不需要SFT,仅靠上下文强化学习就能教会LLM使用工具
论文标题:In-Context Reinforcement Learning for Tool Use in Large Language Models
作者:Yaoqi Ye, Yiran Zhao(共同一作), Keyu Duan, Zeyu Zheng, Kenji Kawaguchi, Cihang Xie, Michael Qizhe Shieh
机构:新加坡国立大学(NUS)、Salesforce AI Research、UC Berkeley、UC Santa Cruz
论文链接:https://arxiv.org/abs/2603.08068
代码:https://github.com/applese233/ICRL
投稿会议:ICML 2026
一、一句话总结
ICRL(In-Context Reinforcement Learning)提出了一种纯RL框架,通过在强化学习的rollout阶段嵌入few-shot示例,并逐步减少示例数量(3→2→0),完全取代了传统SFT冷启动阶段,让LLM仅凭上下文学习+奖励信号就能学会正确使用外部工具(搜索引擎、代码执行器等)。在QA基准上,ICRL以平均EM 40.16(3B)和49.12(7B)的成绩大幅超越Search-R1、ZeroSearch、ParallelSearch等SOTA方法。
二、问题背景:为什么教LLM用工具这么难?
2.1 LLM的知识局限性
大语言模型的知识来自预训练数据,本质上是一个静态知识库。当面对时效性问题("2026年诺贝尔奖得主是谁?")、复杂多跳推理("设定两任限制先例的总统什么时候就职?")等问题时,仅靠内部知识是远远不够的。
解决方案很自然:让LLM学会使用外部工具。搜索引擎提供实时知识,Python解释器处理数学计算,专用API完成特定任务。但问题是——如何教会模型使用这些工具?
2.2 现有方案的困境
当前主流的工具学习训练范式主要有两种:
方案一:纯RL训练(如Search-R1)
直接用强化学习从头训练模型使用工具。问题在于: - 模型初始不知道 <search>、<think>、<answer> 这些结构化标签的存在 - 随机探索几乎无法产生有效的工具调用序列 - 奖励信号极度稀疏,学习效率低下
方案二:SFT+RL流水线(如O²-Searcher、ReTool)
先用监督微调(SFT)给模型一个"冷启动"初始化,再用RL进一步优化。问题在于: - SFT需要大量高质量的标注数据 - 标注工具调用的完整轨迹(trajectory)既昂贵又耗时 - SFT阶段的数据分布可能和RL阶段不匹配
这就是一个经典的鸡生蛋问题:不做SFT,模型不知道怎么用工具;做SFT,成本高且可能引入分布偏移。
2.3 ICRL的灵感:上下文学习 + 课程学习
ICRL的核心洞察非常精妙:
既然LLM天生就擅长上下文学习(In-Context Learning),为什么不把few-shot示例直接塞进RL的rollout模板里,让模型在RL训练过程中"照猫画虎"?
这个想法本身并不复杂,但关键在于后半部分:随着训练推进,逐步减少示例数量,最终让模型在零示例条件下独立完成工具调用。这本质上是一种课程学习(Curriculum Learning)策略——从简单到难,从依赖到独立。
三、ICRL方法详解
3.1 整体框架
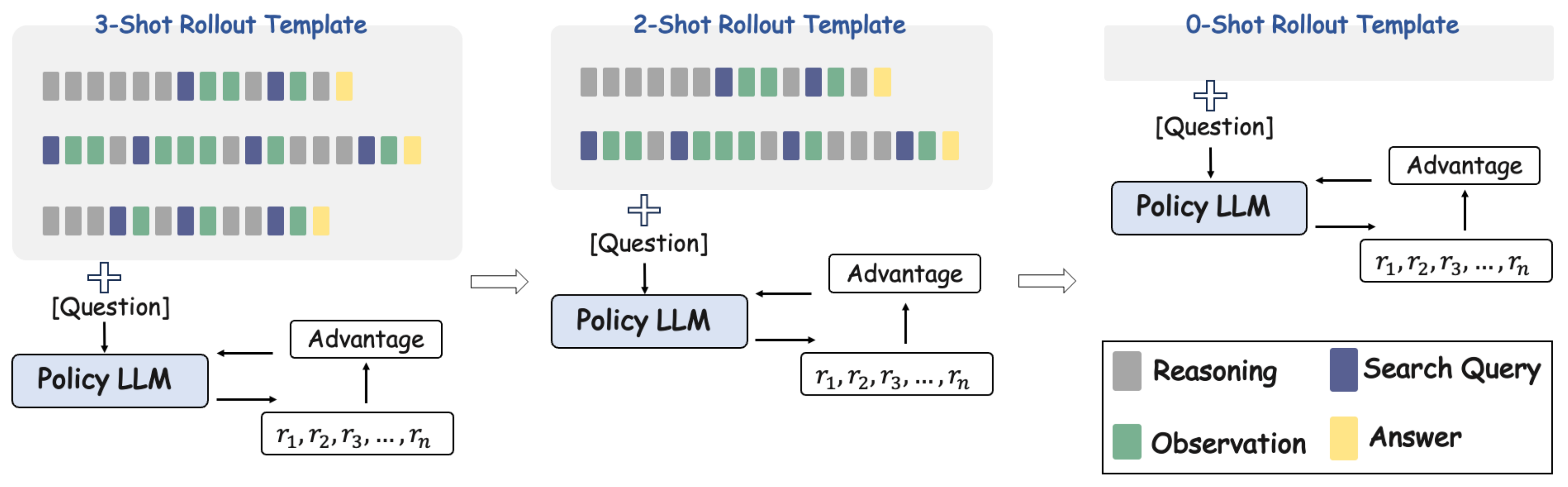
上图展示了ICRL的完整训练工作流。核心思路可以用三句话概括:
- 阶段一(3-shot):在rollout模板中放入3个工具使用的示例,模型在示例引导下学习格式和交互模式
- 阶段二(2-shot):减少到2个示例,模型开始脱离部分依赖,学会泛化
- 阶段三(0-shot):移除所有示例,模型完全自主地进行工具调用和推理
每个阶段都使用GRPO算法进行强化学习训练,阶段之间模型权重顺承传递。
3.2 工具交互的形式化定义
ICRL将LLM的工具使用形式化为一个条件生成过程。给定查询 \(q\) 和外部工具 \(\mathcal{T}\),模型生成响应 \(y = (y_1, y_2, \ldots, y_{|y|})\):
其中 \(\mathcal{H}_t\) 是截至步骤 \(t\) 的所有模型动作和工具返回内容的历史序列。
模型在生成过程中有三种动作选择: - 推理(Think):在 <think>...</think> 标签内进行内部推理 - 搜索(Search):在 <search>...</search> 标签内发起工具查询 - 回答(Answer):在 <answer>...</answer> 标签内给出最终答案
3.3 Few-Shot Rollout模板
ICRL的核心创新在于rollout模板的设计。以3-shot阶段为例,模板结构如下:
Solve the following problem step by step. You must conduct reasoning
inside <think>...</think> every time you get new information. After
reasoning, if you find you lack some knowledge, you can call a search
engine by <search> query </search> and it will return results between
<information>...</information>. You can search as many times as you want.
Finally, provide the answer inside <answer>...</answer>.
Here are some examples:
Example Problem: q_demo_1
Example Solution: <think>...</think> <search>...</search>
<information>...</information> <think>...</think> <answer> a </answer>
(repeated for N examples)
Now solve the following problem:
Actual Problem: [question]
这个模板有几个精妙之处: 1. 系统指令明确告诉模型有哪些工具可用、格式是什么 2. 示例演示展示了完整的"思考→搜索→获取信息→再思考→回答"的交互流程 3. 渐进式减少:训练过程中示例数从3个减到2个最后减到0个
值得注意的是,论文中提到few-shot示例是随机从网上采样了3个问题,然后用GPT-5.2生成的标准格式答案——这意味着示例的质量要求并不高,关键是格式正确。
3.4 GRPO训练算法
ICRL采用GRPO(Group Relative Policy Optimization)作为RL优化算法。GRPO源自DeepSeek-Math,其核心优势是不需要单独训练一个critic/value模型,而是通过组内相对优势来计算策略梯度。
对于每个查询 \(q\),采样 \(N\) 条轨迹 \(\{\tau_1, \ldots, \tau_N\}\),GRPO损失函数为:
其中优势函数 \(A_i\) 通过组内归一化计算:
3.5 Loss Masking策略
这是一个容易被忽略但极其重要的技术细节。在工具增强的RL训练中,rollout序列包含两类token: - 模型生成的token:推理步骤、搜索查询、最终答案 - 工具返回的token:搜索引擎返回的文档内容(<information>...</information>之间的内容)
后者不是模型自己生成的,不应该参与策略梯度的计算。ICRL通过loss masking策略将所有检索内容从损失计算中排除,确保只有模型自身的行为(何时搜索、搜什么、如何推理、如何回答)被优化。
这个设计的合理性在于:如果不做masking,模型可能会学到"生成看起来像搜索结果的文本"这种无用行为,而不是学会正确地发起搜索。
3.6 复合奖励设计
ICRL的奖励函数由两部分组成:
其中 \(\alpha = 0.8\)。
准确率奖励(Accuracy Reward): - 使用Exact Match(EM)评估模型预测答案与标准答案的匹配度 - 完全匹配得1分,否则得0分 - 匹配前会进行标准化处理(小写化、移除冠词、去标点、空白归一化)
格式奖励(Format Reward): $\(\text{reward}_{\text{format}} = 1.0 - \sum_{v \in \mathcal{V}} \text{penalty}(v)\)$
格式违规惩罚表(权重从高到低):
| 违规类型 | 惩罚权重 | 原因 |
|---|---|---|
没有 <answer> 标签 | 0.5 | 必须提供结构化答案 |
<answer> 标签不配对 | 0.2 | XML结构完整性 |
没有 <think> 标签 | 0.15 | 应展示推理过程 |
<think> 标签不配对 | 0.1 | XML结构完整性 |
没有使用 <search> | 0.1 | 应利用可用工具 |
| 答案内容为空 | 0.2 | 答案必须有实质内容 |
这个奖励设计的巧妙之处在于:格式奖励不是简单的0/1,而是细粒度的惩罚机制。即使模型没有给出正确答案,只要格式正确,也能获得部分奖励,这为早期训练提供了更丰富的学习信号。
3.7 算法伪代码
完整的ICRL训练过程如下:
输入: 初始策略 π_θ, 参考模型 π_ref, 工具 T,
初始few-shot prompt P_N, 数据集分区 {D^(N), ..., D^(0)},
奖励函数 r_φ, RL训练步数 T
for k = N down to 0:
// 步骤1: 构造包含k个示例的prompt
P_k ← 从 P_N 中选择 k 个示例
D^(k) ← 当前prompt级别的RL训练子集
for t = 1 to T:
for q in D^(k):
π_θ_old ← π_θ
采样N条轨迹 {τ_1, ..., τ_N} ~ π_θ_old(q, P_k, T)
for each trajectory τ_i:
计算奖励: r_φ(q, τ_i)
计算归一化优势 A_i
计算重要性权重 r_{i,t}(θ)
更新策略: π_θ ← π_θ - ∇_θ L_GRPO
输出: 训练好的模型 π_θ
四、实验结果深度分析
4.1 实验设置
骨干模型:Qwen2.5-3B-Instruct、Qwen2.5-7B-Instruct、Qwen2.5-14B-Instruct,以及Qwen3-8B。全部使用bfloat16精度加载。
训练数据:Natural Questions(NQ)数据集,通过FlashRAG加载。训练中使用Serper API接入Google搜索引擎,每次查询返回top-3文档。
评估基准:5个QA数据集 —— TriviaQA、HotpotQA、2Wiki、Musique、Bamboogle。其中HotpotQA和TriviaQA属于域内通用QA,2Wiki、Musique和Bamboogle属于域外多跳QA。
训练细节: - 学习率:1e-6 - 每个查询采样8条rollout轨迹 - 最大prompt长度:5000 tokens(容纳few-shot示例) - 最大响应长度:2048 tokens(允许最多6轮搜索) - KL惩罚系数:0.001 - 硬件:4×A100 80GB - Batch size:64 - 训练框架:VeRL(Volcano Engine RL) - FSDP + gradient checkpointing
4.2 主实验结果
下表展示了ICRL与各基线方法在5个QA基准上的Exact Match准确率对比:
Qwen2.5-3B模型结果:
| 方法 | TriviaQA | HotpotQA | 2Wiki | Musique | Bamboogle | 平均 |
|---|---|---|---|---|---|---|
| Direct | 28.8 | 14.9 | 24.4 | 2.0 | 2.4 | 14.50 |
| CoT | 3.2 | 2.1 | 2.1 | 0.2 | 0.0 | 1.52 |
| RAG | 54.4 | 25.5 | 22.6 | 4.7 | 8.0 | 23.04 |
| Search-R1 | 54.5 | 32.4 | 31.9 | 10.3 | 26.4 | 31.10 |
| ZeroSearch | 57.4 | 27.4 | 30.0 | 9.8 | 11.1 | 27.14 |
| ICRL | 72.6 | 35.4 | 39.2 | 20.0 | 33.6 | 40.16(+8.94) |
Qwen2.5-7B模型结果:
| 方法 | TriviaQA | HotpotQA | 2Wiki | Musique | Bamboogle | 平均 |
|---|---|---|---|---|---|---|
| Search-R1 | 61.0 | 37.0 | 41.4 | 14.6 | 36.8 | 38.16 |
| ZeroSearch | 65.2 | 34.6 | 35.2 | 18.4 | 27.8 | 36.24 |
| ParallelSearch | 62.8 | 42.9 | 42.4 | 19.7 | 41.1 | 41.78 |
| ICRL | 75.4 | 42.6 | 53.6 | 26.0 | 48.0 | 49.12(+7.34) |
几个关键观察:
- 全面碾压:ICRL在3B和7B上分别以+8.94和+7.34的优势超越所有基线
- 多跳推理优势明显:在2Wiki(+11.2)、Musique(+6.3)、Bamboogle(+6.9)这些多跳数据集上,优势尤为突出
- TriviaQA的巨大提升:3B上从57.4提升到72.6(+15.2),这个提升幅度非常惊人
4.3 与SFT方法的对比
| 模型 | 方法 | 需要SFT? | TriviaQA | HotpotQA | 2Wiki | Musique | Bamboogle | 平均 |
|---|---|---|---|---|---|---|---|---|
| Qwen2.5-3B | O²-Searcher | ✓ | 59.7 | 38.8 | 37.4 | 16.0 | 34.4 | 37.26 |
| Qwen2.5-3B | ICRL | ✗ | 72.6 | 35.4 | 39.2 | 20.0 | 33.6 | 40.16 |
这组对比直接证明了ICRL的核心价值:
- O²-Searcher需要先做冷启动SFT(需要大量标注数据),然后再做RL
- ICRL完全不需要SFT,仅通过在RL rollout中放置few-shot示例就能达到甚至超越SFT+RL的效果
- 平均EM:40.16 vs 37.26,ICRL在没有任何监督数据的情况下反而更强
4.4 14B模型扩展
| 方法 | TriviaQA | HotpotQA | 2Wiki | Musique | Bamboogle | 平均 |
|---|---|---|---|---|---|---|
| Direct | 52.0 | 22.6 | 28.2 | 6.0 | 15.2 | 24.80 |
| CoT | 56.4 | 24.6 | 25.8 | 9.0 | 40.0 | 31.16 |
| ICRL | 75.0 | 43.2 | 61.8 | 25.6 | 53.6 | 51.84 |
14B模型上的结果进一步验证了ICRL的可扩展性。相比CoT,ICRL提升了+20.7个百分点,相比Direct提升了+27.0。特别是2Wiki上的61.8和Bamboogle上的53.6,展现了大模型+ICRL在多跳推理上的强大潜力。
4.5 数学推理泛化
ICRL不仅在搜索工具调用上有效,在代码执行(Python解释器)作为工具的数学推理场景中也表现优异:
| 模型 | 方法 | 需要SFT? | AIME2024 | AIME2025 |
|---|---|---|---|---|
| Qwen3-8B | ReTool | ✓ | 67.0 | 49.3 |
| Qwen3-8B | ICRL | ✗ | 64.1 | 51.7 |
ReTool是目前代码增强长链推理的SOTA方法,采用SFT+RL流水线,需要大量标注数据来教模型写代码和调用Python执行。而ICRL在AIME2025上以51.7超过ReTool的49.3(+2.4),在AIME2024上仅落后2.9。
这说明ICRL的方法论具有很好的跨工具泛化能力——无论是搜索引擎还是代码执行器,只要提供正确格式的few-shot示例,模型就能通过RL学会使用。
五、深度分析与消融实验
5.1 课程设计的消融:三阶段 vs 四阶段
论文对比了两种课程安排:
- 三阶段(3→2→0):论文的默认设置
- 四阶段(3→2→1→0):在2-shot和0-shot之间增加了1-shot阶段
实验结果非常有趣:
| 课程设计 | TriviaQA | HotpotQA | 2Wiki | Musique | Bamboogle |
|---|---|---|---|---|---|
| 3→2→0 | 75.4 | 42.6 | 53.6 | 26.0 | 48.0 |
| 3→2→1→0 | 20.8 | 17.8 | 26.8 | 9.0 | 14.4 |
四阶段方案出现了灾难性的训练崩溃!准确率全面暴跌。
为什么更"渐进"的课程反而更差?论文分析发现: - 四阶段训练的模型倾向于过早停止搜索:23.2%的查询直接给出答案而不进行任何搜索 - 而三阶段模型只有0.09%的查询在第一轮就结束 - 中间的1-shot阶段似乎"鼓励"了模型学到一种错误的策略:既然已经有1个示例了,那做少量搜索就够了
这个发现的深层含义:课程学习中,"跨度"的大小很重要。从2-shot直接跳到0-shot的"大步跳跃"反而能迫使模型学到更robust的工具使用策略,而过于平滑的过渡可能导致模型陷入局部最优。
5.2 训练动态分析
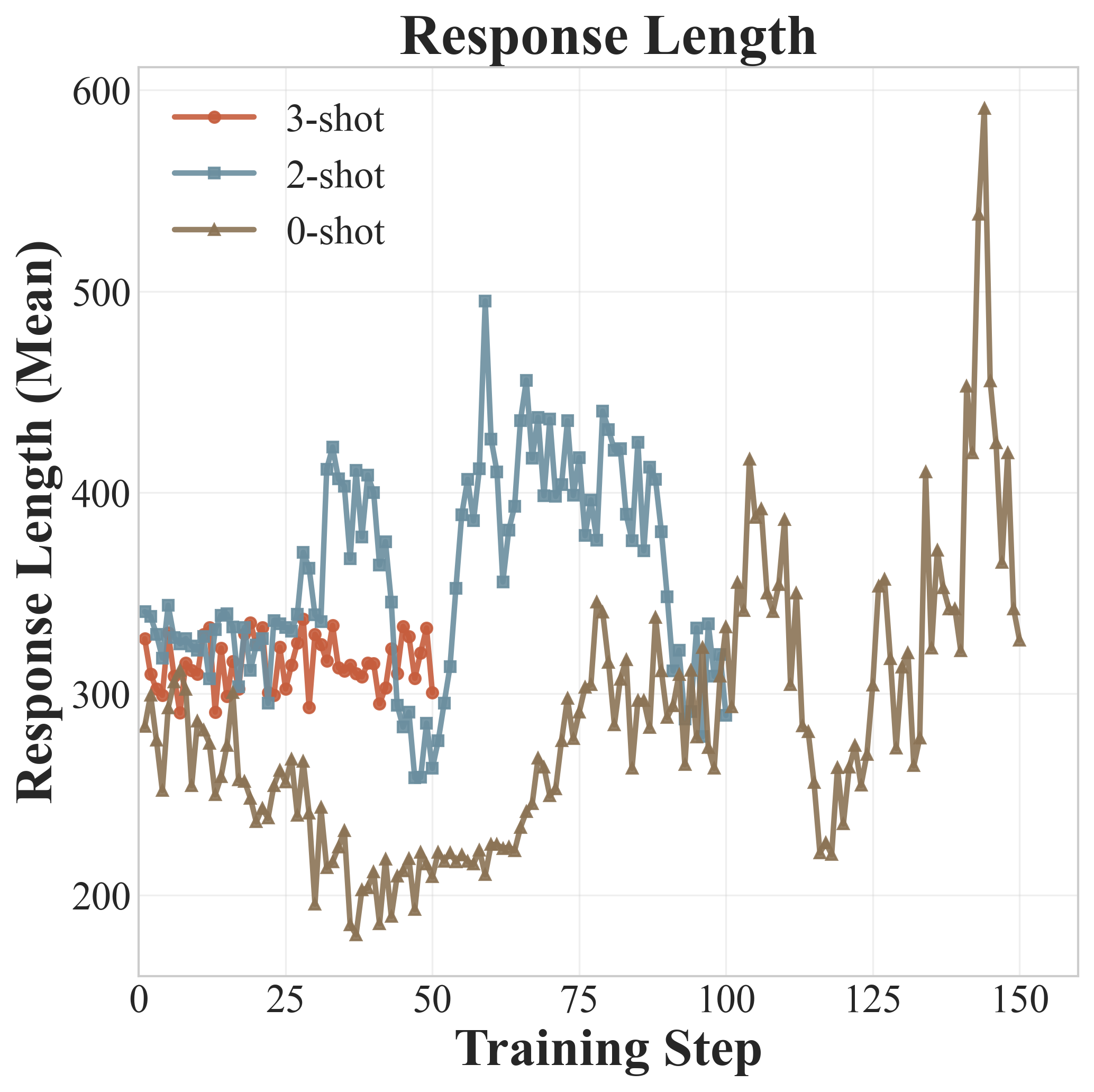
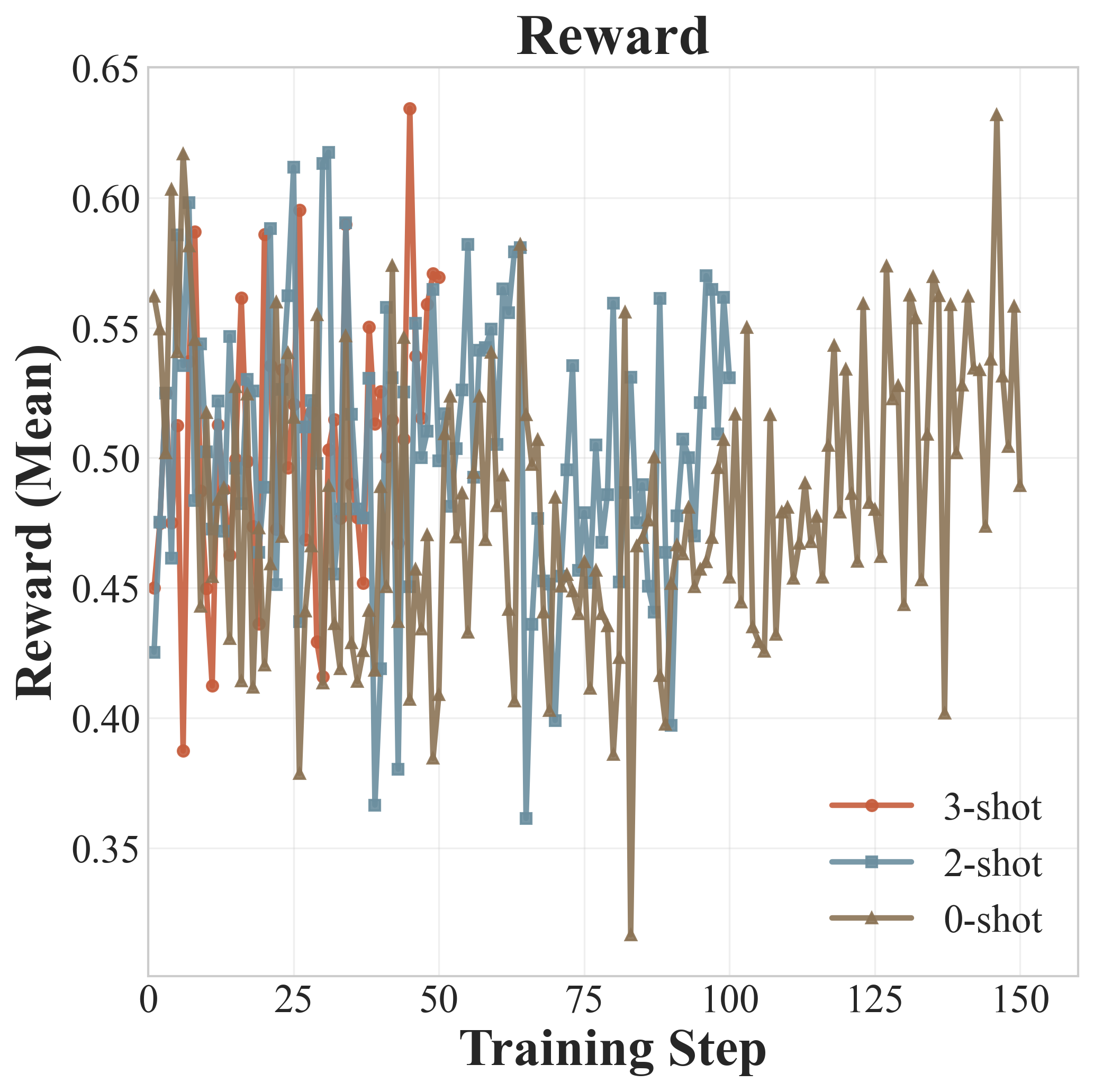
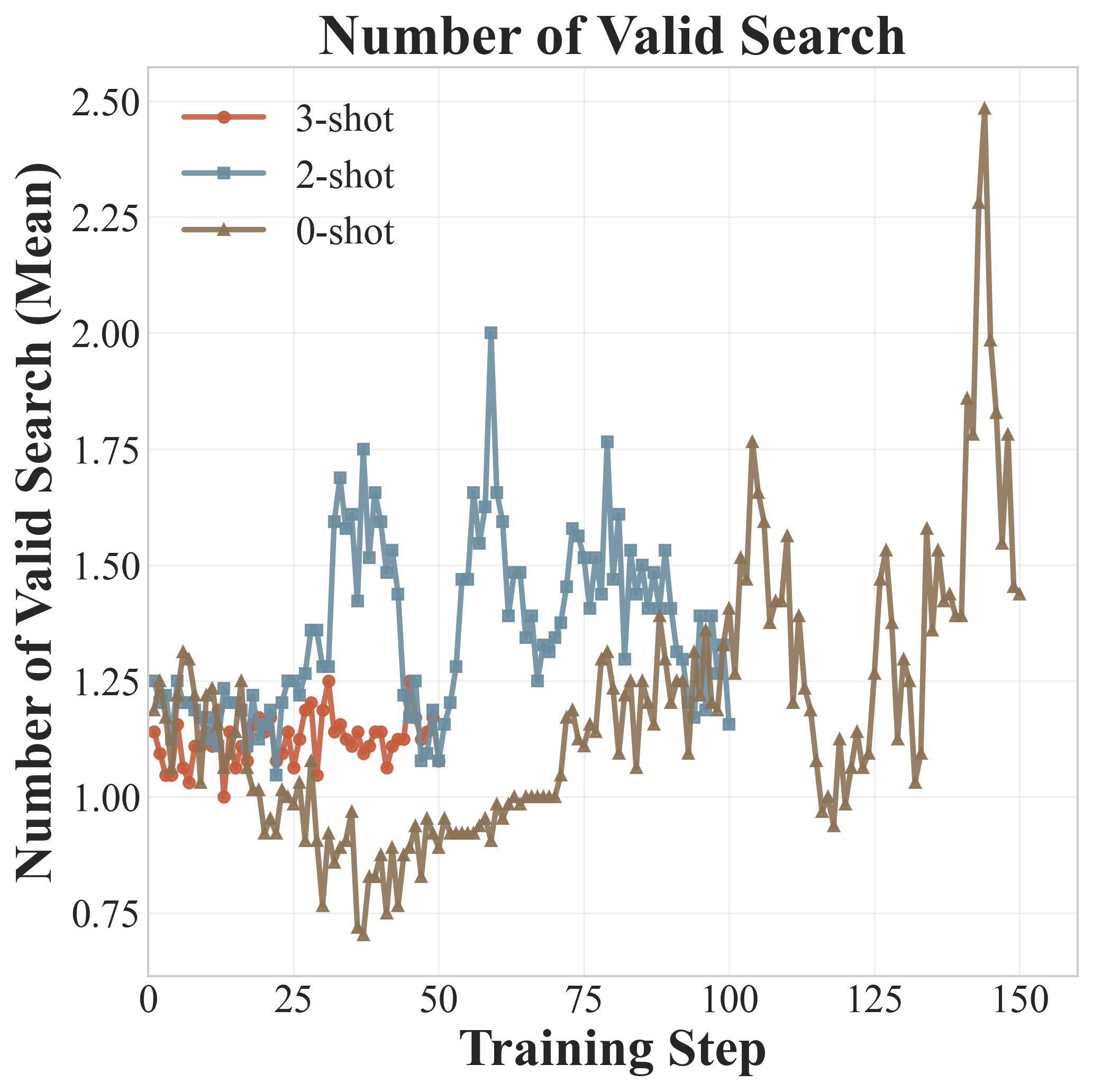
上面三张图展示了Qwen2.5-7B在训练过程中的动态变化:
响应长度(Response Length): - 3-shot和2-shot阶段,响应长度比较稳定 - 进入0-shot阶段后,响应长度先骤降(因为去掉了示例),然后逐步回升 - 回升说明模型正在学习独立生成更长、更结构化的输出
奖励曲线(Reward): - 整个训练过程中奖励相对稳定 - 没有出现剧烈波动或崩溃 - 这得益于复合奖励设计提供的稳定学习信号
有效搜索次数(Valid Search): - 0-shot阶段的有效工具调用次数持续上升 - 这是最令人振奋的信号:即使没有示例,模型也在学会越来越频繁且正确地使用搜索工具 - 说明ICRL成功地将工具使用行为内化到了模型参数中
5.3 一个具体案例
论文展示了ICRL-Qwen2.5-7B处理Bamboogle数据集中一个多跳问题的完整推理过程:
问题:When did the president who set the precedent of a two term limit enter office?(设定两任限制先例的总统什么时候就职?)
模型的推理轨迹:
<think> 我需要知道是哪位总统设定了这个先例,
还需要知道他什么时候就职。先搞清楚是谁。</think>
<search> president who set two term limit precedent </search>
<information>
Doc 1: Twenty-second Amendment... George Washington and Thomas Jefferson...
Doc 2: The decision for George Washington to voluntarily step down...
Doc 3: Washington wrote...
</information>
<think> 看起来是George Washington设定的先例。
现在我需要查他什么时候就职。</think>
<search> when did George Washington enter office as president </search>
<information>
Doc 1: Washington was inaugurated on April 30, 1789...
Doc 2: George Washington was unanimously elected...
Doc 3: George Washington was inaugurated...
</information>
<think> 根据检索到的信息,George Washington于1789年4月30日就职。</think>
<answer> April 30, 1789 </answer>
标准答案:April 30, 1789 ✓
这个案例完美展示了ICRL训练出的模型的能力: 1. 问题分解:先识别"谁设了先例",再查"何时就职" 2. 精准搜索:不是把整个问题扔给搜索引擎,而是有策略地分步搜索 3. 信息整合:从多个文档中提取关键信息 4. 逐步推理:每次获得新信息后都进行思考,最终得出正确答案
六、与相关工作的对比分析
6.1 与Search-R1的对比
Search-R1是最早将GRPO应用于搜索增强LLM训练的工作之一。它直接用0-shot RL训练模型学习搜索。
ICRL vs Search-R1: - Search-R1从0-shot开始,面临严重的冷启动问题 - ICRL通过few-shot rollout解决了冷启动,又通过渐进式减少避免了推理时的依赖 - 结果:ICRL在3B上平均EM超过Search-R1 9个百分点(40.16 vs 31.10)
6.2 与ZeroSearch的对比
ZeroSearch的创新在于用LLM模拟搜索引擎,避免了真实搜索API的高成本。但模拟的搜索结果质量有限。
ICRL vs ZeroSearch: - ICRL使用真实的搜索API(Serper),信息质量更高 - 训练范式完全不同:ZeroSearch关注如何降低搜索成本,ICRL关注如何高效学习工具使用 - 结果:ICRL在7B上以49.12大幅超越ZeroSearch的36.24
6.3 与O²-Searcher的对比
O²-Searcher采用经典的SFT+RL流水线,先用标注数据做SFT冷启动,再用RL优化。
ICRL vs O²-Searcher: - O²-Searcher需要SFT(大量标注数据)→ RL - ICRL仅需RL(3个few-shot示例) - 数据效率:ICRL仅用3个GPT生成的示例就替代了整个SFT阶段 - 结果:ICRL在3B上40.16 vs 37.26,在不需要任何标注数据的情况下胜出
6.4 与ReTool的对比
ReTool是代码工具增强推理的SOTA,采用SFT+RL训练模型写Python代码。
ICRL vs ReTool: - ReTool需要大量标注的代码执行轨迹进行SFT - ICRL仅通过few-shot示例就能学会代码工具的使用 - 在AIME2025上ICRL反超ReTool(51.7 vs 49.3),证明了跨工具泛化能力
七、技术洞察与个人评论
7.1 为什么ICRL有效?
我认为ICRL成功的核心在于巧妙地利用了LLM的两个内在能力:
-
In-Context Learning能力:预训练LLM天然具备从示例中学习的能力。ICRL不是在教模型"记住"工具使用方法,而是在RL训练中"激活"模型已有的ICL能力,让它从示例中"理解"工具使用的模式。
-
RL的自适应探索:纯ICL的问题是推理时永远需要示例,且模型无法超越示例的质量上限。RL让模型在"参照示例"的基础上进行自主探索,发现比示例更优的策略。
两者的结合是1+1>2的效果:ICL提供了良好的初始化和稳定的学习信号,RL则推动模型超越ICL的天花板。
7.2 几个值得思考的问题
1. 三阶段 vs 更多阶段:为什么3→2→0最好?
论文的消融实验已经给出了答案:3→2→1→0会导致训练崩溃。但我认为这背后的机制可能是:
- 从2-shot到0-shot的跳跃足够大,迫使模型必须学到真正robust的工具使用策略
- 而1-shot提供了一种"偷懒"的可能——模型可以只复制那一个示例的模式,而不是学会泛化
- 这和人类学习中的"脱离舒适区"理论很像
2. Few-shot示例的质量影响有多大?
论文中的示例是用GPT-5.2生成的,但没有做示例质量的消融。一个有趣的问题是:如果用更差的模型生成示例,或者用人工编写的简单示例,效果会怎样?我猜测只要格式正确,示例质量的影响可能不大,因为RL阶段本身就会纠正行为。
3. 数据集的选择与泛化
训练只用了NQ数据集,但评估在5个不同的QA基准上。特别是Musique和Bamboogle这样的域外多跳QA上也有很强的表现,说明ICRL学到的不是dataset-specific的技巧,而是通用的工具使用能力。
7.3 局限性
-
计算成本:虽然不需要SFT数据,但ICRL的多阶段RL训练本身需要大量GPU资源(4×A100)。每个查询采样8条轨迹,计算开销不小。
-
搜索API依赖:训练需要真实的搜索API(Serper),这带来了网络依赖和成本。不过这可以通过类似ZeroSearch的方式缓解。
-
阶段数和步数的超参数:何时从3-shot切换到2-shot、何时切换到0-shot,论文似乎是通过经验设定的(约100步/阶段),缺乏自动化的阶段切换策略。
-
仅评估了Qwen系列:虽然Qwen是目前最强的开源模型之一,但对LLaMA、Mistral等其他系列的泛化性尚待验证。
7.4 对未来方向的展望
-
自适应课程调度:能否根据模型的训练状态自动决定何时减少示例?比如当valid search count稳定后自动进入下一阶段。
-
多工具协同:当前ICRL只验证了搜索和代码执行两种工具,能否扩展到更复杂的多工具场景?比如同时使用搜索引擎+计算器+数据库查询。
-
与SFT的互补:ICRL证明了"不需要SFT也能行",但如果在少量SFT后再用ICRL的课程RL,效果是否能更上一层楼?
-
更大规模模型:论文最大测试到14B,在70B+模型上的表现值得期待。
八、总结
ICRL是一篇简洁而有力的工作。它的核心贡献可以归纳为:
- 提出了一种纯RL的工具学习框架,通过在rollout中嵌入few-shot示例完全替代了SFT阶段
- 设计了渐进式课程学习策略(3→2→0),实现了从依赖示例到自主工具使用的平滑过渡
- 在多个QA和数学推理基准上取得了SOTA,证明了方法的有效性和泛化能力
- 显著降低了数据需求:仅需3个GPT生成的few-shot示例,而非成千上万的标注轨迹
这篇论文给出了一个重要的信号:SFT并非工具学习的必要条件。通过巧妙地利用LLM自身的上下文学习能力,配合精心设计的课程策略和奖励函数,纯RL也能让模型学会高质量的工具使用——甚至比SFT+RL更好。
对于工业界来说,这意味着训练工具增强LLM的门槛大大降低:不再需要昂贵的标注数据和复杂的SFT流水线,只需准备好几个格式正确的示例,就能启动RL训练。这无疑是一个令人振奋的进展。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新AI前沿,关注我的微信公众号:机器懂语言。