30B参数的搜索代理,凭什么在BrowseComp上和GPT-o3掰手腕?拆解REDSearcher的三段式训练框架
论文标题:REDSearcher: A Scalable and Cost-Efficient Framework for Long-Horizon Search Agents
论文地址:https://arxiv.org/abs/2602.14234
作者:Zheng Chu, Xiao Wang, Jack Hong, Huiming Fan, Yuqi Huang, Yue Yang, Guohai Xu, Chenxiao Zhao, Cheng Xiang, Shengchao Hu, Dongdong Kuang, Ming Liu, Bing Qin, Xing Yu
日期:2026年2月
🎯 一句话总结
REDSearcher用图论度量驱动的任务合成 + 两阶段中训练 + 模拟环境强化学习三板斧,把一个30B参数(仅3B激活)的MoE模型训练成了深度搜索代理,在BrowseComp上拿到42.1%(带上下文管理达57.4%),GAIA上80.1%,整体性能在开源同级别模型中排第一。
📖 这篇论文在解决什么问题?
OpenAI的Deep Research、Google的Gemini Deep Research——这类深度搜索代理是2025年以来AI领域最热的方向。用户扔过来一个复杂问题,AI代理自己去互联网上搜索、浏览、推理,最后交出一份详尽报告。
听起来很酷,做起来很难。难在哪里?
数据从哪来? 复杂的多跳搜索任务没有现成的大规模数据集。让人去互联网上一步步搜索、记录每步操作再标注——这个成本高得离谱。
能力怎么注入? 一个预训练语言模型不会搜索。它需要学会理解搜索结果、规划搜索策略、在超长上下文中保持推理连贯、正确调用各种工具。这些能力怎么系统性地灌进去?
RL训练怎么做? 强化学习(RL)是提升代理能力的关键,但代理RL有个致命问题——每次rollout都要和真实搜索引擎交互,API调用费用会快速膨胀。
REDSearcher针对这三个瓶颈,分别给出了对应方案。
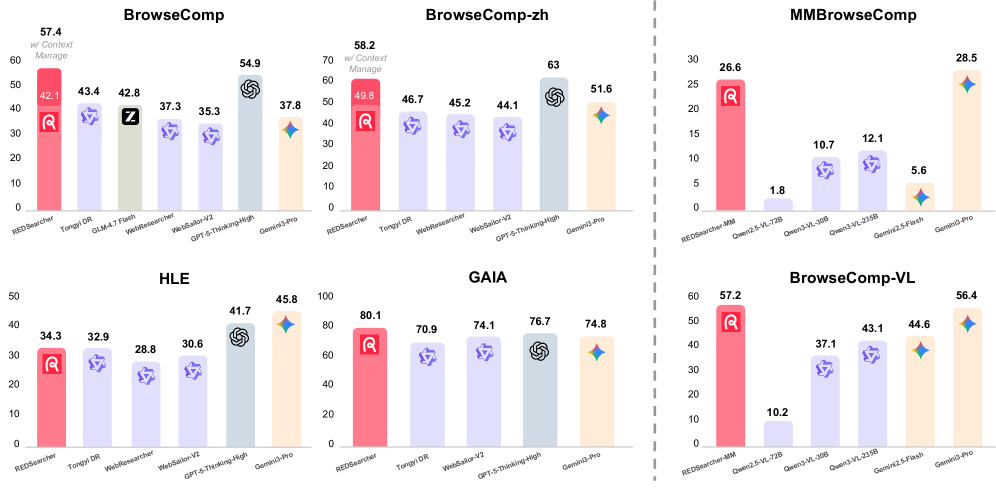
图1:REDSearcher与闭源和开源搜索代理在多个基准上的性能对比。30B-A3B规模下,REDSearcher在GAIA上超过了GPT-5-Thinking-high
🧠 核心方法:三段式训练框架
REDSearcher的框架由三部分组成:任务合成(解决"训练什么")、中训练(解决"怎么从零开始")、后训练(解决"怎么进一步提升上限")。
一、用图论量化搜索难度——双约束任务合成
以往生成多跳问题的做法是从知识图谱采样实体和关系,用模板或LLM生成问题。问题是:生成的任务结构单一,多数是线性的"链式"推理(A→B→C→D),难以精确控制难度,而且答案可能直接存在于LLM的参数知识中——根本不需要搜索。
REDSearcher的思路很不一样:把一个多跳搜索任务建模为约束图(constraint graph),用两个图论指标来量化和控制复杂度。
维度一:树宽(Treewidth)——推理拓扑有多复杂
树宽是图论中的经典概念。打个比方:如果推理路径是一条直线(链式),树宽为1,就像走一条笔直的走廊;如果推理路径出现了环,树宽为2,就像走进了一个有多个岔路口的迷宫;树宽更高意味着迷宫更复杂,死胡同和交叉通道更多。
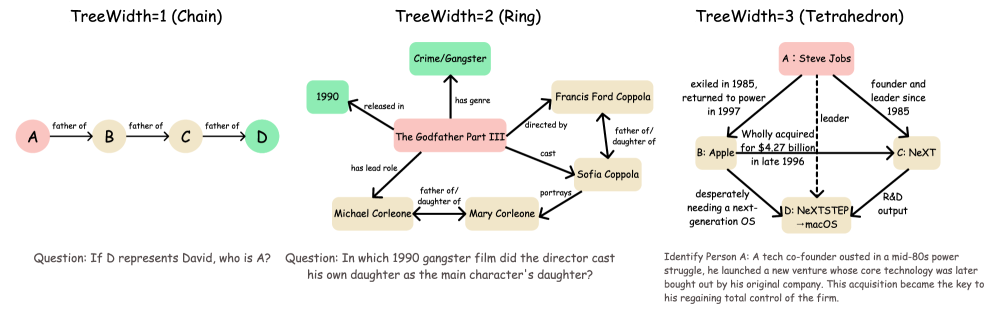
图2:不同树宽k值对应的约束图拓扑。k=1是链式推理,k=2出现环形约束,k≥3是高维耦合结构
具体来说: - k=1(链式):最简单的多跳问题。"A的导师是B,B在哪所大学?"——推理路径是一条直线,求解复杂度 \(O(N \cdot d^2)\) - k=2(环形):推理路径中出现环。一个问题需要同时满足两个独立约束,而它们又通过第三个事实相互关联,复杂度 \(O(N \cdot d^3)\) - k≥3(高阶):多个约束之间密集交叉依赖,复杂度 \(O(N \cdot d^4)\)
论文举了个k=2的例子:"2017年环法自行车赛第18赛段的冠军,也赢得了哪一年的巴黎-鲁贝赛?"这个问题的约束图包含赛事、年份、赛段、结果等节点和它们之间的关系边——你不能沿一条链走下去,需要同时满足多个交叉约束。
维度二:最小源分散度(MSD)——信息获取有多难
光有复杂的推理结构还不够。如果所有答案线索都集中在同一个网页上,即使推理结构复杂,搜索也可能很简单——找到那个网页就完了。
MSD衡量的是:回答这个问题所需的证据,至少分散在多少个不同的信息源中。MSD=5意味着代理至少要访问5个不同的网页才能凑齐答案——搜索过程自然更长、更有挑战性。
合成流水线
两个指标就位后,生成管道的逻辑就很清晰了:
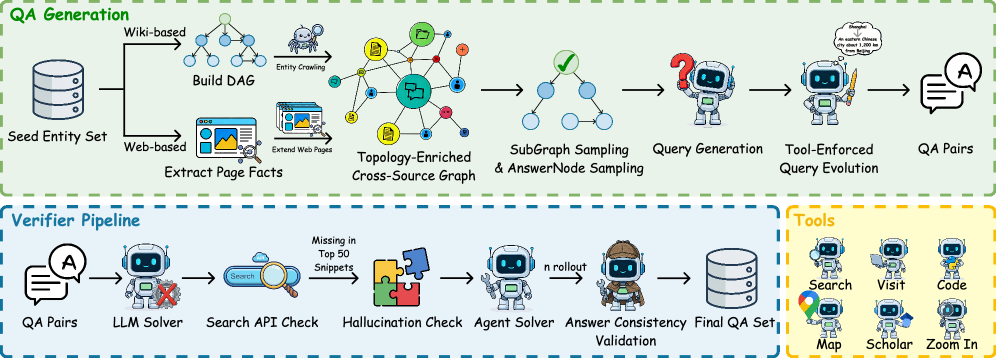
图3:REDSearcher的任务合成管道——从种子实体采样到最终验证的完整流程
- 种子实体采样:从Wikidata和Wikipedia中采样,通过长度、结构、元数据过滤
- 约束图构建与拓扑丰富:围绕种子实体,结合结构化关系和超链接,用LLM Agent引入环路以增加复杂度
- 高效子图采样:采用"一图多任务"策略,从主图中提取多个独立子图
- 问题生成:基于子图和目标节点生成自然语言问题和参考答案
- MSD过滤:过滤掉信息过于集中的简单问题
- 验证管道:包含LLM求解器预过滤、可检索性检查、幻觉/一致性检查、智能体滚动验证和答案唯一性检查
有个细节特别巧妙:工具强制查询改写(Tool-Enforced Query Evolution)。为了生成真正需要使用地图、路线规划等工具的问题,他们把问题中的显式实体名替换成操作性约束。比如把"从巴黎到伦敦"改写成"从埃菲尔铁塔所在城市到大本钟所在城市"——代理就必须先搜索确认城市名,再调用地图工具,而不是直接输入已知城市名。
这套方法最大的好处是可扩展:调节目标树宽k和目标MSD值,就能自动生成从简单到极难的任务梯度,不需要人工标注。最终产出了10K高质量复杂文本搜索轨迹和5K多模态轨迹。
二、从基座模型到搜索代理——两阶段中训练
有了训练数据,怎么把一个通用预训练模型系统性地转化为搜索代理?
直接在基座模型上做SFT或RL,效果很差。原因很直观——搜索代理需要的底层能力(超长上下文理解、搜索结果解析、工具调用格式、多步规划)在基座模型中要么缺失要么很弱。如果一股脑把所有能力混在一起训练,不同能力之间还会相互干扰。
REDSearcher的方案是两阶段中训练(Mid-training),"先学会想,再学会做"。

图4:REDSearcher的完整训练流水线——从基座模型到最终搜索代理的全流程
Phase I:内部认知优化(32K上下文,~90B tokens)
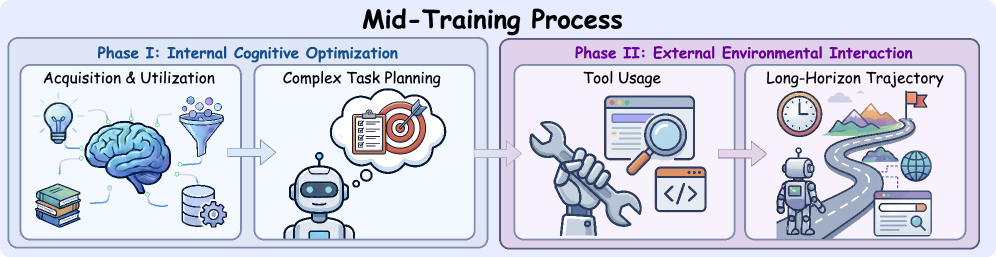
图5:两阶段中训练的数据构成和训练目标
这个阶段不涉及任何工具调用和环境交互,纯粹训练模型的"内功"。
(1)基于意图的锚定(Intent-based Anchoring)——解决"能不能从搜索结果中准确提取信息"的问题: - 在噪声环境中提取关键信息 - 训练模型理解HTML结构、表格、列表等网页元素 - 在超长网页内容中定位关键段落
(2)分层规划(Hierarchical Planning)——解决"能不能把复杂问题拆成可执行的搜索步骤"的问题: - 将复杂目标分解为具体子目标和模糊子目标 - 为每个子问题制定搜索查询策略 - 当某一步搜索失败时,学会调整策略
选择32K上下文是有考量的——内部认知任务不需要超长上下文(不涉及多轮交互的长轨迹),32K已经够用,训练效率更高。
Phase II:外部环境交互(128K上下文,~10B tokens)
这个阶段的训练数据来自真实或模拟的搜索交互轨迹,让模型学会"和外界打交道"。
(1)智能体工具使用——掌握Search(搜索查询)、Visit(访问网页URL)等基础工具的调用格式,在模拟环境(基于Wiki和Web Crawl构建)中生成大规模工具交互数据。
(2)长时程轨迹处理——在多达数十轮的搜索-浏览-推理循环中保持目标一致性。当交互历史超过上下文限制时,采用"Discard-all"策略丢弃早期历史,保留系统提示和最近的交互。
128K上下文是必须的——每一轮搜索返回结果加上推理过程,可能消耗数千token,十几轮下来轻松突破32K。
Phase I的90B tokens远大于Phase II的10B tokens,这个配比本身就很有信息量:内部认知能力需要大量数据打底,而工具使用等外部技能相对容易通过少量数据学会——前提是认知基础已经打好。就像一个人,先得学会思考和阅读理解,再去学怎么用搜索引擎,顺序反了效果就差。
三、本地模拟环境与代理强化学习
代理RL有个绕不过去的成本难题:每次策略更新都需要大量rollout,每次rollout都要与环境交互。如果用真实搜索引擎API,费用极其高昂。
功能等价的本地模拟搜索环境
REDSearcher构建了一个包含数千万篇文档的本地模拟环境,能够模拟: - 搜索查询:接收查询字符串,返回相关文档片段的排序列表 - 网页访问:接收URL,返回对应文档内容
有个关键设计——URL混淆。真实搜索中,URL本身往往携带大量信息(比如 wikipedia.org/wiki/Albert_Einstein 直接告诉你这是关于爱因斯坦的维基百科页面)。如果保留真实URL,模型可能学会"走捷径"——通过URL猜测内容而不是真正学习搜索策略。REDSearcher对URL做了混淆处理,堵住了这条捷径。
模拟环境的优势: - 速度:本地检索比外部API快几个数量级 - 成本:没有API调用费用 - 可控性:精确控制文档库的内容和范围 - 可复现:相同查询永远返回相同结果,有利于RL训练稳定性
后训练流水线:SFT → RL
第一步:Agentic SFT——在真实世界环境(使用Search、Visit、Python、Google Scholar、Google Maps等工具)中合成的高质量专家轨迹上进行微调,最大上下文128K。SFT的主要作用是让模型学会正确的输出格式和基本搜索行为模式。
第二步:Agentic RL——使用GRPO(Group Relative Policy Optimization)算法。GRPO来自DeepSeek-R1,核心思想是对同一问题采样一组回答,用组内相对奖励来更新策略,不需要额外训练critic模型。这种做法降低了训练不稳定性,也省掉了价值函数近似的开销。
奖励信号来自最终答案的正确性——二元的{0,1}奖励。信号非常稀疏(只在轨迹末尾有一次反馈),但GRPO通过组内对比有效利用了这个信号。具体配置:Mini-batch 512,学习率 \(1 \times 10^{-6}\),Clip high设为0.28。
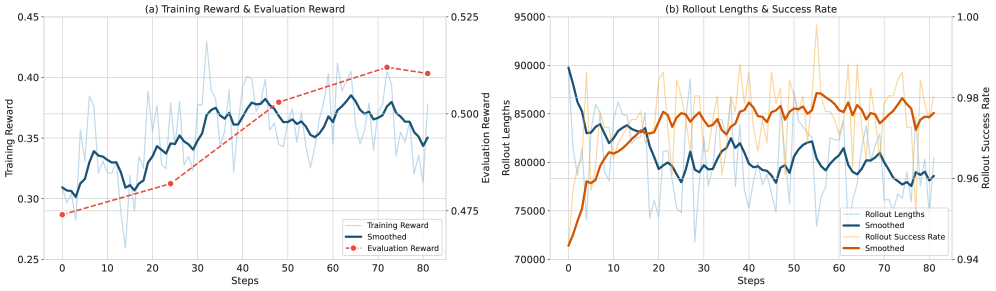
图6:RL训练曲线——训练奖励和评估奖励持续上升,平均工具调用次数从100.6降至90.1(减少10.4%),说明模型学会了更高效的搜索策略
从训练曲线可以看到:平均评估奖励从47.4提升至51.3(+3.9),BrowseComp分数从39.4提升至42.1(+2.7)。关键的是——RL训练完全在模拟环境中进行,但最终评估是在真实互联网搜索环境中完成的。模拟→真实的迁移是成功的。
🧪 实验结果
主要结果:30B参数模型的越级表现
REDSearcher基于Qwen3-30B-A3B(MoE架构,30B总参数、仅3B激活参数),在多个基准上展现了极具竞争力的性能:
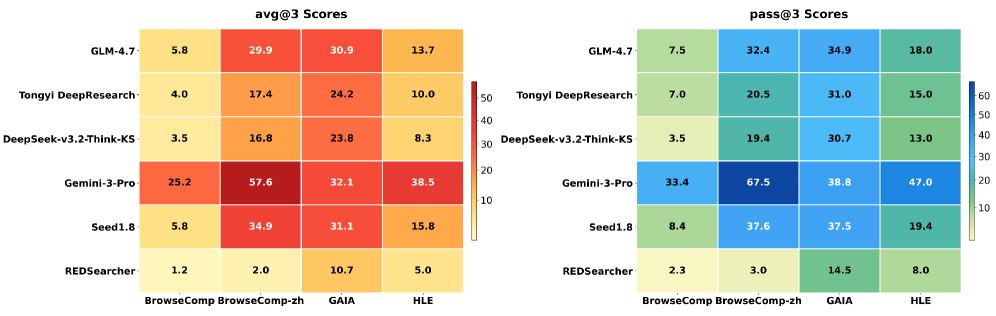
图7:文本搜索基准上的综合对比结果
| 模型 | 参数规模 | BrowseComp | BrowseComp-ZH | GAIA | HLE | Overall |
|---|---|---|---|---|---|---|
| Seed1.8 | 闭源 | 67.6 | 81.3 | 87.4 | 40.9 | 69.3 |
| GPT-5-Thinking-high | 闭源 | 54.9 | 63.0 | 76.7 | 41.7 | 59.1 |
| OpenAI-o3 | 闭源 | 49.7 | 58.1 | 70.5 | 20.2 | 49.6 |
| Gemini-3-Pro | 闭源 | 37.8 | 51.6 | 74.8 | 45.8 | 52.5 |
| Kimi-K2.5-Agent | 1T-A32B | 60.6/74.9* | - | - | 50.2 | - |
| DeepSeek-V3.2 | 671B-A37B | 51.4/67.6* | -/65.0* | - | 40.8 | - |
| GLM-4.7 | 355B-A32B | 52.0/66.6* | -/67.5* | - | 42.8 | - |
| Tongyi DeepResearch-30B | 30B-A3B | 43.4 | 46.7 | 70.9 | 32.9 | 48.5 |
| WebSailorV2-30B | 30B-A3B | 35.3 | 44.1 | 74.1 | 30.6 | 46.0 |
| REDSearcher | 30B-A3B | 42.1/57.4* | 49.8/58.2* | 80.1 | 34.3 | 51.6 |
(*表示使用了上下文管理技术)
几组数据值得关注:
-
GAIA上的80.1%——这个分数超过了GPT-5-Thinking-high(76.7%),也超过了所有其他开源30B模型。在通用AI助手这个维度上,REDSearcher的搜索能力转化为了实打实的任务解决能力。
-
BrowseComp上的57.4%(带上下文管理)——这是个很"吃搜索策略"的基准,OpenAI专门设计来测试"答案存在于互联网上但极难直接搜到"的问题。GPT-4o配搜索工具准确率只有个位数。REDSearcher在30B-A3B规模下打到了这个水平,考虑到它每次推理只激活3B参数,性价比非常高。
-
和更大模型的差距在缩小——虽然Kimi-K2.5-Agent(1T-A32B)和GLM-4.7(355B-A32B)在BrowseComp上带上下文管理后能到70%+,但它们的参数量是REDSearcher的10倍以上。REDSearcher用十分之一的规模做到了它们七八成的水平。
消融实验:每个模块都不能少
中训练各阶段的逐步影响:
| 配置 | BrowseComp | BrowseComp-ZH | HLE | GAIA | 平均 |
|---|---|---|---|---|---|
| Base(无中训练) | 34.74 | 26.82 | 32.25 | 77.43 | 42.81 |
| +Phase I: 锚定 | 36.61 | 27.34 | 32.00 | 76.70 | 43.16 |
| +Phase I: 锚定+规划 | 36.97 | 29.84 | 31.37 | 80.83 | 44.75 |
| +Phase I+II(完整中训练) | 40.44 | 38.75 | 31.25 | 79.13 | 47.39 |
几个关键发现:
- Phase I的规划训练让GAIA从76.70提升到80.83(+4.13),说明分层规划对复杂推理任务的帮助很大
- Phase II(交互训练)让BrowseComp-ZH从29.84跃升至38.75(+8.91),交互反馈对中文搜索场景的提升尤为显著
- 完整中训练把平均分从42.81拉到47.39,提升了4.58个绝对点
如果把Phase I和Phase II的数据混在一起训练(而非先后两阶段),效果会下降——验证了"先内后外"的最优顺序。
上下文管理:Discard-all策略的效果
论文采用了一种名为Discard-all的上下文管理策略:当交互上下文超过预设阈值时,丢弃所有历史工具调用记录,只保留原始问题和系统提示。
| 模型 | 不使用策略 | 使用Discard-all |
|---|---|---|
| BrowseComp | 42.1 | 57.4(+15.3) |
| BrowseComp-ZH | 49.8 | 58.2(+8.4) |
BrowseComp上直接提升了15.3个绝对点,效果非常显著。这个结果初看反直觉——丢掉历史不会丢失重要信息吗?实际上,经过中训练的模型已经学会在推理过程中把关键信息"内化"到当前思考中,不需要回溯原始历史。丢弃旧历史反而减少了噪声干扰,而且每次上下文重置后模型有完整的窗口可用,能处理更长的搜索结果。
涌现行为的量化分析
这是论文中最有趣的部分之一。
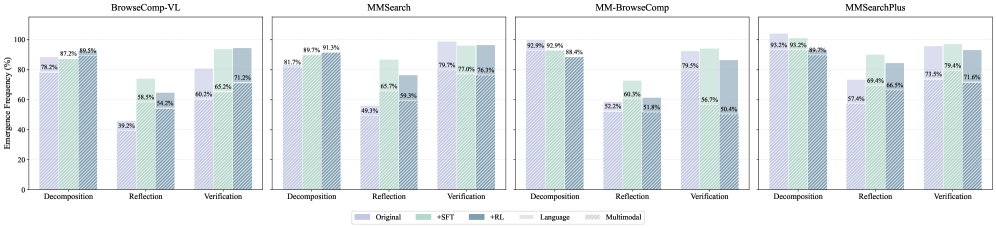
图8:分解、反思、验证三种搜索行为在不同训练阶段的频率变化
论文定义了三种关键搜索行为: - 分解(Decomposition):主动将复杂问题拆分为子问题 - 反思(Reflection):搜索过程中回顾已有信息,发现不足或矛盾,调整策略 - 验证(Verification):给出答案前通过额外搜索交叉验证
量化结果显示了清晰的递进趋势:基座模型上三种行为出现频率都很低;SFT后分解行为显著增加;RL后三种行为的频率都大幅跃升。
验证行为的涌现特别值得关注——这种行为在SFT数据中可能并不多见,但RL训练"自发地"让模型学会了答题前做额外确认。因为GRPO的奖励信号(最终答案正确性)间接鼓励了这种谨慎策略:验证过的答案更可能是对的。
正确 vs 错误轨迹的行为差异
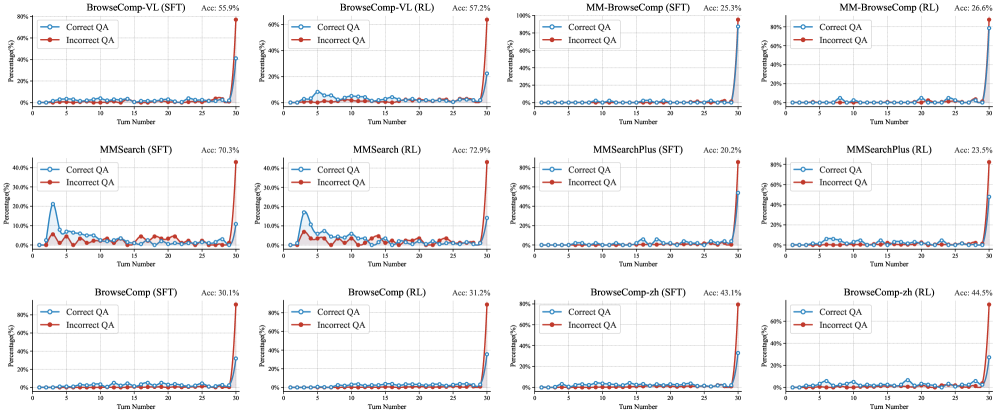
图9:SFT和RL模型中,正确/错误回答对应的搜索轮次分布对比
- SFT模型中,正确和错误回答的搜索轮次分布差异不大——模型还没学会"该搜多深就搜多深"
- RL模型中,正确答案往往对应更多搜索轮次——学会了"不轻易放弃"
- 同时,RL模型在简单问题上会更快给出答案——也学会了"够了就停"
这种"知道什么时候该深挖、什么时候该收手"的元技能,是长时程搜索代理最关键的能力之一。
工具使用与参数知识的解耦
论文对比了"无工具"和"有工具"两种模式。REDSearcher在无工具模式下得分最低——说明它较少依赖参数记忆或基准测试重叠。启用工具后性能大幅提升,且提升幅度(Gap)大于大多数基线模型。这证明REDSearcher真正学会了用工具找信息,而不是靠"背答案"。
🔬 多模态搜索的扩展
REDSearcher还扩展到了多模态搜索,基于Qwen3-VL-30B-A3B-Thinking构建。
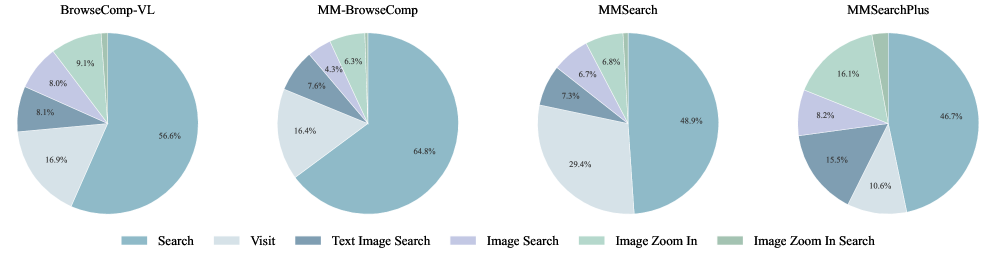
图10:不同多模态基准上的工具使用分布——模型会根据任务特点灵活选择工具
多模态版本增加了四种视觉工具:Image Search、Image Zoom In、Text Image Search、Image Zoom In Search。
| 模型 | 参数 | MM-BrowseComp | BrowseComp-VL | MMSearch | LiveVQA |
|---|---|---|---|---|---|
| Gemini-2.5-Pro | 闭源 | 7.1 | 49.9 | 69.0 | 76.0 |
| GPT-5 | 闭源 | - | 46.1 | 63.7 | 73.3 |
| Gemini-3-Pro | 闭源 | 28.5 | 56.4 | 73.0 | 79.9 |
| Vision-DeepResearch | 30B | - | 53.7 | 69.6 | 77.6 |
| REDSearcher-MM-RL | 30B | 23.5 | 57.2 | 72.9 | 79.3 |
在BrowseComp-VL上57.2%,超过了GPT-5(46.1%)和Gemini-2.5-Pro(49.9%)。在MMSearch和LiveVQA上也接近或超过了Gemini-3-Pro。30B参数的多模态搜索代理做到这个水平,相当不错。
💡 我的思考
框架的核心价值不只是数字
REDSearcher最有价值的不是最终的分数,而是它提出了一套完整的、模块化的深度搜索代理训练框架:
- 任务合成模块可以独立使用——你可以用它的双约束方法生成数据,但用不同的训练策略
- 中训练方案给出了从基座模型到搜索代理的清晰路径——Phase I建认知,Phase II建交互
- 模拟环境+GRPO组合让大规模代理RL在可控成本下成为可能
这三部分之间是解耦的。比如你可以用REDSearcher的模拟环境训练方案,但把GRPO换成其他RL算法。这种模块化设计对后续研究很有参考价值。
MoE架构在代理场景的适配性
选择Qwen3-30B-A3B(30B总参数、3B激活参数)作为基座,暗示MoE架构可能特别适合代理场景——代理任务需要广泛的知识(大总参数量),但每次推理的计算成本需要可控(小激活参数量)。在长时程交互中,每一步都需要推理,累积的计算量不容忽视,MoE的低激活特性就成了优势。
合成数据+模拟环境:代理训练的通用范式?
这可能是未来训练各类AI代理的通用思路。真实环境交互成本太高、数据太稀缺,但高质量的合成数据和功能等价的模拟环境可以在可控成本下实现大规模训练。这个思路不限于搜索代理——代码编写代理、数据分析代理也适用。
局限性
- 模拟环境是静态的,无法覆盖实时更新的网络内容。面对训练时不存在的全新网页,迁移效果需要更多验证
- 奖励信号过于稀疏——完全基于最终答案正确性的{0,1}奖励。对于开放性任务(比如撰写研究报告),怎么定义奖励函数是个开放问题
- 规模泛化性未知——论文只用了Qwen3-30B-A3B,在更大或更小的模型上效果如何,还没有实验验证
📝 总结
深度搜索代理的竞赛才刚开始。REDSearcher给出了一个设计精良的三段式方案:"图论度量驱动的任务合成"解决数据问题,"认知优先、交互在后的两阶段中训练"解决冷启动问题,"模拟环境+GRPO"解决RL成本问题。用30B-A3B规模做到了GAIA 80.1%、BrowseComp 57.4%(带上下文管理),在开源同级别模型中排第一。
后续工作的方向可能包括:更大的基座模型、动态更新的模拟环境、更精细的过程奖励(而非只看最终答案)。但REDSearcher确立的这个"任务合成-中训练-模拟环境RL"三段式框架,很可能成为这个领域的标准范式之一。