Nanbeige4.1-3B:3B 参数的"六边形战士"是怎么炼成的
📖 论文标题:Nanbeige4.1-3B: A Small General Model that Reasons, Aligns, and Acts
🔗 论文链接:https://arxiv.org/abs/2602.13367
👥 作者:Nanbeige LLM Lab / Boss Zhipin(BOSS 直聘)
📅 发表时间:2026年2月
🎯 一句话总结
Nanbeige4.1-3B 用一套精心编排的"SFT → 逐点 RL → 成对 RL → 代码 RL → 智能体 RL"训练流水线,把一个 3B 参数的小模型打造成了数学、代码、对齐、工具调用、深度搜索全面开花的通用选手——在多项基准上追平甚至超越了 10 倍参数量的 Qwen3-32B。
🤔 为什么需要这篇论文?
小模型的尴尬处境
大模型能力强但部署贵、推理慢,这个矛盾在端侧场景(手机、IoT、边缘设备)和高并发服务场景里尤其突出。3B 级别的小模型是业界公认的"甜蜜点"——推理速度快、显存占用小、可以跑在消费级 GPU 上。
问题是,3B 模型的能力上限到底在哪?
过去一年的实践表明,小模型在单项能力上能做到不错(比如专门练代码、专门练数学),但同时兼顾推理、对齐、代码生成和工具调用?这几乎是天方夜谭。代码练多了对齐能力下降,对齐做狠了推理能力退化——这就是所谓的"能力冲突"问题。
Nanbeige 的回答:不是能力不够,是训练流程不够精细
BOSS 直聘旗下的南北阁(Nanbeige)大模型实验室给出了一个令人信服的答案:3B 模型完全可以同时做好这些事,关键在于训练流程的设计。他们提出了一套多阶段、多目标的 RL 训练方案,每个阶段解决一个特定问题,像搭积木一样逐步构建综合能力。
这个思路的核心哲学是——与其训一个什么都会但什么都不精的模型,不如分阶段让模型先学会一件事、再学第二件事,同时保证前面学的不被冲掉。
🏗️ 方法全景:五步炼成"六边形战士"

Nanbeige4.1-3B 的完整训练流水线可以概括为五个阶段:
每个阶段有明确的优化目标,互相之间不打架。下面逐一拆解。
🧠 阶段一:SFT——打好地基
数据工程比模型架构更重要
SFT(Supervised Fine-Tuning)阶段看似平淡无奇,但 Nanbeige 在数据层面做了三件关键的事:
1. 上下文窗口从 64K 拉到 256K
为什么要这么长?因为后续的深度搜索(Deep Search)任务需要处理长达 600 轮的工具调用交互——这些对话展开后轻松超过 100K token。如果在 SFT 阶段不把长上下文能力练好,后面的 RL 阶段根本无法收敛。
2. 加大代码数据配比
相比上一版 Nanbeige4-3B-2511,代码数据占比明显提高。同时引入了更多数学和通用领域的高难度题目。这是一种"先喂猛料、再用 RL 精调"的策略——SFT 负责把知识装进去,RL 负责教模型怎么用好这些知识。
3. 批评-修订循环(Critic-Revision Loop)
传统的 CoT(Chain-of-Thought)数据蒸馏是:用强模型生成一遍推理过程就完事。Nanbeige 多加了一步——生成后让另一个 critic 模型挑毛病,再让原模型修改,如此迭代多轮。最终得到的推理轨迹质量更高、逻辑更严谨。
这就像学生写作文,老师改一遍、学生改一遍、老师再改一遍——反复磨出来的作文和一稿定型的差距是很大的。
🔧 阶段二:Point-wise RL——消除"坏毛病"
SFT 之后的模型有个通病:格式不稳定、爱重复啰嗦、推理中间夹杂无关内容。这些问题在小模型上尤为严重。
Point-wise RL 的目标很明确:用通用奖励模型给输出打分,把格式错误和冗余推理惩罚掉。
具体做法
- 在人类偏好数据上训练一个通用 Reward Model
- 用 GRPO(Group Relative Policy Optimization)算法优化策略模型
- 每个 prompt 采样 8 个 rollout,计算组内相对优势
GRPO 是 DeepSeek 提出的一种 RL 算法,核心思想是:不需要单独训练一个 value network,而是在每组采样内做相对排名——"你比同组平均水平好多少"就是你的优势信号。这种方式计算开销更小,特别适合大规模 RL 训练。
用个比喻来理解:传统 PPO 像每场考试都有一个固定的评分标准(value function),而 GRPO 像是"班级排名制"——你的优势不看绝对分数,看你在这批同学里排第几。
Point-wise RL 之后,模型的格式错误率大幅下降,推理过程也更加简洁。但还有一个问题没解决——输出风格是不是人类喜欢的?这需要下一阶段来处理。
🎯 阶段三:Pair-wise RL——对齐到人类偏好
从"对不对"到"好不好"
Point-wise RL 解决了"输出格式对不对"的问题,但"回答好不好"是一个更微妙的判断。同一个问题可以有多种正确回答,哪种更受用户欢迎?这需要成对比较。
Pair-wise RL 的核心创新在于成对奖励模型(Pairwise Reward Model)的训练方式:
- 数据来源:用强模型(如 GPT-4 级别)和弱模型(如未经 RL 的基座模型)同时回答相同问题,构成"强-弱模型对"
- 比较标注:裁判模型对两个回答做 A vs B 的偏好判断
- 交换一致性正则化(Swap-Consistency Regularization):关键设计——把 A 和 B 的展示顺序对调后再判一次,要求两次判断一致
为什么需要交换一致性?因为成对比较中有一个臭名昭著的偏差——位置偏差(Position Bias)。LLM 做裁判时,往往倾向于选择排在前面的回答。Swap-Consistency 通过强制"正反都判对"来缓解这个问题。
效果
Pair-wise RL 之后,Arena-Hard-V2(衡量对齐质量的核心指标)从 60.0 提升到 73.2,Multi-Challenge 从 41.20 提升到 52.21。这个提升幅度在 3B 模型上是非常惊人的。
💻 阶段四:Code RL——不只要对,还要快
这是我觉得整篇论文最精彩的部分。
代码 RL 的两难困境
传统的代码 RL 只看"代码能不能跑通测试用例"——通过了给正奖励,没通过给零分。这种粗暴的方式有一个问题:模型可能学会用暴力枚举或极低效的算法来"骗过"测试用例。
举个例子:让模型解一道排序题,暴力冒泡 \(O(n^2)\) 和归并排序 \(O(n \log n)\) 都能通过小规模测试,但上了大数据量就天差地别。如果 reward 只看 pass/fail,模型根本没有动力去学更优的算法。
两阶段设计:先求对、再求快

图3:代码 RL 的裁判系统架构。模型生成代码后,先经过多语言沙箱检查正确性,再由专门的指令模型评估时间复杂度。两个信号共同构成最终奖励。
Stage 1:优化正确性(Correctness Reward)
这个阶段的目标就是让模型学会写出能跑通的代码。奖励是 pass rate——通过了 8 个测试中的 6 个,奖励就是 0.75。
Stage 2:引入门控复杂度奖励(Gated Time-Complexity Reward)
关键词是门控(gated)——只有当代码全部通过测试用例时,时间复杂度奖励才会生效。如果代码连正确性都保证不了,根本不看复杂度。
这个设计很克制,也很聪明。想象一下如果两个奖励同时打开会怎样?模型可能为了追求低复杂度而牺牲正确性——"我写了一个 \(O(1)\) 的算法,虽然答案不对但复杂度很棒!"。门控机制确保正确性永远是第一优先级。
裁判系统的设计
怎么评估时间复杂度?这不是一个容易自动化的任务。Nanbeige 设计了一个混合裁判系统:
- 多语言沙箱(Sandbox):执行代码、跑测试用例、收集运行结果——负责正确性判断
- 专用指令模型(Instruction Model):分析代码逻辑、估算时间复杂度——负责效率判断
把两个判断合在一起就是最终的 reward 信号。

图4:两阶段代码 RL 的训练动态。蓝色曲线是 LiveCodeBench-v6 得分,橙色是正确性奖励 \(R_{\text{correctness}}\),绿色是时间复杂度奖励 \(R_{\text{time}}\)。可以看到 Stage 1 阶段正确性快速上升,Stage 2 切入后复杂度奖励开始攀升,同时正确性保持稳定。
从训练曲线可以清晰看到分阶段设计的效果:Stage 1 把正确性拉高到一个平台期之后,Stage 2 在不损害正确性的前提下把代码效率进一步提升。最终 LiveCodeBench-v6 得分从 46.0(上一版 Nanbeige4-3B)飙升到 76.9。
🌐 阶段五:Deep Search RL——600 轮工具调用的耐力赛
什么是 Deep Search?
Deep Search 是指模型作为智能体,通过多轮工具调用(搜索引擎、数据库、API)来完成复杂的信息检索和推理任务。这不是简单的"搜一下就回答",而是"搜了 → 分析 → 发现信息不够 → 追问 → 再搜 → 综合 → 回答"的长链路过程。
对于 3B 的小模型来说,在长达几百轮的交互中保持逻辑一致性和目标追踪能力,是一个巨大的挑战。
数据构建:Wiki-Graph 随机游走
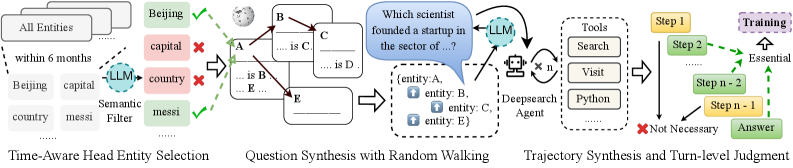
图2:深度搜索数据构建的三步流程。(1) 时间感知的头实体选择:从 Wikipedia 知识图谱中选取具有时效性的实体;(2) 随机游走生成问题:沿实体关系链随机游走,在路径上构造多跳问答对;(3) 轨迹合成与回合级判断:生成完整的搜索轨迹,并对每一轮交互做逻辑、工具调用准确性和信息增益的细粒度评判。
这个数据构建流水线的设计很有意思:
Step 1:时间感知的头实体选择
不是从 Wikipedia 随便选实体,而是挑那些有时效性信息的实体——比如"某公司2025年的收入"。这保证了问题的难度和现实感。
Step 2:随机游走构造多跳问题
在 Wikipedia 的实体关系图上做随机游走:从实体 A 走到 B,从 B 走到 C,然后问一个需要同时知道 A、B、C 信息才能回答的问题。游走路径越长,问题的推理跳数就越多。
这和 HotpotQA 等传统多跳数据集的构造思路类似,但 Nanbeige 直接用图结构来控制跳数和难度分布,更加可控。
Step 3:轨迹合成 + 回合级判断
给模型一个问题和搜索工具,让它自己跑完整个搜索过程,生成轨迹。关键创新在于回合级判断(Turn-level Judgment)——不是等跑完了看最终答案对不对,而是对每一轮交互都评估三个维度:
- 逻辑性:这一步的搜索策略合理吗?
- 工具调用准确性:搜索 query 写得对吗?
- 信息增益:这次搜索带来了多少新信息?
只有在每一轮都通过审核的轨迹才会被保留为训练数据。这种精细化过滤确保了训练数据的高质量,模型不会学到"乱搜一通碰巧答对"的走捷径行为。
训练结果
深度搜索能力的提升是最令人震撼的。在 GAIA(text-only)基准上,Nanbeige4.1-3B 拿到 69.90 分,而 Qwen3-4B 只有 28.33 分——差距接近 2.5 倍。更夸张的是,这个分数甚至超过了 DeepSeek-V3.2(671B 参数)的 63.50 分。
一个 3B 的小模型在智能体任务上打败了 671B 的大模型?这听起来不太真实,但如果仔细想想,Agent 任务的瓶颈往往不在模型的参数量上,而在于是否能稳定地做多轮规划和工具调用。只要训练数据足够好、RL 信号足够精细,小模型完全有可能在这类任务上发挥出色。
🧪 实验结果:全面碾压同级,叫板十倍大模型
通用任务基准

图5:Nanbeige4.1-3B 与 Qwen3 系列模型在六大领域的性能对比。蓝色为 Qwen3-4B,绿色为 Qwen3-8B,黄色为 Qwen3-32B,红色为 Nanbeige4.1-3B。在代码和对齐领域,3B 模型全面超越 32B 模型。
| 领域 | 基准 | Qwen3-4B | Qwen3-32B | Nanbeige4-3B (上一版) | Nanbeige4.1-3B |
|---|---|---|---|---|---|
| 代码 | LCB-V6 | 57.4 | 55.7 | 46.0 | 76.9 |
| 代码 | LCB-Pro-Easy | 40.2 | 42.3 | 40.2 | 81.4 |
| 代码 | LCB-Pro-Medium | 5.3 | 3.5 | 5.3 | 28.1 |
| 数学 | AIME 2026 I | 81.46 | 75.83 | 84.10 | 87.40 |
| 数学 | HMMT Nov | 68.33 | 57.08 | 66.67 | 77.92 |
| 数学 | IMO-Answer-Bench | 48.00 | 43.94 | 38.25 | 53.38 |
| 科学 | GPQA | 65.8 | 68.4 | 82.2 | 83.8 |
| 科学 | HLE (Text-only) | 6.72 | 9.31 | 10.98 | 12.60 |
| 对齐 | Arena-Hard-V2 | 34.9 | 56.0 | 60.0 | 73.2 |
| 对齐 | Multi-Challenge | 41.14 | 38.72 | 41.20 | 52.21 |
| 工具 | BFCL-V4 | 44.87 | 47.90 | 53.80 | 56.50 |
| 工具 | Tau2-Bench | 45.90 | 45.26 | 41.77 | 48.57 |
几组数据值得特别关注:
代码:碾压级优势。 LCB-V6 从 46.0 飙到 76.9,涨了 30.9 个点。LCB-Pro-Medium 从 5.3 到 28.1——这意味着模型从"基本做不出中等难度竞赛题"变成了"能解决接近三成"。这个提升背后就是两阶段 Code RL 的功劳。
对齐:超越 32B。 Arena-Hard-V2 上 73.2 vs Qwen3-32B 的 56.0——一个 3B 模型在对齐质量上碾压 32B 模型?这说明 Pair-wise RL 的效果是实打实的。模型参数量不决定输出质量的上限,训练方法才决定。
数学:稳步提升。 AIME 2026 I 上 87.40 分,意味着这个 3B 模型能解出大约 87% 的 AIME 竞赛题。这在两年前是不可想象的。
深度搜索基准
| 基准 | Qwen3-4B | Qwen3-8B | DeepSeek-V3.2 (671B) | Nanbeige4-3B | Nanbeige4.1-3B |
|---|---|---|---|---|---|
| GAIA (text-only) | 28.33 | 19.53 | 63.50 | 19.42 | 69.90 |
| Browse Comp | 1.57 | 0.79 | 67.60 | 0.79 | 19.12 |
| SEAL-0 | 15.74 | 6.34 | 38.50 | 12.61 | 41.44 |
| xBench DeepSearch-05 | 34.00 | 31.00 | 71.00 | 33.00 | 75.00 |
GAIA 上 69.90 分 vs DeepSeek-V3.2 的 63.50 分——3B 小模型赢了 671B 大模型 6.4 个点。xBench DeepSearch 上 75.00 vs 71.00,同样胜出。
这组数据传递了一个非常重要的信号:智能体能力和模型参数量的关系,远没有我们以为的那么线性。精心设计的训练数据和 RL 信号,可以让小模型在需要"做事"(而非"背知识")的任务上超越大模型。
当然也要看到,Browse Comp 上 Nanbeige4.1-3B 只有 19.12,而 DeepSeek-V3.2 有 67.60——这个差距说明在需要大量世界知识和浏览理解能力的任务上,参数量的优势仍然不可替代。
LeetCode 周赛:实战检验
| 模型 | LeetCode 周赛通过率 |
|---|---|
| Qwen3-4B | 55.0% |
| Qwen3-32B | 50.0% |
| Qwen3-30B (A3B) | 65.0% |
| Nanbeige4.1-3B | 85.0% |
20 道周赛题解出了 17 道,通过率 85%。在虚拟参赛模式下拿到过第 1 名和第 3 名。这个数据比刷基准更有说服力——LeetCode 周赛是全球程序员参与的实时竞赛,题目没有数据泄漏的嫌疑。
Qwen3-32B 只有 50%,还不如 3B 的 Nanbeige?这再次印证了代码 RL 两阶段训练策略的威力。
💡 技术亮点与个人思考
亮点一:训练流水线的工程美感
整个训练流程像一条精密的生产线:
| 阶段 | 解决的问题 | 核心手段 |
|---|---|---|
| SFT | 知识注入 + 长上下文 | 256K 扩展 + 批评修订循环 |
| Point-wise RL | 格式错误 + 冗余推理 | 通用奖励模型 + GRPO |
| Pair-wise RL | 偏好对齐 | 强弱对比 + 交换一致性 |
| Code RL Stage 1 | 代码正确性 | 沙箱验证 + pass rate 奖励 |
| Code RL Stage 2 | 代码效率 | 门控复杂度奖励 |
| Agentic RL | 多轮工具调用 | 回合级判断 + 轨迹过滤 |
每个阶段有且只有一个清晰的优化目标,不互相干扰。这种"分而治之"的设计哲学,比起"一锅炖"式的多目标联合训练要稳健得多。
打个比方:这就像培养一个全能运动员。你不会让他同时练短跑、游泳和射箭——而是先练好体能基础(SFT),再练爆发力(Point-wise RL),接着练协调性(Pair-wise RL),然后专项训练(Code RL + Agentic RL)。每个阶段的训练内容不同,但前一阶段是后一阶段的基础。
亮点二:门控复杂度奖励的克制
代码 RL 那个门控设计(只有全部测试通过才看复杂度)看似简单,实则体现了对 RL 训练稳定性的深刻理解。
多目标 RL 中最常见的灾难是奖励黑客(Reward Hacking)——模型找到一种同时拿到两个奖励高分但实际上没学到真本事的方式。门控机制切断了这条歪路:你不把代码写对,复杂度那边就是零分,不存在"牺牲正确性换复杂度"的操作空间。
亮点三:回合级判断的精细化
深度搜索的数据构建中,回合级判断是一个值得关注的创新。大多数 Agent RL 方法只看最终答案对不对(outcome-level reward),而 Nanbeige 对每一轮交互都做了细粒度评估(turn-level judgment)。
这就像考试改卷:只看最终答案,得 60 分的卷子可能有 20 种错法;但如果对每一步推理过程都评分,你就能精确地知道学生在哪个环节出了问题,反馈信号更加丰富。
不过这也带来了成本问题——每轮都要调裁判模型评估,数据构建的计算开销会成倍增长。论文没有披露具体的训练成本数据,但可以推测这是一个不小的投入。
几个值得关注的问题
1. 能力保持问题
论文展示了最终版本的基准分数,但没有报告多阶段 RL 过程中各项能力的变化曲线。比如,Code RL 之后数学能力有没有下降?Agentic RL 之后对齐质量有没有退化?"能力遗忘"在多阶段训练中是一个很现实的风险,知道中间过程的数据会更有说服力。
2. 基座模型的贡献
Nanbeige4-3B-Base 本身是怎么训练的?预训练数据是什么配比?这些信息论文没有详细披露。如果基座模型本身就很强(比如预训练阶段的代码数据配比就很高),那 RL 阶段的提升幅度就需要打个折扣。
3. 泛化性问题
整套流水线在 3B 这个规模上效果拔群,但换到 7B、14B 或更大的模型上,同样的方法还有这么大的边际收益吗?根据 scaling law 的一般规律,模型越大,来自训练方法的边际收益越小——因为基座本身已经足够强了。
📊 与其他小模型的横向对比
| 维度 | Nanbeige4.1-3B | Qwen3-4B | Phi-4-mini (3.8B) |
|---|---|---|---|
| 参数量 | 3B | 4B | 3.8B |
| 训练方法 | 多阶段 RL 流水线 | 标准 SFT+RL | 高质量数据混合+SFT |
| 代码能力 (LCB-V6) | 76.9 | 57.4 | ~50 (估计) |
| 数学能力 (AIME) | 87.4 | 81.5 | ~70 (估计) |
| Agent 能力 (GAIA) | 69.9 | 28.3 | 不支持 |
| 对齐 (Arena-Hard-V2) | 73.2 | 34.9 | ~45 (估计) |
| 长上下文 | 256K | 128K | 128K |
Nanbeige4.1-3B 在同规模模型中的优势非常明显,尤其是 Agent 能力几乎是独一档的存在。
🔧 工程落地建议
1. 小模型做 Agent 的可行性已经得到验证
如果你的业务场景需要部署一个多轮工具调用的 Agent,但受限于推理成本或延迟要求不能用大模型,3B 级别的模型已经是一个可行选项。关键在于训练数据和 RL 流程的设计,而不是盲目堆参数。
2. 两阶段 Code RL 值得借鉴
如果你在做代码生成相关的 RL 训练,"先优化正确性、再优化效率"的分阶段策略可以直接复用。门控奖励的设计也很容易实现——只需要在奖励函数里加一个 if 判断。
3. 回合级数据过滤可以提升 Agent 训练质量
构造 Agent 训练数据时,不要只看最终结果对不对,而是对轨迹中每一步都做质量评估。虽然成本更高,但过滤后的数据质量差距是肉眼可见的。
4. 成对 RL 的 Swap-Consistency 值得尝试
如果你在训练 reward model 且发现位置偏差问题严重,交换一致性正则化是一个简单有效的解法。实现起来只需要把 A/B 顺序对调后再推理一遍,然后在 loss 里加一个一致性惩罚项。
📝 总结
Nanbeige4.1-3B 这篇论文的价值不在于提出了什么全新的理论突破,而在于展示了一套极其精细的工程实践——怎么通过多阶段 RL 训练,把一个 3B 小模型的潜力榨干到极致。
代码能力上 LCB-V6 涨了 30+ 个点,对齐能力上超过了 32B 模型 17 个点,深度搜索上甚至打败了 671B 的 DeepSeek-V3.2——这些数据表明,小模型的能力天花板远没有到顶。
这篇论文给出的最重要启示是:当我们谈论模型能力时,不能只看参数量。训练流程、RL 策略、数据质量——这些"软件层面"的东西,可能比"硬件层面"的参数量更能决定模型的最终表现。
如果把训练大模型比作造火箭,那 Nanbeige 做的事情更像是精密调校引擎——同样一台引擎,调校好了能多飞几千公里。在"参数即正义"的大模型竞赛中,这种精细化工程能力同样值得尊重。
🔗 相关资源
- 论文:https://arxiv.org/abs/2602.13367
- 模型下载:https://huggingface.co/Nanbeige/Nanbeige4.1-3B
- GRPO 算法原始论文:DeepSeek-R1, DeepSeek AI, 2025
- LiveCodeBench:https://livecodebench.github.io/