
↓
执行(Acting)→ 根据推理结果执行具体操作(工具调用、Shell命令、代码执行等)
↓
观察(Observation)→ 观察行动结果,反馈给下一轮思考;或判断为最终答案,整理输出
↓
[循环继续]
用一个具体例子来感受:
Thought → "用户要查深圳天气,我需要调用天气API"
Action → 调用天气API(city="深圳")
Observe → "深圳今天 28°C,多云"
Thought → "拿到结果了,整理回复"
Action → 返回最终答案
为什么这个模式有效?因为它模拟了人类解决问题的自然过程——走一步看一步,根据反馈不断调整,而不是一口气想出完美方案闷头执行。
但 ReAct 也有硬伤。每一轮循环都往上下文追加 Thought + Action + Observation,Token 消耗线性增长。一旦早期某步拿到了错误信息,后面的推理会一路歪下去——它没有回溯机制。
Plan-and-Execute:先画蓝图再施工
2023 年 5 月,Langchain 团队基于 Lei Wang 等发表的《Plan-and-Solve Prompting》论文和开源的 BabyAGI Agent 项目,提出了 Plan-and-Execute 模式。
跟 ReAct 的「边走边看」不同,这个模式强调先制定多步计划,再逐步执行,属于结构化工作流程(Planning → Task1 → Task2 → Task3 → Summary)。
打个比方:ReAct 像经验丰富的老师傅,遇到问题随机应变;Plan-and-Execute 更像项目经理,先写好 PRD 再分配任务。
它比较适合复杂且任务依赖关系明确的长期任务。缺点是倾向于 workflow 模式,缺乏动态调整能力——计划一旦制定,中途要改的成本很高。
Reflection:自己给自己做 Code Review
Reflection 模式最早由 Noah Shinn、Shunyu Yao 等在《Reflexion: Language Agents with Verbal Reinforcement Learning》论文中系统性地提出。核心思想是通过语言反馈(而非权重更新)来强化 Agent:Agent 对任务反馈信号进行口头反思,在记忆缓冲区中维护反思文本,以在后续试验中做出更好的决策。
另外两篇里程碑论文也值得一提:
- Self-Refine(Aman Madaan 等):受人类改进文本方式的启发,先让 LLM 输出,再根据输出提供反馈,不断迭代。在所有评估任务中,性能平均提升约 20%。
- CRITIC(清华大学与微软联合发布):结合外部工具(搜索引擎、代码执行器)验证输出,再基于验证结果自我修正。
这有点像写完代码后做 code review——退一步审视自己的输出,发现问题就修改再提交。
原文一个很好的总结:这些里程碑论文都是 Reflection 模式的理论基础,当前主流 Agent 框架虽然有各种演绎与变形,也都是在 ReAct 之后发展出来的扩展和补充,Agent 核心实践依旧离不开 ReAct。
三种模式不是互斥关系,更像三种可以组合使用的思维工具。实际生产级 Agent 通常根据任务复杂度动态切换——简单任务走 ReAct,复杂任务先 Plan 再 Execute,高质量输出场景加一轮 Reflection。
🏗️ 六大框架,怎么选?
搞清楚了 Agent 怎么"想",下一步:选哪个框架来实现?
原文对比了当前六大主流框架,结论很直白——没有银弹,按需选择:
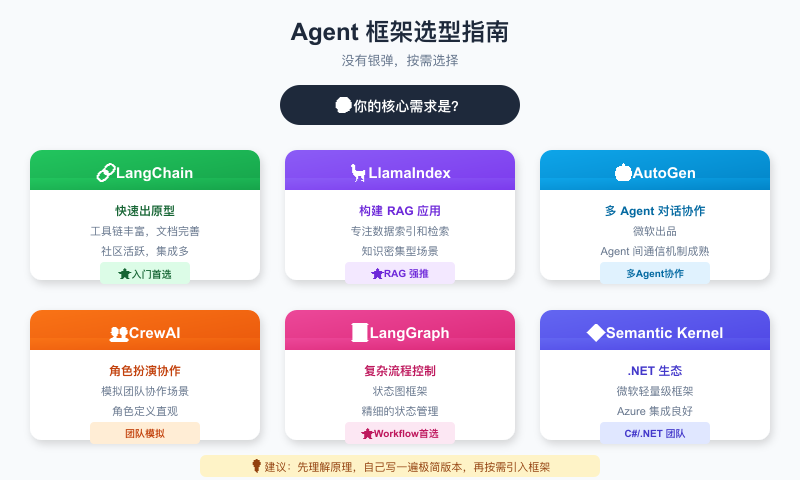
图:六大 Agent 框架各有侧重——快速原型选 LangChain,RAG 应用选 LlamaIndex,复杂流程选 LangGraph
| 框架 | 定位 | 适合谁 | 核心优势 |
|---|---|---|---|
| LangChain | 最成熟和流行的框架之一 | 快速出 Agent 原型 | 工具链丰富,集成多,文档社区完善 |
| LlamaIndex | 专注数据索引和检索 | 构建 RAG 应用 | 文档处理和查询能力高效,知识密集型场景 |
| AutoGen | 微软多 Agent 协作框架 | 多 Agent 对话协作 | Agent 间通信机制成熟 |
| CrewAI | 角色扮演型 Agent 协作 | 模拟团队协作场景 | 角色定义直观,流程编排清晰 |
| LangGraph | LangChain 团队的状态图框架 | 复杂流程控制 | 精细的状态管理,通用性好 |
| Semantic Kernel | 微软轻量级框架 | .NET 生态团队 | Azure 集成良好,插件化设计 |
原文的选择建议写得很实在:
- 快速出原型 → LangChain
- 构建 RAG 应用 → LlamaIndex(强烈建议)
- 多 Agent 协作 → AutoGen 或 CrewAI
- 复杂流程控制 → LangGraph(基于状态管理的 workflow 灵活性高)
- .NET 生态 → Semantic Kernel
原文还提到一个新趋势:随着 Anthropic 的 Claude 等通用 Agent 兴起,一些基于通用 Code Agent SDK 的套壳 Agent 也开始流行,创新之处在于针对各类用户场景提供更好的交互设计与工作流解决方案。
说说我的看法:如果你是从零开始学 Agent,不建议直接上框架。框架做的抽象会遮蔽底层核心逻辑。你用 LangChain 的 AgentExecutor 跑通了 demo,但可能完全不理解 Agent Loop 里发生了什么。一旦遇到工具调用超时、上下文溢出这类 edge case,根本不知道该在哪一层 debug。更好的路径是:先理解原理,自己写一遍极简版本,再按需引入框架。
🧠 上下文工程:Agent 真正的「智能」所在
这部分是原文最有洞见的章节。作者通过一个产品故事引出了 Agent 工程的两大核心共识。
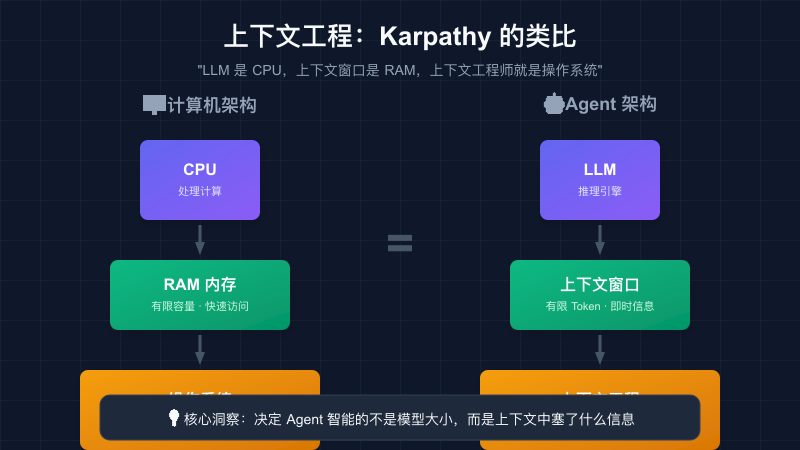
图:Karpathy 的经典类比——LLM 是 CPU,上下文窗口是 RAM,上下文工程师就是操作系统
从 Manus 的故事说起
AI 初创公司 Monica 发布的 Agent C 端产品 Manus 曾经爆火出圈。但原文关注的不是 Manus 的产品交互,而是它的工程选择:
- 当 MCP 风靡一时,Manus 首席科学家 Peak 在社交媒体直接回复:"Actually, Manus doesn't use MCP"
- 4 个月后,Manus 工程博客发文分享为何放弃微调路线,转而选择基于通用大模型深耕上下文工程(Context Engineering)
- 其中一条关键经验教训:使用文件系统作为上下文
- 3 个月后 Anthropic 推出 Claude Skills,"使用文件系统作为上下文"的理念从此深入人心
还有后半句也很关键——"Actually, Manus doesn't use MCP" 后面跟着 "inspired by CodeAct"。CodeAct 来自 UIUC 王星尧博士的论文《Executable Code Actions Elicit Better LLM Agents》,核心观点:通过生成可执行的 Python 代码来统一 Agent 的行动空间——Acting 不仅可以有 Function Call 和 MCP,还可以执行代码完成任务,而且效果更好。
2025 年 11 月,Anthropic 官方博客也更新了一篇《Code execution with MCP》,提出将 MCP 服务器作为代码 API 来提供,Agent 编写代码与 MCP 交互,按需加载,更高效利用上下文。
原文从 Manus 的故事提炼出两大业内共识:
- 使用文件系统作为上下文(如用文件保存 Agent 长期记忆,OpenClaw 的 SOUL.md/TOOLS.md/MEMORY.md 等)
- 编程是解决通用问题的一种普适方法(AI 更擅长使用代码解决问题:问题 → 生成代码 → 执行代码 → 再来 → 直到问题解决)
ReAct 论文的作者 Shunyu Yao 说过一句话与此不谋而合:"人类最重要的 affordance 是手,而 AI 最重要的 affordance 可能是代码。"
Context Engineering 才是核心变量
原文把 Agent 框架在工程上拆解为三大部分:
| 部分 | 本质 | 工程变量大小 |
|---|---|---|
| LLM Call | API 管理——兼容各厂商 API、流式输出等基础能力 | 小(LiteLLM 等已经做得很好) |
| Tools Call | LLM 使用外部工具——Function Call、MCP、Shell/代码执行等 | 中(有业内最佳实践,取决于业务场景) |
| Context Engineering | 上下文工程——提示词、记忆管理、动态 RAG、Skills 等 | 大(Agent 智能的核心所在) |
原文的核心论点:剩下最大的变量是上下文工程,这也是 Agent 框架智能的核心所在。
近日,Shunyu Yao 团队在混元官网发表了一篇名为《从 Context 学习,远比我们想象的要难》的文章,提出:"模型想要迈向高价值应用,核心瓶颈就在于能否用好 Context。"文中指出,在不提供任何 Context 的情况下,最先进的模型仅能解决不到 1% 的任务。
Andrej Karpathy 的类比也非常形象:LLM 是 CPU,上下文窗口是 RAM,上下文工程师就是操作系统。 你的操作系统需要精心管理有限的内存——哪些数据常驻、哪些换出、哪些按需加载。上下文工程做的是完全一样的事,只不过管理的是 Token 窗口里的信息。
简单一句话总结:Agent 应用中上下文工程大有可为(仍有很大优化空间)。
🔧 Agent Loop:引擎怎么转
上下文工程的核心引擎是什么?原文给出了一个清晰的回答:Agent Loop。
Agent Loop 也不神秘,本质是一个 While 循环,每一次迭代是一次 LLM 推理外加工具调用和上下文处理。所有 Agent 行为都在这个 While 循环里面发生,直到任务完成退出。
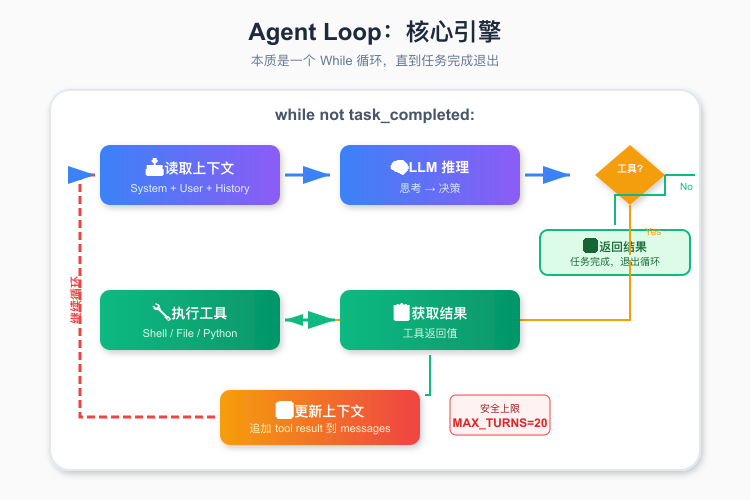
图:Agent Loop 的本质——读取上下文 → LLM 推理 → 执行工具 → 更新上下文 → 循环继续
细分到每一次迭代(Turn):
┌─────────────────────────────────┐
│ Agent Loop │
│ ┌─────────────────────┐ │
│ │ Turn 1 │ │
│ │ LLM Call 推理 #1 │ │
│ │ → 解析LLM响应 │ │
│ │ → 执行工具1 │ │
│ │ → 返回结果,更新上下文│ │
│ └─────────────────────┘ │
│ ↓ │
│ ┌─────────────────────┐ │
│ │ Turn 2 │ │
│ │ LLM Call 推理 #2 │ │
│ │ → 执行工具2 │ │
│ │ → 返回结果,更新上下文│ │
│ └─────────────────────┘ │
│ .... │
└─────────────────────────────────┘
↓
完成(当某次Turn不再执行工具即表示完成)
原文对 Agent Loop 的定位非常精准:Agent Loop 通过在每次迭代中读取、利用和更新上下文来完成任务;上下文工程则是设计如何组织、管理和优化这些上下文信息以提升 Agent 的决策质量和效率。
回到主线:Agent 框架设计的核心就是在 Agent Loop 这个 While 循环中设计如何管理上下文。
💻 279 行代码的极简实现
原文最精彩的部分来了——实践篇。作者围绕"在 Agent Loop 中管理上下文"这个核心论点展开,用 279 行 Python 实现了一个完整的 Agent 框架。
架构总览
先看架构图(原文提供的 ASCII 架构非常清晰):
┌─────────────────────────────────────────────────────────────────────┐
│ User Interface(CLI REPL Layer) │
│ ┌──────────────┐ ┌──────────────┐ ┌──────────────────────────┐ │
│ │ User Input │ │ Exit/ │ │ Message History │ │
│ │ Handler │ │ Clear Cmd │ │ Management │ │
│ └──────┬───────┘ └──────────────┘ └──────────────────────────┘ │
│ │ │
│ ▼ │
│ ┌──────────────────────────────────────────────────────────────┐ │
│ │ Agent Loop Core │ │
│ │ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ │ │
│ │ │ LLM Call │───▶│ Tool Call │───▶│ Tool Exec │ │ │
│ │ │ (DeepSeek) │ │ Parser │ │ Engine │ │ │
│ │ └──────────────┘ └──────────────┘ └──────────────┘ │ │
│ │ │ │ │ │
│ │ │◀───────────────────────────────────────┘ │ │
│ │ │ (Tool Results Feedback) │ │
│ │ ▼ │ │
│ │ ┌──────────────┐ ┌──────────────┐ │ │
│ │ │ Response │───▶│ Context │ │ │
│ │ │ Formatter │ │ Manager │ │ │
│ │ └──────────────┘ └──────────────┘ │ │
│ └──────────────────────────────────────────────────────────────┘ │
│ │ │
│ ▼ │
│ ┌──────────────────────────────────────────────────────────────┐ │
│ │ Tools Registry (TOOLS) │ │
│ │ ┌─────────┐ ┌─────────┐ ┌─────────┐ ┌─────────┐ │ │
│ │ │ shell_ │ │ file_ │ │ file_ │ │ python_ │ │ │
│ │ │ exec │ │ read │ │ write │ │ exec │ │ │
│ │ └─────────┘ └─────────┘ └─────────┘ └─────────┘ │ │
│ └──────────────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────────────┘
三层结构一目了然:顶层是 CLI REPL 用户交互,中层是 Agent Loop Core(LLM 推理 + 工具解析 + 工具执行 + 上下文管理),底层是 Tools Registry。
第一大模块:Agent Loop 与上下文
这是核心中的核心。来看原文的实际代码:
MAX_TURNS = 20
def agent_loop(user_message: str, messages: list, client: OpenAI) -> str:
"""
Agent Loop:while 循环驱动 LLM 推理与工具调用。
流程:
1. 将用户消息追加到 messages
2. 调用 LLM
3. 若 LLM 返回 tool_calls → 逐个执行 → 结果追加到 messages → 继续循环
4. 若 LLM 直接返回文本(无 tool_calls)→ 退出循环,返回文本
5. 安全上限 MAX_TURNS 轮
"""
messages.append({"role": "user", "content": user_message})
tool_schemas = [t["schema"] for t in TOOLS.values()]
for turn in range(1, MAX_TURNS + 1):
# --- LLM Call ---
response = client.chat.completions.create(
model="deepseek-chat",
messages=messages,
tools=tool_schemas,
)
choice = response.choices[0]
assistant_msg = choice.message
# 将 assistant 消息追加到上下文
messages.append(assistant_msg.model_dump())
# --- 终止条件:无 tool_calls ---
if not assistant_msg.tool_calls:
return assistant_msg.content or ""
# --- 执行每个 tool_call ---
for tool_call in assistant_msg.tool_calls:
name = tool_call.function.name
raw_args = tool_call.function.arguments
print(f" [tool] {name}({raw_args})")
try:
args = json.loads(raw_args)
except json.JSONDecodeError:
args = {}
tool_entry = TOOLS.get(name)
if tool_entry is None:
result = f"[error] unknown tool: {name}"
else:
result = tool_entry["function"](**args)
# 将工具结果追加到上下文
messages.append({
"role": "tool",
"tool_call_id": tool_call.id,
"content": result,
})
return "[agent] reached maximum turns, stopping."
几个关键设计点:
- 全局
messages列表就是上下文的载体,累积系统提示词、用户消息、助手响应和工具结果 - 安全上限 20 轮(
MAX_TURNS=20),防止 Agent 进入死循环烧 Token - 终止条件非常优雅:当 LLM 不再返回
tool_calls时,意味着它认为任务已完成,直接返回文本 - 上下文更新规则:
- 初始化:
{"role": "system", "content": system_prompt} - 追加用户消息:
{"role": "user", "content": user_message} - 追加工具结果:
{"role": "tool", "content": result}
代码用的是 DeepSeek(deepseek-chat 模型),走 OpenAI 兼容接口,同步非流式调用。选 DeepSeek 的考量是:模型支持 Tool Calls,且完全兼容 OpenAI SDK。
第二大模块:4 个工具函数
工具集采用极简设计,总共 4 个函数覆盖了 Agent 的基本操作需求:
| 工具 | 功能 | 技术细节 |
|---|---|---|
shell_exec | 执行 Shell 命令 | subprocess.run,30s 超时,捕获 stdout/stderr |
file_read | 读取文件内容 | open() + UTF-8 编码 |
file_write | 写入文件 | 自动创建父目录(os.makedirs) |
python_exec | 执行 Python 代码 | 写入临时 .py 文件,子进程执行,30s 超时,执行后清理 |
工具注册用的是手动维护字典映射:name → {function, OpenAI function schema}。Schema 遵循 OpenAI Function Calling 的标准格式:
{
"type": "function",
"function": {
"name": "shell_exec",
"description": "Execute a shell command and return its output.",
"parameters": {
"type": "object",
"properties": {
"command": {
"type": "string",
"description": "The shell command to execute.",
}
},
"required": ["command"],
},
},
}
为什么只要 4 个工具就够了?这背后有一个很深的洞察。想想看:读文件(感知环境)、写文件(持久化记忆)、跑 Shell(操作系统)、跑 Python(做计算)——有了这四样,Agent 已经可以做几乎任何事了。
原文也提到 OpenClaw 的底层 Agent Core(Pi Agent)的 Tools 层同样只有四个工具方法:读文件(Read)、写文件(Write)、编辑文件(Edit)、命令行(Shell),其他丰富且强大的能力均靠事件机制及 Skills 扩展而来。
这呼应了那个核心观点:编程是 AI 解决问题的普适方法。 与其给 Agent 几十个专用工具,不如给它一个代码执行环境。它能写 Python,就能做几乎任何事。
第三大模块:System Prompt
极简到不能再简:
SYSTEM_PROMPT = """You are a helpful AI assistant with access to the following tools:
1. shell_exec — run shell commands
2. file_read — read file contents
3. file_write — write content to a file
4. python_exec — execute Python code
Think step by step. Use tools when you need to interact with the file system, \
run commands, or execute code. When the task is complete, respond directly \
without calling any tool."""
就干了两件事:明确告知可用工具列表,以及指导 ReAct 思考方式("Think step by step")。
跑起来什么效果?
作者构建了一个 CLI REPL 界面(Python 交互式命令行)作为入口,然后用实际任务验证。
任务一:查看文件
Agent 调用 shell_exec,执行 ls 命令,返回结果。一步搞定。
任务二:代码统计(多步推理)
这个任务就展示了 Agent Loop 的价值——Agent 在循环中持续调用 Tools、写代码、执行代码:
- 调用
shell_exec找到所有源文件 - 调用
shell_exec统计行数 - 调用
python_exec写 Python 代码做 Token 计数 - 汇总结果返回
一个普通 chatbot 只能给你一个命令让你自己跑,而 Agent 能把整个多步流程自动化。
原文感叹道:虽然实现极简,但功能一点不简单——当 Agent 拥有文件读写权限,外加 Shell 工具以及代码生成与执行权限,它在本机上真的可以"为所欲为"。
🤔 我的观点和思考
279 行够不够?
作为 demo 和学习工具,非常出色。把 Agent Loop 的核心逻辑展示得一清二楚,没有多余的抽象层遮挡视线。
但原文自己也坦诚:如果拿去做生产级应用,在程序健壮性、安全性、功能性(如流式输出)以及优雅性(如 Tools 注册)都有很大改进空间。具体缺的东西包括:
- 容错和重试机制:
shell_exec有 30s 超时,但没有重试策略 - 安全沙箱:Shell 和 Python 执行在生产环境需要严格的权限控制,否则 Agent 一个
rm -rf /就结束了 - 流式输出:当前是同步调用,用户得等 Agent 跑完整个循环才能看到结果
- 上下文窗口管理:
messages列表只增不减,跑个 15 轮上下文就接近窗口上限了 - 可观测性:每步做了什么、花了多少 Token、耗时多少,都缺乏记录
但这恰恰是有意的设计选择。原文说得好:为什么需要极简?一方面方便论述清楚 Agent 的关键点;另一方面是现实考量——代码库也将逐渐成为上下文工程的一部分,代码库越简单上下文越清晰(信息噪声越少),Agent 则越智能。
这个观点很有意思。当你的 Agent 框架本身也需要被 Agent 理解时(比如让 AI 帮你维护和改进框架代码),极简就不只是美学偏好,而是实打实的工程优势。
自己造轮子还是用框架?
分两种情况考虑:
学习目的:自己写一遍,哪怕照着原文思路从零实现。你会深刻理解 Agent Loop 的运行机制、上下文管理的挑战、工具调用的细节。这些理解在后续使用任何框架时都是宝贵的底层认知。
做产品:根据需求选框架。简单单 Agent 场景,直接调 Function Calling API 就够了;需要复杂工作流和状态管理的,考虑 LangGraph;多 Agent 协作的,看 AutoGen 或 CrewAI。
不过有一个越来越明显的趋势:框架在变轻,API 在变强。 各大厂商都在把 Agent 能力直接做进模型 API 里(原生 Function Calling、MCP、Code Interpreter 等)。未来可能不需要那么重的框架——一个 while 循环加几行 API 调用就能搞定大部分场景。原文 279 行的极简实现,某种意义上就是这个趋势的预演。
上下文工程才是真正的战场
如果让我从这篇文章中提炼一个最值得关注的观点,那就是原文结尾的总结:
Agent 框架之外,Agent 应用之内,上下文工程是智能的核心(短期/长期记忆、主动/被动记忆、用户 Session 管理、动态 RAG 等等),也是 Agent 商业应用的关键。框架提供基础工具,上下文工程提供环境,搭配商业领域的 Skills,Agent 就能发挥出巨大的潜力。
这意味着几件事:
-
不要盲目追大模型。 一个配了好的上下文管理策略的小模型,很可能吊打一个裸奔的大模型。在不提供 Context 的情况下,连最先进的模型都只能解决不到 1% 的任务——这个数据够震撼了。
-
文件系统是 Agent 的第二大脑。 上下文窗口有限(就像 RAM),文件系统无限(就像硬盘)。OpenClaw 为什么好用?不只是模型能力,而是它会用 SOUL.md/TOOLS.md/MEMORY.md 等文件精确管理 Agent 的记忆和能力。
-
Skill/Plugin 系统的价值被低估了。 与其给 Agent 一个庞大的 System Prompt 描述所有能力,不如用 Skill 系统按需加载——需要数据库时加载数据库 Skill,需要画图时加载绘图 Skill。这本质上就是上下文工程中"按需选择"的实践。
📝 动手路线
如果你想跟着实践一遍,原文的实现路径其实已经给出了一条很好的学习路线。我在此基础上整理了五步:
第一步:理解 Function Calling 不用任何框架,直接用 OpenAI 或 DeepSeek 的 API,写一个能调用工具的 LLM 请求。理解 tools 参数怎么定义、tool_calls 响应怎么解析。
第二步:实现最小 Agent Loop 把 Function Calling 放进一个 while 循环,加上工具执行和结果回传。大概 50 行代码就能跑通一个最小可用的 Agent。
第三步:加工具 从 shell_exec 和 file_read 开始,逐步加 file_write、python_exec。有了这四个,Agent 的能力空间就打开了。
第四步:优化上下文 System Prompt 怎么写更好?对话太长怎么压缩?工具结果太大怎么截断?这一步开始触及 Agent 真正的难点。
第五步:引入框架(可选) 如果需求超出极简实现的能力范围(多 Agent 协作、复杂状态流转),这时再引入 LangGraph、AutoGen 等框架。因为你已经理解了底层原理,使用框架时会事半功倍。
💡 几个关键 Takeaway
- Agent = While 循环 + LLM + 工具。 别被复杂框架吓到,核心就是这个结构。
- ReAct 是主流但不是唯一。 简单任务走 ReAct,复杂任务先 Plan 再 Execute,高质量输出加 Reflection。
- 上下文工程 >> 提示词工程。 决定 Agent 表现的不是你怎么措辞,而是你往上下文窗口塞了什么信息。
- 编程是 Agent 的万能工具。 给 Agent 一个代码执行环境,它能解决的问题比 100 个专用工具还多。
- 文件系统是 Agent 的外挂记忆。 上下文窗口有限(RAM),文件系统无限(硬盘)。善用它。
- 先理解原理再选框架。 279 行代码就能跑通一个 Agent,别急着上重型框架。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新AI前沿,关注我的微信公众号:机器懂语言