GPT-5.1 也只拿了 69 分?妙问团队三篇论文揭秘:大模型在真实业务中翻车的真相与破局之道
三篇论文,一条主线:让大模型在真实广告业务中干活时,少犯错、能纠错、知道自己几斤几两。
一、先说背景:我们到底在解决什么问题?
过去一年,大模型在广告营销领域的落地速度远超预期。从智能客服到投放分析,从素材建议到数据报表,几乎每个环节都在尝试接入 LLM。
但实际上线后,我们很快发现了三个绕不开的痛点:
痛点一:不知道 Agent 能力到底行不行。 学术界有一大堆 benchmark,但拿来评测广告场景下的 Agent,基本都"水土不服"——数据是编的、任务是简化的、评测只看最终答案对不对。我们需要一个能反映真实业务复杂度的"试金石"。
痛点二:Agentic RAG 训练太难收敛。 让模型学会"自己搜、自己想、自己答"的多步推理,用强化学习(RL)来训是目前最有潜力的路。但传统 RL 只看最终结果——答对了给奖励,答错了零分。这就导致大量"虽然答错了但中间推理有价值"的样本被白白浪费,训练效率低、不稳定。
痛点三:线上系统的幻觉问题。 广告问答场景下,模型编造 URL 不是"用户体验差"的小事,而是可能导致合规风险的大事。我们的基线系统 URL 准确率只有 93.6%——听起来还行?但每天上万次查询,6.4% 的错误率意味着每天有几百个用户被假链接坑。
这三个痛点,分别催生了我们的三篇工作。它们不是孤立的研究项目,而是同一条技术路线上的三个环节——评测→训练→部署,形成了一个完整的闭环。
二、AD-Bench:给广告 Agent 搭一个"真题考场"
论文:AD-Bench: A Real-World, Trajectory-Aware Advertising Analytics Benchmark for LLM Agents 链接:https://arxiv.org/abs/2602.14257
为什么现有 benchmark 不够用?
市面上的 Agent 评测基准(GAIA、AgentBench、WebArena 等)有个共同问题:它们测的是"通用能力",而不是"业务能力"。
打个比方,这些 benchmark 就像高考模拟题——覆盖面广,但不会考"腾讯广告后台 OCPC 出价策略的 ROI 计算方法"。而我们的广告优化师每天真正要回答的,恰恰就是这类高度专业化的问题。
更麻烦的是,现有 benchmark 只关心最终答案对不对,不看中间过程。一个 Agent 瞎猫碰上死耗子蒙对了答案,和一个步骤清晰、逻辑合理地推导出答案,在评分上完全一样。这对工程优化毫无指导意义——你连问题出在哪都不知道。
我们怎么做的?
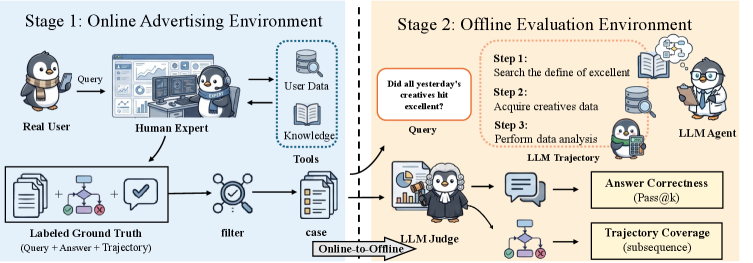
AD-Bench 的两阶段流程。左边是在线广告环境中,专家标注生成带标注的 Ground Truth;右边是离线评估环境中,LLM Agent 执行任务后,用 LLM Judge 判断答案正确性,同时对 Agent 的工具调用轨迹做子序列覆盖率匹配。
从腾讯广告营销平台的真实运营日志中,筛选出 823 条原生用户分析请求,让领域专家逐条标注完成任务所需的工具调用序列和最终答案。
任务按复杂度分三级: - L1(24%):查个数据就行,比如"账户 A 昨天消费多少" - L2(47%):需要筛选+计算,比如"过去 7 天 ROI 低于 2 的计划有哪些?平均转化成本?" - L3(29%):需要跨数据源推理+领域知识,比如"结合行业均值分析这组素材效果,给优化建议"
L2 占了将近一半,这和我们的直觉一致——广告运营中最高频的需求就是"帮我筛一下、算一下"。
评测维度上,我们搞了"结果分+过程分"双轨评估:
- 答案正确率(Pass@k):用 LLM Judge 对比最终答案和 ground truth
- 轨迹覆盖率(Trajectory Coverage):检查 Agent 实际调用的工具序列,是否覆盖了专家标注的关键步骤
第二条尤其重要。它相当于考试的"过程分"——不光看你算对了没有,还看你的解题步骤对不对。一个蒙对答案但工具调用乱七八糟的 Agent,在这个指标下会露出原形。
测出了什么?
我们拉了 10 个主流模型来跑,结果很有意思:
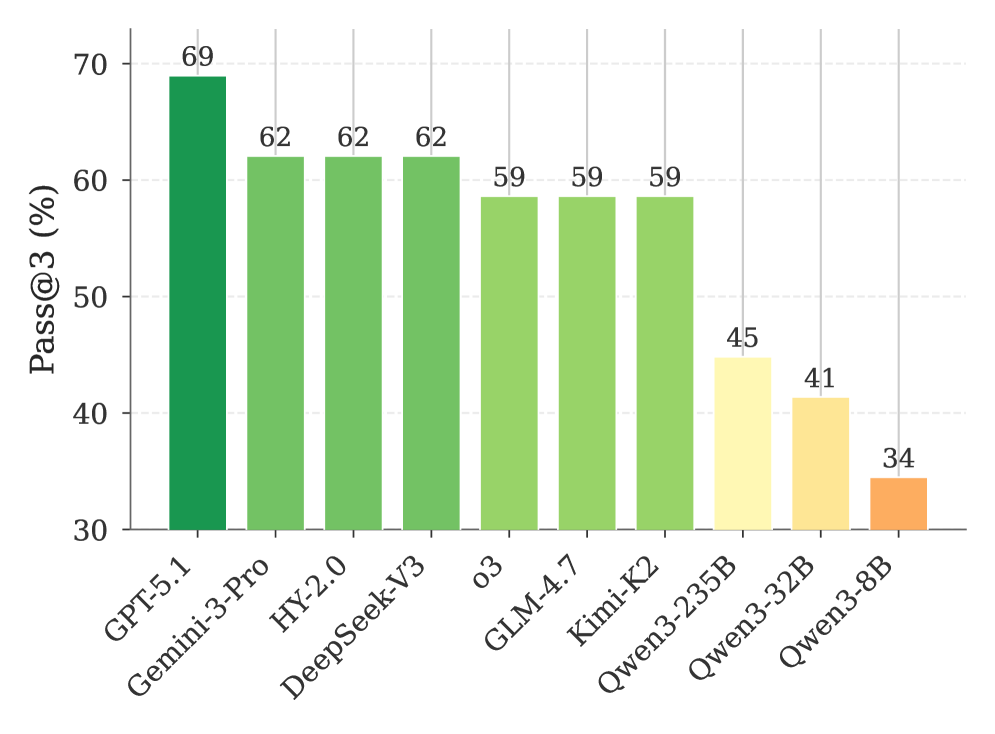
10 个模型在 AD-Bench 上的 Pass@3 得分。GPT-5.1 以 69% 领跑,但距离"好用"还有不小距离。国产模型混元 2.0 和 DeepSeek-V3 都达到了 62%,与 Gemini-3-Pro 持平。
| 模型 | Pass@1 | Pass@3 |
|---|---|---|
| GPT-5.1 | 57% | 69% |
| Gemini-3-Pro | 51% | 62% |
| 混元 2.0 | 49% | 62% |
| DeepSeek-V3 | 51% | 62% |
| Qwen3-235B | 34% | 45% |
最强的 GPT-5.1 也只拿到 69 分。 L3 任务更惨,最好的模型也就 50% 左右——需要跨数据源整合信息+调用领域知识的复杂分析,当前 Agent 真撑不住。
但最有价值的发现藏在 L2 里。看下面这组散点图:
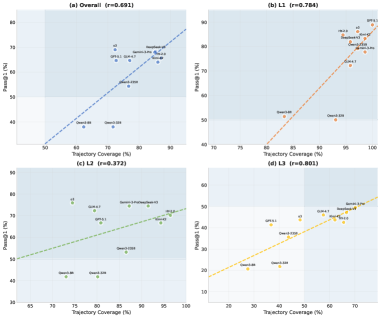
轨迹覆盖率和答案正确率的相关性分析。整体相关系数 r=0.691;按难度拆分后,L1 为 0.784(强相关),L2 为 0.372(弱相关),L3 为 0.803(强相关)。L2 的低相关性说明:问题不在于"不知道该做什么",而在于"做的时候做错了"。
L2 任务的轨迹覆盖率和答案正确率的相关性只有 0.372,远低于 L1 的 0.784 和 L3 的 0.803。
这意味着:L2 的问题不在于"不知道该做什么",而在于"做的时候做错了"。 Agent 知道要调数据查询和计算器工具(轨迹对了),但传错了参数、算错了数值(结果不对)。这直接告诉我们:与其在 L2 上优化规划能力,不如强化数值计算和参数传递的精度。
这就是 AD-Bench 的核心价值——不只是给模型排名,而是帮你定位问题出在哪。
三、Search-P1:让 RL 训练不再"只看成绩单"
论文:Search-P1: Path-Centric Reward Shaping for Stable and Efficient Agentic RAG Training 链接:https://arxiv.org/abs/2602.22576
问题出在哪?
通过 AD-Bench 定位了能力短板后,下一步就是训练。我们希望用 RL 来训练一个能自主搜索和推理的 Agent(Agentic RAG),让它学会多步检索来回答复杂问题。
之前的代表性工作 Search-R1(UIUC)已经证明了 RL 训练 Agentic RAG 是可行的,在多个问答基准上平均提升了 26%。但它有个根本缺陷:奖励信号太稀疏。
Search-R1 的奖励机制就像一个只看成绩单的家长——考了 100 分就表扬,没考 100 分就零分。这带来三个后果:
- 一个学生"蒙对了"和"真正理解了"得到同样的奖励,模型分不清好路径和碰巧正确的路径
- 大量答错的样本(尤其是训练早期)获得零奖励,对训练完全没有贡献——白白浪费了
- 训练震荡严重,模型表现忽好忽差
我们的方案:既看结果也看过程
Search-P1 的核心改进可以用一句话概括:不只看你答对了没有,还看你的推理路径好不好。

Search-P1 框架全景。包含四个核心模块:(1) 输入与策略更新,(2) 轨迹生成(Planner→Search→Think→Answer),(3) 参考计划生成(拒绝采样+LLM 投票),(4) 双轨路径评分(自一致性 + 参考对齐)。
具体来说,我们做了三件事:
第一,强制模型"先想后做"。 在模型开始搜索之前,要求它先输出一个推理计划(Planner):"我打算分几步解决这个问题,每一步搜索什么"。这就像做菜之前先在脑子里过一遍步骤,而不是走一步看一步。
第二,双轨路径评分。 从两个角度给推理路径打分:
- 自一致性(Track A):你是否按照自己制定的计划执行了?如果你计划做三件事但只做了两件,或者做了五件事里只有两件在计划内,分数都会降低。
- 参考对齐(Track B):你的路径是否和"好的路径"对齐?我们通过拒绝采样+投票,从模型自己生成的大量轨迹中提取出共识性的好路径作为参考。
最终路径得分取两条轨道的最大值——这确保了那些找到非标准但同样有效的推理路径的样本不会被误伤。
第三,给失败样本也打分。 答案错了不再一律零分。如果推理过程中有合理的搜索和分析,哪怕最终没答对,也能拿到一个小的正分(上限约 0.2)。就像体育比赛的"技术分"——摔倒了也能靠之前的高难度动作拿一些分数。
效果如何?

Search-P1(蓝色填充)与各基线方法在 8 个问答基准上的雷达图对比。可以清楚看到 Search-P1 在几乎所有维度上都包住了其他方法,尤其是 AD-QA(广告问答)维度上的优势最为明显。
在 Qwen2.5-7B 上的实验结果:
| 方法 | 8个QA基准平均 | AD-QA(广告问答) |
|---|---|---|
| 标准 RAG | 34.8% | 46.6% |
| Search-R1 | 41.1% | 65.6% |
| Search-P1 | 48.8% | 86.2% |
几个关键数字:
- 相比 Search-R1,平均提升 7.7 个百分点
- 在 AD-QA(我们的广告问答数据集)上提升超过 20 个百分点——这个数据集包含大量高难度的专业问题,路径奖励在这种场景下价值特别大
- 多跳问答任务(HotpotQA、2Wiki、Musique)全面领先,说明路径奖励对复杂推理特别有效
还有个意外之喜:Search-P1 不仅更准确,还更高效。 训练过程中,模型的平均搜索轮次从约 4 次下降到约 2.2 次——它学会了"用更少的搜索达到更高的准确率"。每少搜一次,就意味着少一次检索延迟和计算开销。

训练与推理效率对比。左图:训练过程中 Search-P1(蓝色)准确率快速攀升的同时搜索轮次反而在下降,而 Search-R1(绿色)准确率停滞、搜索轮次居高不下。右图:推理阶段不同任务类型的平均搜索轮次,Search-P1 全面更低。
消融实验确认了双轨设计缺一不可:去掉 Track B(参考对齐)掉 5.3 个点,去掉 Track A(自一致性)掉 3.1 个点,而两者结合的提升远超单轨。
| 消融配置 | 平均准确率 | 变化 |
|---|---|---|
| Search-P1(完整双轨) | 47.3% | — |
| 去掉 Track B(参考对齐) | 42.0% | -5.3 |
| 去掉 Track A(自一致性) | 44.2% | -3.1 |
| Search-R1(基线) | 39.6% | -7.7 |
四、Faithful RAG:让线上系统"不说谎"
论文:Towards Faithful Industrial RAG: A Reinforced Co-adaptation Framework for Advertising QA 链接:https://arxiv.org/abs/2602.22584
从实验室到生产线,最后一公里有多远?
有了评测基准(AD-Bench)和训练方法(Search-P1),下一步就是把 RAG 系统真正推上生产线。但生产环境带来了一个实验室里感受不到的问题:容错率极低。
学术论文追求的是"平均准确率提升了几个点",但在线上系统里,哪怕 1% 的错误率,乘以每天的查询量,都是一个巨大的数字。而广告场景下有一类错误特别致命——URL 幻觉。
模型给用户一个操作指引,末尾附了一个帮助文档链接,用户点进去发现是 404 页面。轻则用户骂娘,重则可能被投诉、甚至产生合规风险。这不是偶发事件——我们测了市面上几个主流商业模型,URL 准确率最低的只有 92.2%。

传统方法的四类典型问题——回答不完整、编造虚假 URL、过度生成无关内容、冗长赘述。对比之下,新方案能精准引用真实 URL,回答简洁且覆盖关键点。
检索端:GraphRAG + 传统 RAG 并行

整体架构。左半部分是检索模块,GraphRAG 通道和传统 RAG 通道并行运行,结果合并去重后送入右半部分的生成模块。生成模块用 GRPO + 四维奖励函数来训练 LLM,确保输出忠实、合规、不编 URL。
我们的做法是"两条腿走路"。
传统 RAG(BGE 向量检索 + BM25 关键词匹配)覆盖面广但"看不见"知识之间的关系。GraphRAG 在文档块之上叠了一层知识图谱,能沿着实体关系做多跳追踪,但受限于图谱覆盖率——没被抽取到图谱里的知识就找不到。
所以我们让两者并行运行,结果取并集去重。GraphRAG 负责高频问题的深度检索,传统 RAG 负责长尾问题的广度覆盖。延迟上也划算——两条通道同时发起,总延迟等于较慢的那个,控制在 200ms 以内。
建图时有个取巧的做法:不是在全量知识库上建图(太贵),而是从 3 个月的生产日志中统计引用频率,只选 Top 10% 的高频 chunk 来建图。广告问答遵循幂律分布——10% 的知识覆盖了大部分用户问题,这样建图成本可控但效果不打折。
并行方案把知识召回效率从 62.3% 提升到 81.5%。

三种检索方案对比。GraphRAG 单独跑就比 Base RAG 好不少,但并行方案(Parallel)在召回效率上进一步提升——两条腿确实比一条腿跑得稳。
生成端:四把尺子的 GRPO 训练
检索端捞回了好的证据,还得确保模型"用好"这些证据。我们用 GRPO(DeepSeek 提出的组相对策略优化算法)来训练生成模型,核心是设计了四维奖励函数:
| 奖励维度 | 衡量什么 | 怎么打分 |
|---|---|---|
| 忠实度 \(R_f\) | 回答是否基于检索证据 | NLI 模型逐条验证 |
| 风格合规 \(R_s\) | 格式和语气是否合规 | 规则模板匹配 |
| 安全性 \(R_a\) | 是否触发安全红线 | 安全审核模型 |
| URL 有效性 \(R_h\) | 引用的 URL 是否真实存在 | 发 HTTP 请求验证 |
其中 URL 有效性奖励是我们针对广告场景专门设计的——HTTP 状态码是客观事实,不需要人工标注,返回 200 就是存在,404 就是不存在。这是一种"零成本高质量"的奖励信号。
训练过程中,安全性最先收敛(模型很快学会了哪些话不能说),忠实度和 URL 有效性爬坡最慢(学会判断"哪些信息有据可查"和"哪些 URL 是真的"需要更多训练)。但四维奖励之间没有出现冲突,最终都收敛到了不错的水平。

训练曲线。五条线分别代表风格(蓝)、安全(橙)、忠实度(灰)、URL 有效性(黄)和总体奖励(深蓝)。Safety 和 Style 在训练早期就快速收敛,Faithfulness 和 Link 爬坡更慢但最终也稳定了。四维奖励之间没有严重冲突。
线上效果
基座模型选了 Qwen3-32B——不是最大的模型,但 RL 训练后的 32B 模型在 FaithEval 基准上反超了参数量大得多的 DeepSeek-V3.2(81.2% vs 78.5%)。这再次验证了"小模型+好训练"比"大模型+裸跑"更靠谱。

FaithEval 泛化测试。RL 训练后的 Qwen3-32B(右)在所有场景上都大幅提升,Overall 从 62.8% 跃升到 81.2%,甚至超过了参数量大得多的 DeepSeek-V3.2(78.5%)。
在线 A/B 测试结果:
| 指标 | 变化 |
|---|---|
| 点赞率 | +28.6% |
| 点踩率 | -46.2% |
| URL 幻觉率 | -92.7% |
URL 准确率 99.3%,碾压 DeepSeek-V3.2(93.6%)、Kimi K2.5(95.0%)、豆包(92.2%)、混元 2.0(96.5%)等所有商业模型。

URL 准确率 PK。99.3% vs 最高的混元 2.0(96.5%),差距看起来只有 2.8 个百分点,但放到每天上万次查询的量级上,错误数差了一个数量级。
| 模型 | URL 准确率 |
|---|---|
| Ours (Qwen3-32B-RL) | 99.3% |
| HunYuan 2.0 | 96.5% |
| Kimi K2.5 | 95.0% |
| DeepSeek-V3.2 | 93.6% |
| Doubao 1.8 | 92.2% |
点踩率降了近一半,这说明之前那些"编 URL"、"答非所问"的情况确实大幅减少了。这套系统上线后已经稳定服务了大半年,扛住了百万级交互的考验。
五、三篇论文的内在联系
回过头来看,这三篇工作不是各自为战,而是一条完整的技术链路:
AD-Bench 发现了问题:广告分析 Agent 在 L2 任务上的瓶颈不在规划而在执行,在 L3 任务上的瓶颈是多步推理中的错误累积。这两个发现直接指导了后两篇工作的技术方向。
Search-P1 解决了训练问题:通过路径中心的奖励塑形,让 RL 训练能从失败样本中学到东西,训练效率和稳定性大幅提升。AD-QA 上 20 个百分点的提升,说明这种训练方法在广告领域特别有效。
Faithful RAG 解决了部署问题:GraphRAG 并行检索+多维奖励函数的 GRPO 训练,让模型在生产环境中既能回答得准确,又不会编造信息。URL 幻觉率降了 92.7%,这是实实在在的线上收益。
三篇论文还共享了一个核心理念:过程和结果同样重要。
- AD-Bench 的轨迹覆盖率,评估的是 Agent 的推理过程
- Search-P1 的路径奖励,训练的是模型的推理过程
- Faithful RAG 的多维奖励函数,约束的是生成的每个环节
这和只看最终答案的传统范式形成了鲜明对比。我们越来越相信:做好工业级 AI 应用,关键不是让模型"更聪明",而是让模型"更可靠"——犯错率比准确率重要。
六、一些踩坑经验和思考
做这三篇工作的过程中,有几个教训值得分享:
1. "真实数据"比"大规模数据"重要
AD-Bench 只有 823 条数据,但因为每一条都来自真实的广告运营场景,评测出来的结论比几千条合成数据更有参考价值。同样,Faithful RAG 用生产日志中 Top 10% 的高频知识来建图谱,效果远好于在全量数据上建图。
核心是:数据的质量和代表性,比数量更关键。
2. 失败样本是金矿
Search-P1 最重要的贡献之一,是把答错的样本也利用起来。这在广告场景下尤其关键——很多问题本身就难,训练早期答对率很低,如果答错的样本全部浪费,训练效率会极差。
给失败样本一个合理的评价(哪怕是很小的正分),比直接扔掉它们有效得多。
3. 奖励函数要"接地气"
Faithful RAG 的四维奖励函数没有任何花哨的算法创新,但每一维都直接对应一个业务痛点。特别是 URL 有效性奖励——发个 HTTP 请求就能判断真假,零标注成本,效果立竿见影。
设计奖励函数时,先问自己:业务上最不能忍受的错误是什么?然后找一个能客观验证的方式把它量化。
4. 并行架构是工业系统的标配
无论是 Faithful RAG 的 GraphRAG+传统 RAG 并行检索,还是 Search-P1 的双轨路径评分,背后的思路是一样的:单一方案总有盲区,多个方案互相补位更可靠。 并行架构在延迟上也不亏——并行比串行快。
5. 小模型+好训练 > 大模型+裸跑
Faithful RAG 用 Qwen3-32B + RL 训练,效果超过了 DeepSeek-V3.2 裸跑。Search-P1 用 7B 模型也取得了不错的效果。在推理成本敏感的工业场景中,投资训练方法比换更大的模型更划算。
七、接下来的计划
这三篇工作覆盖了"评测→训练→部署"的基本闭环,但还有很多可以做得更好的地方:
- AD-Bench 的工具集可以扩展——当前 9 个工具只覆盖了广告分析的基本操作,A/B 测试分析、素材归因、预算优化等高级功能还没覆盖
- Search-P1 的检索器目前是固定的——如果能联合训练检索器和推理器,效果应该还有提升空间
- Faithful RAG 的知识图谱维护——广告平台产品迭代快,怎么让图谱跟上变化速度是一个工程挑战
- 三篇工作的更深度整合——比如用 AD-Bench 来评测 Search-P1 训练出来的 Agent,再用 Faithful RAG 的多维奖励来指导 Search-P1 的训练
做真实场景的 AI 应用,踩坑无数但确实乐趣满满。欢迎大家阅读论文、交流拍砖!
论文链接汇总: - AD-Bench:https://arxiv.org/abs/2602.14257 - Search-P1:https://arxiv.org/abs/2602.22576 - Faithful RAG:https://arxiv.org/abs/2602.22584