EMPO²:让LLM智能体学会"记笔记+开卷考"的强化学习框架
论文标题:Exploratory Memory-Augmented LLM Agent via Hybrid On- and Off-Policy Optimization
作者:Zeyuan Liu, Jeonghye Kim, Xufang Luo, Dongsheng Li, Yuqing Yang
机构:Microsoft Research
发表:ICLR 2026
链接:https://arxiv.org/abs/2602.23008
🎯 一句话总结
EMPO² 提出了一种记忆增强的混合策略强化学习框架,让LLM智能体在训练时自己生成"经验笔记"(tips),带着这些笔记去探索更广的空间,再通过on-policy和off-policy双轨训练把探索到的知识蒸馏回模型本身——最终即使不带笔记也能考高分。在ScienceWorld上比GRPO高出128%,18个任务中7个拿到满分。
📖 为什么需要这篇论文?
LLM智能体的"探索困境"
用强化学习训练LLM智能体是当前的热门方向。DeepSeek的GRPO、OpenAI的RLHF,都在推理任务上取得了很好的效果。但这些方法在交互式环境中训练智能体时,会撞上一堵墙:探索不足。
想象一个场景:你让LLM在ScienceWorld(一个文字版科学实验模拟器)里做实验——比如"测量橘子的沸点"。这个任务需要十几步操作:找到橘子、找到温度计、找到加热器、把橘子放进容器、加热、读数……如果模型在前几步就走偏了(比如去了错误的房间),后面的所有rollout都在浪费计算资源。
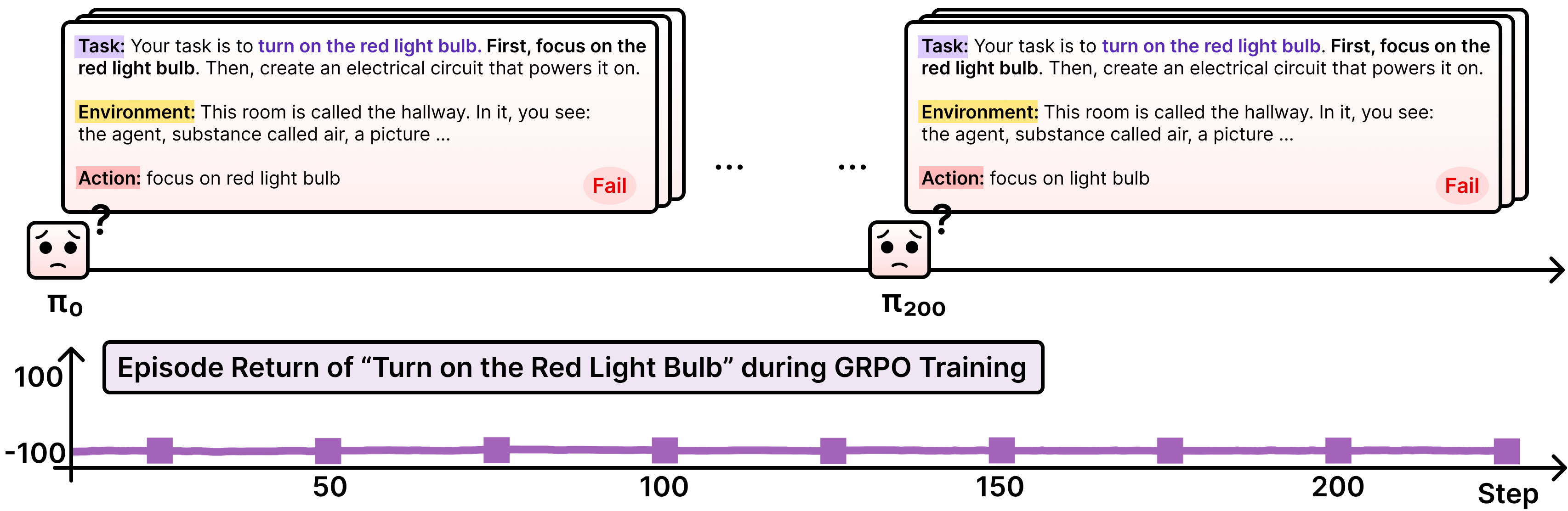
GRPO在交互式环境中的典型失败案例:由于预训练知识不足以覆盖特定环境的操作细节,模型反复在错误的探索路径上打转,奖励信号一直为零。
问题的根源在于:GRPO这类on-policy方法完全依赖当前策略的采样。如果当前策略对某个环境一无所知,它采样出来的轨迹全是垃圾,没有正奖励,GRPO的优势估计全是零,梯度更新相当于没有——陷入了"不探索→学不到→还是不会探索"的死循环。
这就好比你第一次去宜家,不看地图也不问导购,纯靠自己瞎逛,大概率逛了三个小时也找不到那个特定型号的桌子。
现有方案为什么不行?
之前的解决思路主要有两条:
-
Reflexion(Shinn et al., 2023):让模型在失败后进行"反思",生成经验总结,下次带着这些总结去重试。问题是——这是纯推理时的技巧,不更新模型参数。模型本身没变聪明,只是考试时多了张小抄。更要命的是,它严重依赖推理时的长上下文能力,context window不够的时候就抓瞎了。
-
Retrospex(Wang et al., 2025):把成功经验收集起来做离线训练(SFT/DPO)。这算是更新了参数,但纯离线方式有个天然缺陷——分布偏移(distribution shift)。你用"带着小抄"生成的轨迹去训练"不带小抄"的模型,两者的分布差异可能很大,训练容易不稳定。
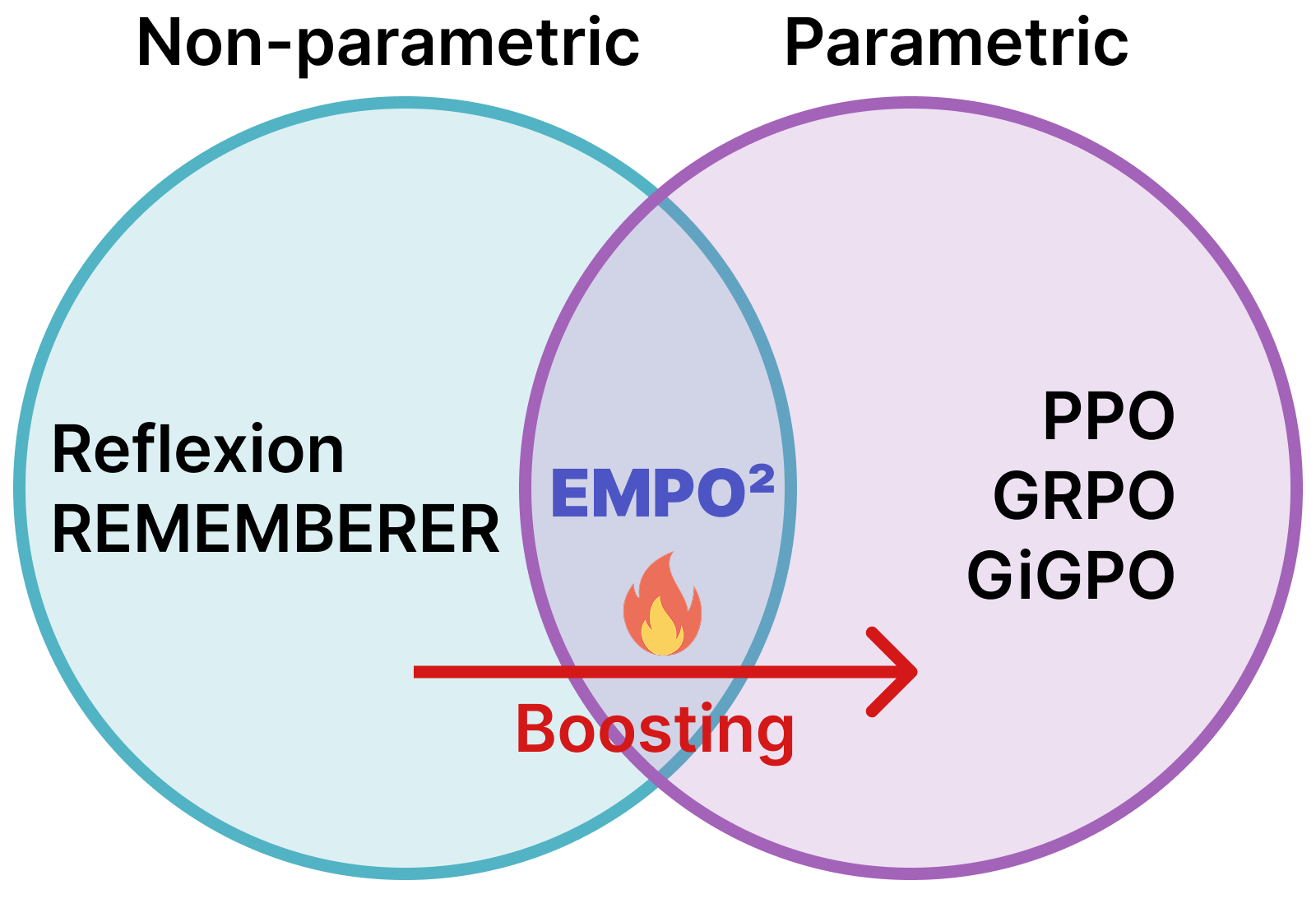
这张维恩图说明了EMPO²的核心思路:非参数记忆(左圈)和参数化知识(右圈)各有所长,EMPO²通过混合训练让两者互补。Reflexion只用左圈,GRPO只用右圈,而EMPO²把两者结合起来。
🧠 EMPO²的核心思路
EMPO²的设计灵感可以用一个学习类比来理解:
想象你在准备一场很难的考试。 最聪明的策略不是只刷题(纯RL),也不是只看笔记(纯Reflexion),而是:
1. 先带着笔记做模拟题,在更大的解题空间里探索(memory-augmented rollout)
2. 做完后把模拟题的经验内化到脑子里(off-policy知识蒸馏)
3. 同时也练习不看笔记直接做题,确保考试时不依赖外部资源(on-policy训练)
4. 根据做题结果不断更新和优化笔记(memory update)
这就是EMPO²的四个核心组件。
三种训练模式
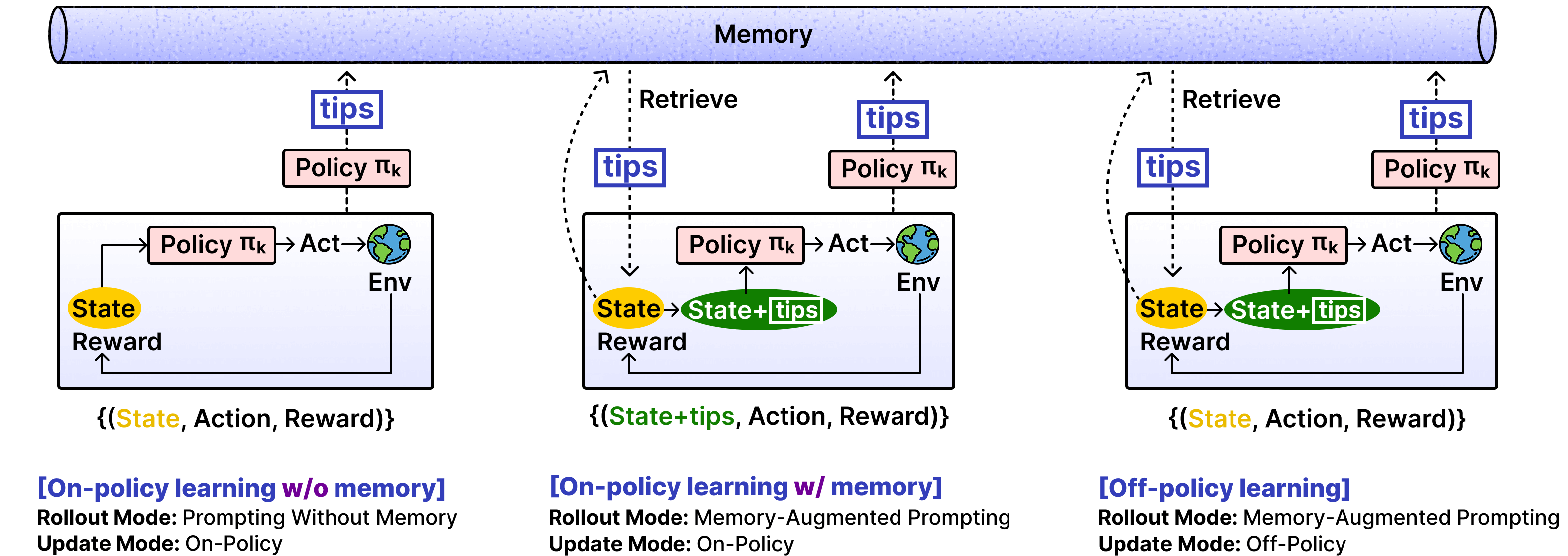
EMPO²的三种训练模式并行工作:(a) 不带记忆的on-policy训练——模型凭自己的实力探索;(b) 带记忆的on-policy训练——模型带着"笔记"探索更广的空间;(c) off-policy知识蒸馏——把"带笔记"时学到的经验蒸馏给"不带笔记"的模型。
EMPO²同时运行三种训练模式:
模式(a):裸考训练(On-policy without memory)
模型不带任何外部记忆,纯靠自身参数生成动作。这保证了模型的独立能力不会退化——毕竟你不能指望考试时永远有小抄。
模式(b):开卷训练(On-policy with memory)
模型从记忆库中检索相关的tips,拼接到prompt前面,然后再生成动作。这让模型能探索到凭自身能力到不了的区域——就像带着攻略玩游戏,能发现更多隐藏关卡。
模式(c):知识蒸馏(Off-policy distillation)
这是最精妙的部分。模式(b)中"带记忆"生成的优质轨迹,被用来训练模式(a)中"不带记忆"的策略。相当于把开卷考试中学到的解题技巧,内化为闭卷考试时的真实能力。
记忆系统的设计
记忆库里存的是什么?是模型自己生成的"tips"——对环境的观察总结。比如在ScienceWorld里,一个tip可能是:
"在厨房里可以找到温度计和烧杯,加热器在工作室里。"
这些tips通过以下流程生成和维护:
- 生成:每次rollout结束后,模型根据观察到的环境信息生成tips
- 检索:使用embedding模型计算相似度,为当前任务检索最相关的K条tips
- 更新:用内在奖励 \(r_{\text{intrinsic}} = 1/n\) 鼓励探索新状态(\(n\) 是该状态被访问的次数)
- 淘汰:效果不好的tips会被逐步淘汰
这个设计很聪明——tips是文本形式的,不改变模型架构,可以随时增删改查,而且对LLM来说天然就容易理解和使用。
🏗️ 技术细节
混合训练的损失函数
EMPO²的总损失函数由三部分组成:
其中 \(\alpha_1, \alpha_2, \alpha_3\) 是权重系数。前两项用标准的GRPO损失(基于group-relative advantage estimation),第三项是off-policy知识蒸馏损失。
Off-Policy训练的稳定性:低概率掩码
Off-policy训练最大的难题是重要性采样比(importance sampling ratio)可能爆炸。当行为策略(带记忆)和目标策略(不带记忆)差异较大时,某些token的重要性权重会变得极大,导致梯度不稳定。
EMPO²引入了一个简单但有效的机制——低概率掩码(Low-Probability Masking):
对于目标策略(不带记忆)概率低于阈值 \(\delta\) 的token,直接把它们的损失权重设为零。
直觉是这样的:如果"不带记忆"的模型对某个token的预测概率很低(比如 < 1%),说明这个token对于当前模型来说太"超纲"了,强行学习只会带来噪声。不如跳过,等模型在其他地方先积累足够知识后,这些困难token自然会变得可学。
def compute_off_policy_loss(logprobs_target, logprobs_behavior, advantages, delta=0.01):
"""EMPO²的off-policy损失计算,带低概率掩码"""
# 重要性采样比
importance_ratio = torch.exp(logprobs_target - logprobs_behavior)
# 低概率掩码:目标策略概率太低的token不参与训练
probs_target = torch.exp(logprobs_target)
mask = (probs_target >= delta).float()
# PPO-style clipped objective
ratio_clipped = torch.clamp(importance_ratio, 1 - eps, 1 + eps)
loss = -torch.min(importance_ratio * advantages, ratio_clipped * advantages)
# 应用掩码
loss = (loss * mask).sum() / mask.sum()
return loss
论文中展示了一个很有说服力的例子:在ScienceWorld的某个任务中,不带低概率掩码的off-policy训练会出现token级别重要性权重超过100的情况(原文表3),而加上 \(\delta=0.01\) 的掩码后,这些极端值被有效过滤。
内在奖励与探索
EMPO²还引入了内在奖励(Intrinsic Reward)来鼓励探索新状态:
其中 \(n(s)\) 是状态 \(s\) 被访问的次数。第一次到达新状态奖励为1,之后递减。这种"好奇心驱动"的机制在经典RL中已被验证有效(如RND、ICM),EMPO²将其适配到了LLM智能体场景。
最终奖励为环境外部奖励和内在奖励的加权和:
🧪 实验结果
主实验:ScienceWorld
ScienceWorld是一个文字版科学实验模拟器,包含6大类18个子任务,从化学混合到电路导通测试,难度跨度很大。EMPO²在这个benchmark上的表现堪称碾压级别:
| 类别 | 任务 | Naive | Reflexion | Retrospex | GRPO | EMPO² |
|---|---|---|---|---|---|---|
| 化学 | chemistry-mix | -42.0 | 1.2 | 20.8 | 12.4 | 42.7 |
| chemistry-mix-paint-secondary | -33.0 | 0.0 | 27.8 | 7.1 | 33.3 | |
| chemistry-mix-paint-tertiary | -33.9 | 36.9 | 7.6 | 42.6 | 39.2 | |
| 分类 | find-animal | -58.2 | 39.5 | 25.9 | 72.4 | 100.0 |
| find-living-thing | -65.1 | 36.6 | 20.6 | 68.7 | 100.0 | |
| find-non-living-thing | -35.9 | 4.8 | 89.1 | 24.7 | 100.0 | |
| find-plant | -47.1 | 15.1 | 23.0 | 46.2 | 100.0 | |
| 生物1 | identify-life-stages-1 | -48.9 | 9.2 | 19.0 | 17.9 | 36.2 |
| identify-life-stages-2 | -50.7 | 33.8 | 11.0 | 39.5 | 56.3 | |
| 生物2 | lifespan-longest-lived | -51.8 | 44.6 | 55.0 | 78.2 | 100.0 |
| lifespan-longest/shortest | -56.2 | 34.1 | 38.0 | 62.3 | 100.0 | |
| lifespan-shortest-lived | -56.8 | 6.1 | 67.0 | 20.6 | 100.0 | |
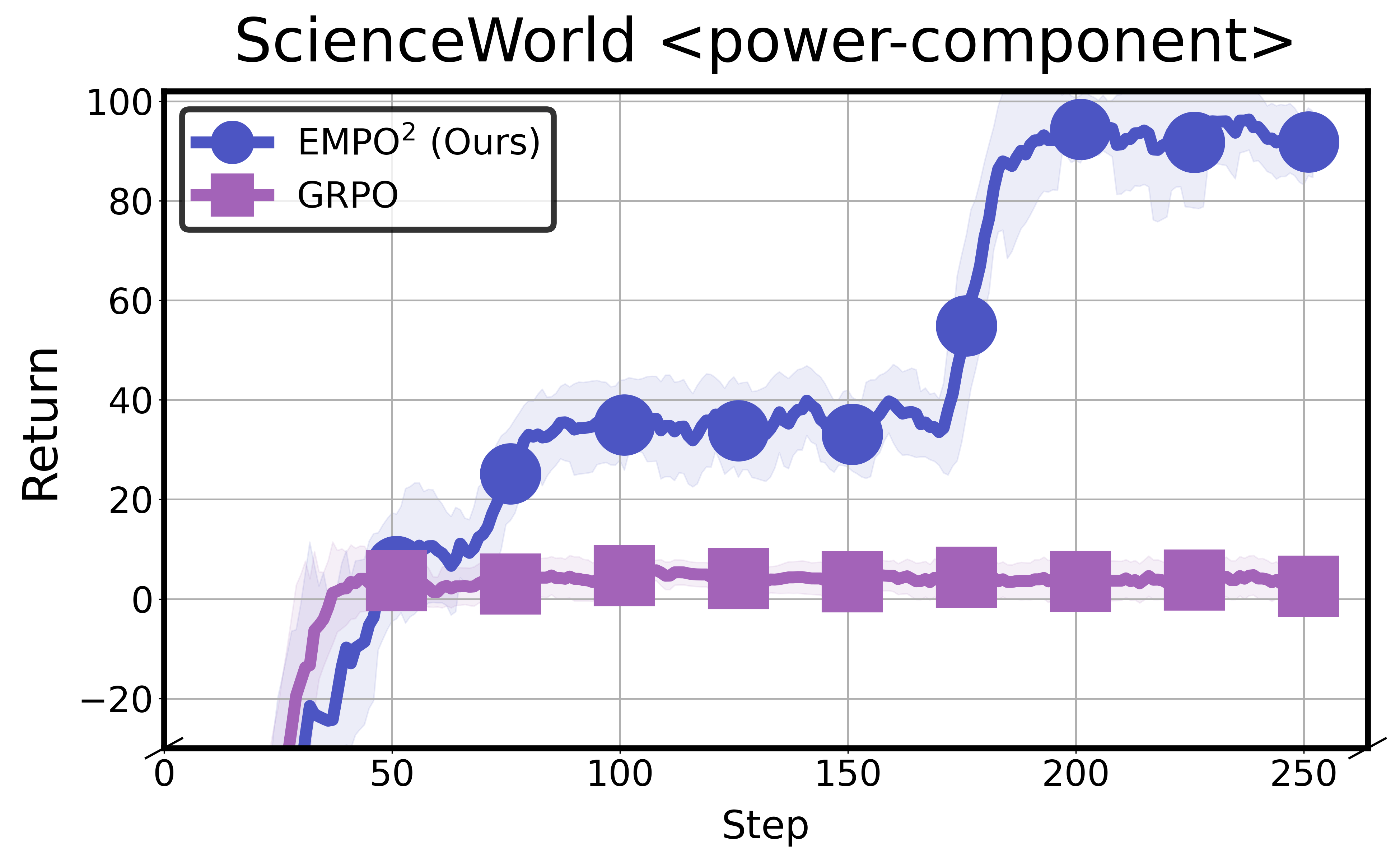
| 电学 | power-component | -90.0 | 6.3 | 8.2 | 15.1 | 94.3 |
| power-renewable-vs-nonrenew | -85.0 | 11.7 | 10.0 | 24.6 | 92.6 | |
| test-conductivity | -86.9 | 13.2 | 60.0 | 27.8 | 89.5 | |
| test-conductivity-unknown | -81.7 | 2.6 | 65.5 | 9.5 | 71.4 | |
| 测量 | measure-melting-point | -97.5 | 11.4 | 26.5 | 19.8 | 27.6 |
| use-thermometer | -83.7 | 0.9 | 32.5 | 7.6 | 82.7 | |
| 平均 | -61.3 | 17.1 | 33.8 | 33.2 | 75.9 |
几个值得关注的点:
7个满分任务。 find-animal、find-living-thing、find-non-living-thing、find-plant、lifespan-longest-lived、lifespan-longest/shortest、lifespan-shortest-lived,全部100.0分。这些任务的共同特点是:核心挑战在于在环境中定位目标对象。分类任务需要找到正确的动植物,寿命任务需要找到并比较多种生物。一旦记忆系统帮模型"记住"了各类对象在环境中的位置,这些任务就变成了确定性的执行。
电学类任务的巨大飞跃。 power-component从GRPO的15.1飙升到94.3(+524%),test-conductivity从27.8到89.5。电学实验需要复杂的多步操作——连接电路、测试材料导电性——这恰好是记忆增强探索最擅长的场景。
Reflexion的平庸表现。 平均17.1分,在chemistry-mix-paint-secondary上直接0分。Reflexion不更新参数,只靠prompt中的反思总结。当任务需要的知识完全超出预训练范围时,再多的反思也是在错误的方向上打转——你不知道宜家的布局,反思一百次也还是找不到那个柜子。
GRPO的天花板。 GRPO平均33.2分,和Retrospex的33.8分相当。有趣的是Naive策略平均得分为-61.3,说明这些任务有惩罚机制——瞎操作不只是得零分,还会扣分。GRPO至少学会了"别乱搞",但离"做对"还差很远。
主实验:WebShop
WebShop是一个模拟网上购物的环境,模型需要根据用户需求搜索商品并下单。
| 方法 | Score | SR (%) |
|---|---|---|
| Naive | 26.4 | 7.8 |
| Reflexion | 58.1 | 28.8 |
| Retrospex | 73.1 | 60.4 |
| GRPO | 79.3 | 66.1 |
| GiGPO (w/o std) | 86.2 | 75.2 |
| EMPO² | 88.3 | 76.9 |
WebShop的提升幅度没有ScienceWorld那么夸张(+11.3% vs +128.6%),这符合预期:WebShop的探索空间相对较小,搜索+点击的操作模式更接近LLM的预训练经验,GRPO本身就能学到不错的策略。但EMPO²仍然稳定地占据了第一名。
OOD泛化能力
分布外(OOD)适应实验结果:在未见过的ScienceWorld任务变体上,EMPO²仅需几步记忆检索就能快速适应,而GRPO需要从头训练。
这是我觉得最有意思的一个实验。作者测试了模型在从未见过的任务变体上的表现——比如训练时只做过"找最长寿的动物",测试时换成"找最短寿的植物"。
结果显示,EMPO²在OOD任务上仅通过记忆检索就能快速适应新任务。这说明记忆系统不只是死记硬背,而是真的学到了可迁移的环境知识——它记住的不是"怎么找到猫",而是"厨房里有哪些动物、花园里有哪些植物"这种通用环境信息。
消融实验
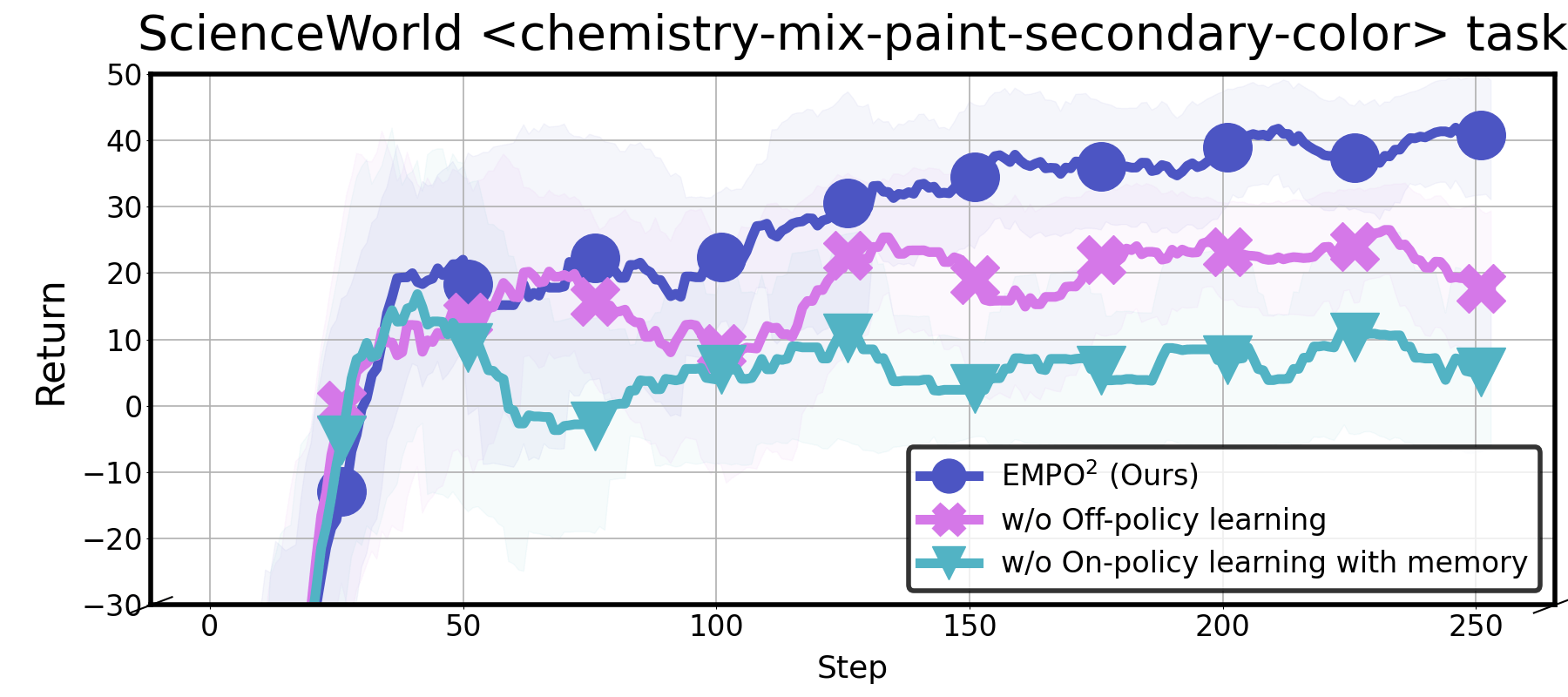
ScienceWorld chemistry-mix-paint-secondary-color 任务上的消融实验:完整版EMPO²(蓝线)回报最高达~40,去掉off-policy训练(橙线)后回报降至~20,再去掉带记忆的on-policy训练(绿线)后仅剩~8,说明每个组件都不可或缺。
消融实验验证了EMPO²每个组件的必要性:
| 配置 | 平均分 | 说明 |
|---|---|---|
| EMPO²(完整版) | 75.9 | 三种模式全开 |
| − off-policy | 下降明显 | 去掉知识蒸馏,探索到的知识无法内化 |
| − memory-augmented on-policy | 下降 | 去掉开卷训练,探索范围受限 |
| − intrinsic reward | 下降 | 去掉内在奖励,探索动力不足 |
| − low-prob masking | 下降 | 去掉掩码,off-policy训练不稳定 |
Off-policy训练是贡献最大的组件。没有它,模型虽然能借助记忆探索到更广的空间,但学到的经验只存在于"带记忆"的模式中,"不带记忆"的裸模型能力没有提升。
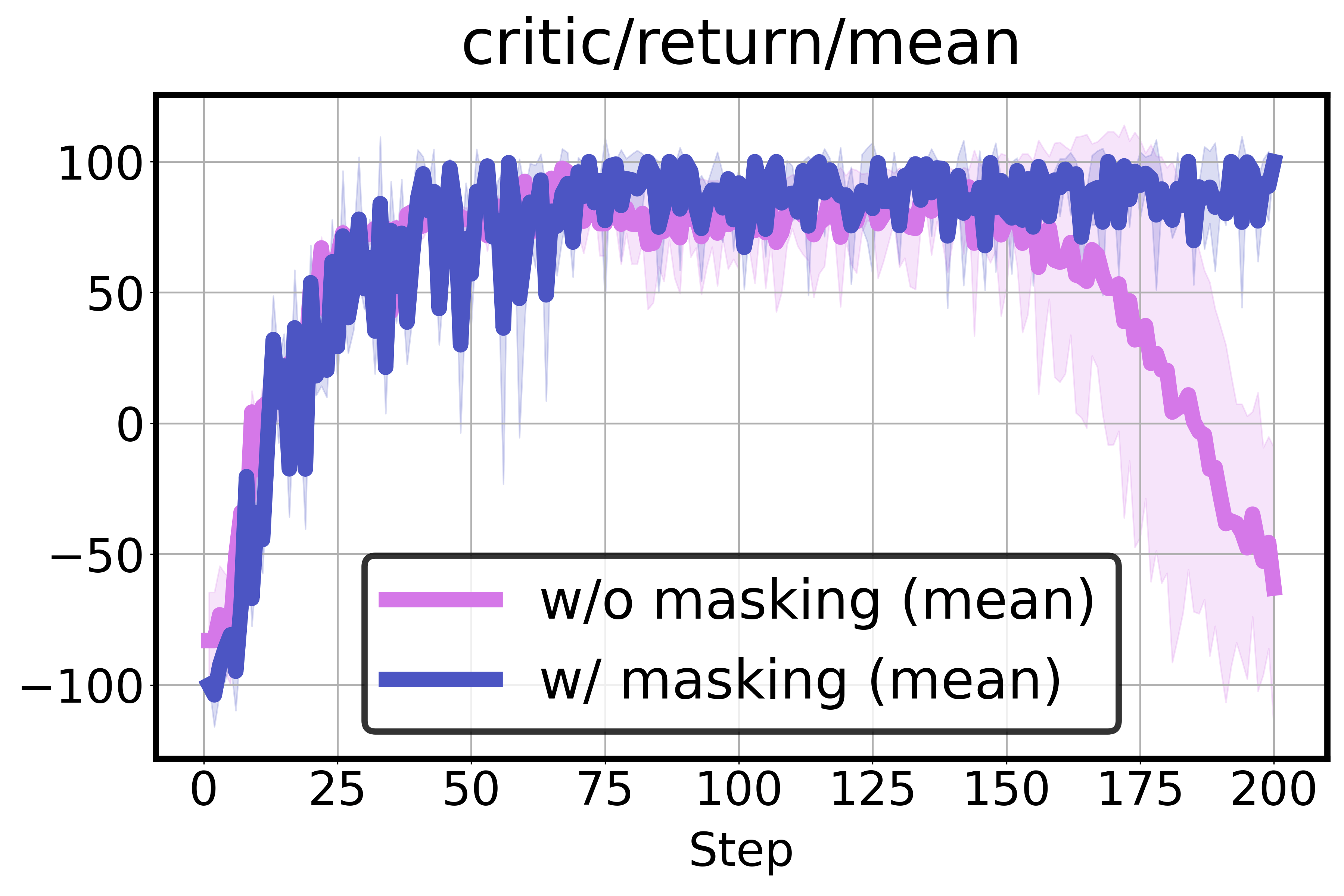
低概率掩码的效果(单图双线对比):有掩码时(蓝线)训练回报在step 50后稳定保持在~100;无掩码时(橙线)初期表现相当,但在step ~150后发生灾难性崩溃,回报从~100骤降至-50。
低概率掩码的消融结果也很直观。从训练回报曲线可以看到,没有掩码时,off-policy训练在前期还算正常,但到step ~150左右突然发生灾难性崩溃,回报从~100直接跌到-50;而加上掩码后训练曲线始终稳定在~100。\(\delta=0.01\) 在大多数任务上是最佳阈值。
超参数敏感性
作者还做了两个关键超参数的敏感性分析:
Memory Rollout概率 \(p\)(控制多少比例的rollout带记忆):测试了 \(p \in \{0.1, 0.25, 0.4, 0.7\}\)。\(p=0.1\) 时性能接近纯GRPO——记忆用得太少等于没用。\(p=0.4\) 和 \(p=0.7\) 初期学习更快,但 \(p=0.7\) 后期出现波动。默认 \(p=0.25\) 在稳定性和效果之间取得了平衡。
Off-Policy更新概率 \(q\)(控制off-policy更新的频率):测试了 \(q \in \{0.3, 0.5, 0.67, 0.85, 0.95\}\)。两个极端值(0.3和0.95)表现都不好——更新太少学不到东西,更新太多导致分布偏移加剧。默认 \(q=2/3\) 是个不错的平衡点。
内在奖励的消融也很有意思:移除内在奖励会导致学习停滞在较低水平。而换成RND(Random Network Distillation,另一种经典探索奖励)后效果和默认方案差不多,说明EMPO²对内在奖励的具体形式不太敏感——关键是有没有探索激励,而不是用哪种。
🔬 深入分析
为什么memory-augmented探索这么有效?
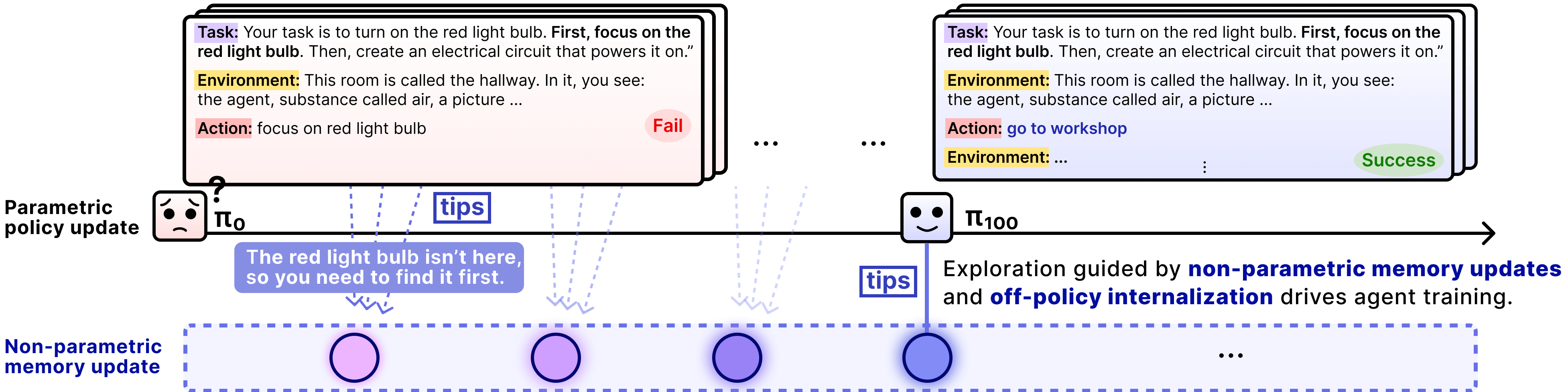
EMPO²的解决方案:记忆系统提供了环境先验知识(如"温度计在厨房"),让模型跳过盲目探索阶段,直接从有信息量的状态开始学习。
关键在于打破了冷启动困境。传统RL需要模型从零开始随机探索,在状态空间巨大的交互环境中,随机策略几乎不可能碰到正奖励。而memory提供了一种"先验知识注入"机制:
- 即使是错误的探索也能产生有用的tips("工作室里没有温度计"也是信息)
- Tips作为文本prompt,能直接改变模型的动作分布,效果立竿见影
- 好的tips会通过奖励信号被保留和强化,形成正反馈循环
这和人类学习很像——你第一次做一道菜失败了,但记住了"盐要最后放""火太大会糊",第二次就能做得更好。这些经验不需要改变你的大脑结构(参数),只需要你记得就行。
On-Policy + Off-Policy的协同效应
单独的on-policy训练和单独的off-policy训练各有缺陷,放在一起反而互补了:
- On-policy保底:确保模型在没有外部记忆时也能正常工作,避免对记忆系统的过度依赖
- Off-policy加速:把"开卷考"时探索到的好策略蒸馏给"闭卷"模型,加速学习
- 记忆作为桥梁:连接两种训练模式,让非参数知识(tips)逐步转化为参数化知识(模型权重)
与GRPO的本质区别
GRPO(Group Relative Policy Optimization)是DeepSeek提出的一种RL算法,它用组内相对优势来替代PPO的value network,在数学推理等任务上效果很好。但GRPO有一个隐含假设:当前策略采样的轨迹中至少有一些正奖励的样本,否则所有轨迹的advantage都是0,梯度更新为零。
在数学推理中这个假设基本成立——即使是随机策略也有一定概率猜对答案。但在ScienceWorld这样的环境中,一个不了解环境的模型可能连续采样上百条轨迹都拿不到任何正奖励,GRPO就彻底失效了。
EMPO²通过记忆增强打破了这个瓶颈:即使"裸"模型的采样全部失败,"带记忆"版本的采样仍有可能成功,产生正奖励信号,然后通过off-policy训练传递给"裸"模型。
💡 我的思考
观点一:非参数记忆是LLM智能体的"正确打开方式"
过去两年,LLM智能体的记忆系统设计一直在"改架构"和"加外挂"之间摇摆。改架构(如MemoryLLM、StateLM)需要重新预训练,成本高昂;纯外挂(如Reflexion)不更新参数,能力天花板低。
EMPO²找到了一个优雅的中间地带:外挂记忆负责探索,参数化训练负责内化。这个思路让我想到了人类的"外部记忆→内化知识"过程——我们学开车时会先看教程(外部记忆),然后通过反复练习把操作变成肌肉记忆(参数化知识)。教程不需要永远随身携带,但没有教程的冷启动阶段会非常痛苦。
我认为这种"非参数记忆辅助训练→参数化知识长期存储"的范式,会成为未来LLM智能体训练的标准模板。特别是在需要环境交互的任务中,纯靠RL盲目探索的时代应该结束了。
观点二:Off-Policy在LLM-RL中被严重低估了
当前LLM强化学习社区几乎一边倒地偏好on-policy方法(PPO、GRPO、REINFORCE),对off-policy避之不及。理由是"LLM的action space太大,off-policy的重要性采样比会爆炸"。
EMPO²用一个简单的低概率掩码就解决了这个问题——虽然称不上完美,但至少证明了off-policy在LLM场景下是可行的。这打开了一个很大的想象空间:如果我们能更好地做LLM的off-policy训练,就能复用历史数据、实现experience replay,训练效率会大幅提升。
当然,\(\delta=0.01\) 的掩码本质上是一种"鸵鸟策略"——难的token直接跳过不学。在更复杂的任务中,这种策略可能会错过重要的学习信号。如何更精细地处理on-policy和off-policy之间的分布差异,还有很大的研究空间。
局限性分析
说了这么多优点,也得聊聊问题:
-
计算开销。三种训练模式并行运行,加上记忆检索和更新,训练成本至少是GRPO的3倍。论文中报告EMPO²在ScienceWorld上需要约4000步训练(约40小时,8×A100),这在学术界尚可接受,但工业落地时需要认真考虑ROI。
-
记忆质量的瓶颈。Tips的质量完全取决于模型自己的生成能力。如果模型对某个领域完全无知(比如没见过相关预训练数据),生成的tips可能全是错误信息,反而会误导探索。论文没有讨论这种"有毒记忆"的情况。
-
检索系统的简单性。论文使用余弦相似度做检索,在ScienceWorld这种相对简单的环境中够用,但在更复杂的真实场景中(比如记忆库有上万条tips),检索的准确性和效率会成为瓶颈。
-
基座模型限制。实验基于Qwen2.5-7B-Instruct,这是一个中等规模的模型。在更大的模型上(如70B),预训练知识更丰富,探索困境可能不那么严重,EMPO²的优势是否还能保持?反过来,在更小的模型上(如3B),记忆系统能否弥补模型能力的不足?论文没给出答案。
📊 关键数据一览
| 指标 | 数值 |
|---|---|
| 基座模型 | Qwen2.5-7B-Instruct |
| ScienceWorld平均分 | 75.9(vs GRPO 33.2,+128.6%) |
| WebShop得分 | 88.3(vs GRPO 79.3,+11.3%) |
| WebShop成功率 | 76.9%(vs GRPO 66.1%) |
| 满分任务数 | 7 / 18(ScienceWorld) |
| 训练硬件 | 8×NVIDIA A100 40GB |
| 学习率 | 1e-6 |
| GRPO组大小 | 8 |
🔗 相关工作对比
| 方法 | 参数更新 | 记忆增强 | On/Off-Policy | 探索能力 | ScienceWorld均分 |
|---|---|---|---|---|---|
| GRPO | ✅ | ❌ | On-policy | 弱 | 33.2 |
| Reflexion | ❌ | ✅ (推理时) | — | 中 | 17.1 |
| Retrospex | ✅ | ✅ (训练时) | Off-policy | 中 | 33.8 |
| EMPO² | ✅ | ✅ (训练+推理) | 混合 | 强 | 75.9 |
📝 总结
EMPO²的贡献可以归结为三点:
-
发现了问题:清晰地刻画了on-policy RL在交互式环境中的探索困境,并通过实验证明GRPO在ScienceWorld上基本失效。
-
提出了方案:用非参数记忆增强探索,用混合on/off-policy训练实现知识内化,用低概率掩码稳定off-policy训练。三个技术点分别解决探索、蒸馏、稳定性三个子问题。
-
验证了效果:在ScienceWorld上128.6%的提升不是小打小闹的增量改进,而是质变级别的飞跃。7个满分任务说明模型真的学会了完整的任务执行流程。
这篇论文让我想到了一句话:"智能不是不需要记忆,而是要知道什么时候用记忆、什么时候靠自己。" EMPO²在这个维度上给出了一个漂亮的工程实现。