扩散语言模型也能当搜索代理?DLLM-Searcher用"边想边搜"的并行范式干掉了自回归模型
论文标题:DLLM-Searcher: Adapting Diffusion Large Language Model for Search Agents
论文地址:https://arxiv.org/abs/2602.07035
代码地址:https://github.com/bubble65/DLLM-Searcher
作者:Jiahao Zhao, Shaoxuan Xu, Zhongxiang Sun, Fengqi Zhu, Jingyang Ou, Yuling Shi, Chongxuan Li, Xiao Zhang, Jun Xu
日期:2026年2月
🎯 一句话总结
DLLM-Searcher通过Agentic SFT + Agentic VRPO两阶段后训练把一个原本不会搜索的扩散语言模型(dLLM)训练成了搜索代理,并提出P-ReAct并行推理范式,让模型在等待搜索结果返回时继续思考,在四个多跳问答基准上平均ACC_R达57.0%超过R1Searcher的53.1%,同时推理速度提升15-22%。
📖 这篇论文在解决什么问题?
搜索代理(Search Agent)是当下AI领域的明星方向。用户抛出一个复杂问题,AI自己去搜索、浏览、推理、整合信息,给出最终答案。Search-o1、Search-R1、R1Searcher……过去一年涌现了一大批搜索代理,它们的骨干模型清一色是自回归模型(ARM)——也就是GPT、Qwen这类一个token接一个token生成的模型。
问题出在哪?慢。
搜索代理的工作流程是"想一步→搜一下→看结果→再想一步→再搜一下",这是个串行的循环。自回归模型每次生成推理文本时必须一个token一个token地往外"吐",生成完推理文本才能生成工具调用指令,工具调用结果返回后才开始下一轮生成。每一步都在等上一步完成——端到端延迟被拉得很长。
另一边,扩散语言模型(dLLM)正在崭露头角。LLaDA、SDAR、Dream这些模型用"先全部盖住、再逐步揭开"的方式生成文本——类似于你做完形填空,不是从左到右一个个填,而是同时看整篇文章,把最有把握的空先填上。这种机制天然支持并行解码,速度更快。
但dLLM有两个致命短板:
- 不会当代理——它们在推理和工具调用格式遵循上表现很差。论文分析了基础dLLM模型SDAR在搜索任务上的错误分布:31.2%空输出、28.4%不会调用工具、17.8%思考格式错误。加起来超过77%的case连基本格式都搞不定。
- 改变生成顺序会崩——在ARM中,如果你强制让模型先生成工具调用再写推理文本(本来是先想再调),性能会暴跌。dLLM呢?
DLLM-Searcher就是要解决这两个问题:让dLLM学会搜索,再让dLLM搜得快。
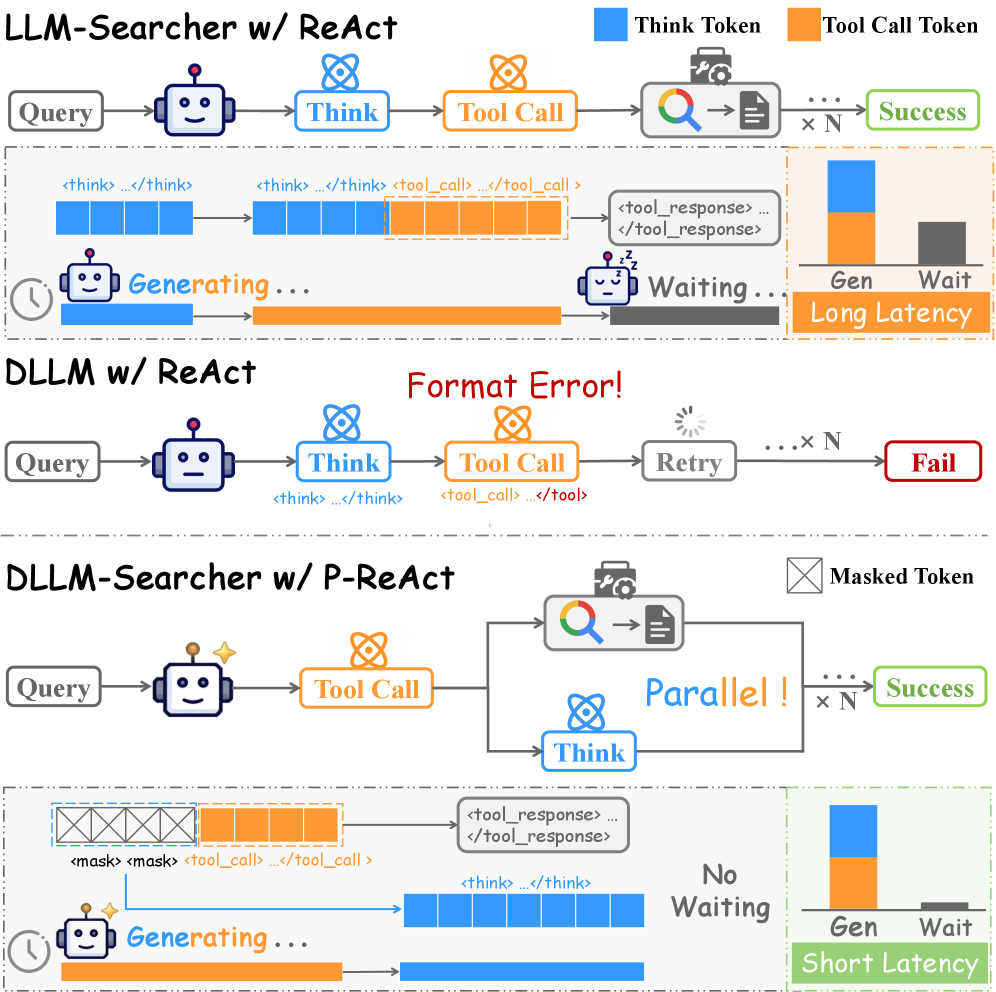
图1:左侧是传统ReAct范式——推理和工具调用严格串行;右侧是P-ReAct范式——工具调用先解码并发送,推理和等待并行进行。下方是dLLM的扩散生成过程示意
🧠 核心方法
DLLM-Searcher的方案分两条线:一条解决"能不能搜"(两阶段后训练),一条解决"搜得快不快"(P-ReAct)。
一、先搞懂扩散语言模型——它到底是怎么生成文本的?
在讲方法之前,需要理解dLLM和ARM的根本区别。
ARM(自回归模型)生成文本像写作文:从第一个字开始,写完第一个字才能写第二个字,写完第二个字才能写第三个字。严格从左到右,不能回头。
dLLM(扩散语言模型)生成文本像做完形填空:一开始整篇文章全是空格(掩码),模型看一遍所有空格,把最有把握的几个先填上,然后再看剩下的空格,再填一批……循环多次直到全部填完。关键区别是:它不受从左到右的顺序约束,可以先填中间的某个词,再填开头的某个词。
这意味着什么?想象你在做一道搜索题:你需要先想想该搜什么(think),再写出搜索指令(tool_call),等搜索结果回来后继续想。在ARM的世界里,"想"和"搜"必须严格排队。但在dLLM的世界里,"搜索指令"可以先被填上——因为模型可以先填它最确定的那部分——然后在等待搜索结果的同时,继续填充"推理"部分。
这就是DLLM-Searcher抓住的机会。
二、两阶段后训练:把不会搜索的dLLM训练成搜索代理
直接在原始dLLM上做搜索任务基本没戏——SDAR模型连工具调用格式都学不会。怎么办?
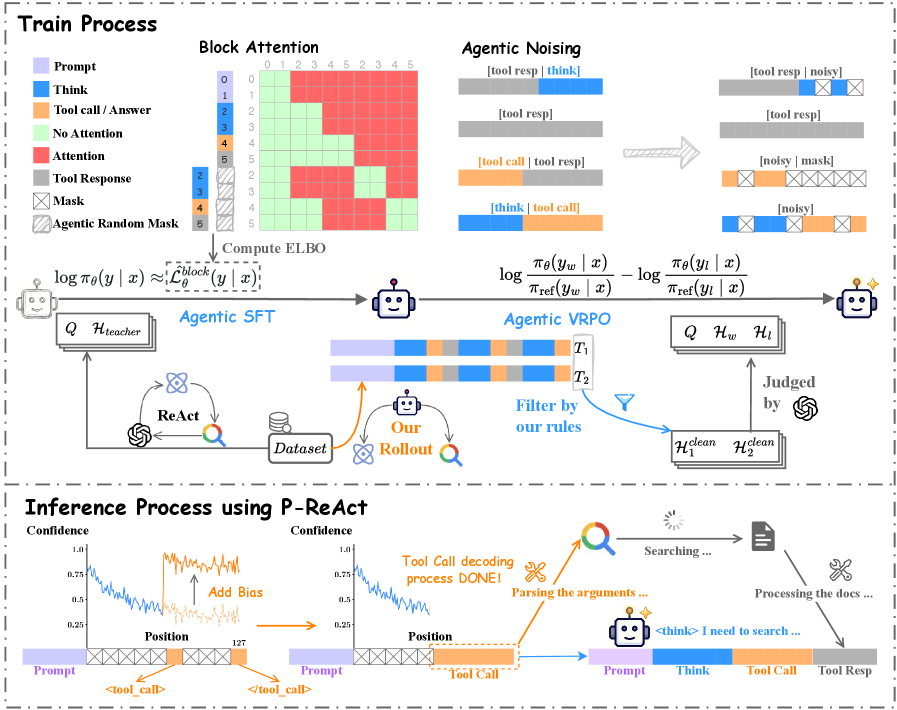
图2:DLLM-Searcher的完整训练流水线——从教师模型生成SFT数据,到Agentic SFT,再到Agentic VRPO
第一阶段:Agentic SFT(监督微调)
SFT阶段的目标很直接:教会dLLM搜索代理的基本"格式"和"套路"。
数据从哪来? 用一个高性能的教师模型(论文用的是doubao-seed-1.8)来"做题"。给教师模型一批多跳问答题,让它一步步搜索、推理、回答,记录整个轨迹。然后筛选:最终答案正确、推理步骤清晰、格式严格合规的轨迹才保留。最终产出6000条高质量SFT轨迹。
训练时有个关键问题:工具响应的信息泄露。
想象一个搜索轨迹:[think]我需要搜索XXX[/think][tool_call]search("XXX")[/tool_call][tool_response]搜索结果是YYY[/tool_response]
在ARM中,模型从左到右生成,生成think和tool_call时天然看不到后面的tool_response——因为还没生成到那里。但dLLM不一样,它是"同时看全文再填空"。如果训练时让模型看到了tool_response的内容,它就可能"作弊"——根据已知的搜索结果来反推应该怎么思考,而不是真正学会搜索策略。
论文提出了两个针对性设计来堵住这条路:
(1)Agentic Noising(智能体噪声注入)
标准的扩散训练是对整个序列均匀加噪。Agentic Noising则区分对待: - 如果一个块(block)内,工具响应出现在生成内容(think/tool_call)之前——存在泄露风险,把工具响应位置强制设为掩码,让模型看不到 - 如果生成内容在前、工具响应在后——符合因果逻辑,保持工具响应不变
这套规则保证了:模型在学习生成think和tool_call时,永远不会偷看到后面的tool_response。
(2)Agentic ELBO(智能体证据下界)
标准的扩散训练损失函数会对整个序列的所有位置计算损失。但工具响应(tool_response)是外部环境返回的,不应该让模型去"学习生成"这些内容。Agentic ELBO在损失计算时排除了所有工具响应位置:
比标准ELBO多了一个条件 \((y^{k,i} \notin [\texttt{R}])\)——只在"当前位置是掩码 且 该位置不属于工具响应"时才计算损失。这样模型只学怎么想、怎么调用工具,不学怎么"生成搜索结果"。
第二阶段:Agentic VRPO(方差减少偏好优化)
SFT让模型学会了基本格式,但推理质量还有提升空间。VRPO是进一步的"练功"阶段。
VRPO的全称是Variance-Reduced Preference Optimization,来自LLaDA 1.5。它的思路和DPO(Direct Preference Optimization)很像:给模型看两条轨迹——一条答对了(胜者),一条答错了(败者)——让模型学会偏好正确的那条。
具体做法: 1. 用SFT后的模型对同一个问题跑两轮采样 2. 筛选出格式合规但结果一对一错的轨迹对 3. 用VRPO损失函数训练:
其中 \(\Delta\mathcal{L}(y|x)\) 是当前策略与参考策略的Agentic ELBO差值。
为什么叫"方差减少"?dLLM的似然估计(ELBO)本身就是一个估计量,方差比ARM的对数似然大得多。VRPO通过对比"胜者-败者"的相对差值来消减部分方差,让训练更稳定。
三、P-ReAct:让搜索代理"边想边等"
P-ReAct(Parallel-Reasoning and Acting)是论文最亮眼的设计。它完全不需要额外训练,只是在推理阶段对解码策略做了两个修改。
传统ReAct的流程:
P-ReAct的流程:
怎么实现"优先解码工具调用"?两个技巧:
(1)特殊Token预填充
在解码开始前,在序列的指定位置预填充<tool_call>和</tool_call>标记,圈定"工具调用区域"在哪里。
(2)置信度偏置
在每一步解码迭代中,给工具调用区域内的token加一个正偏置 \(\alpha\)。dLLM的解码策略是"先揭开置信度最高的位置"——加了偏置后,工具调用区域的token会优先被解码。工具调用指令一旦解码完成,立即发送给搜索引擎,同时模型继续解码剩余的推理文本。
这里有个关键问题:ARM能不能也这么干?不能。ARM必须从左到右生成,如果你强制让它先生成后面的tool_call再回头补前面的think,生成质量会断崖式下跌——论文的实验(图4)证实了这一点。但dLLM天生支持"哪里确定先填哪里",改变生成顺序对性能影响极小,甚至在部分数据集上还有提升。
这就是dLLM在代理场景的独特优势:生成顺序的灵活性。
🧪 实验结果
主实验:在四个多跳问答基准上的表现
论文在HotpotQA、2WikiMultiHopQA、Bamboogle、Musique四个多跳问答基准上做了全面评估。评估指标有两个:ACC_R(规则匹配,检查标准答案是否包含在预测中)和ACC_L(LLM-as-Judge,用doubao-seed-1.8评判)。
| 模型 | 类型 | HotpotQA | 2Wiki | Bamboogle | Musique | 平均ACC_R | 平均ACC_L |
|---|---|---|---|---|---|---|---|
| SuRe | 传统RAG | 32.4 | 22.2 | 17.6 | 7.2 | 19.9 | 28.3 |
| IRCoT | 传统RAG | 48.8 | 41.0 | 32.0 | 11.6 | 33.4 | 37.2 |
| ReARTeR | 传统RAG | 46.8 | 55.4 | 49.6 | 29.6 | 45.4 | 47.2 |
| Search-o1 | ARM Agent | 40.8 | 47.0 | 49.6 | 15.2 | 38.2 | 43.9 |
| Search-R1 | ARM Agent | 49.6 | 46.0 | 47.2 | 28.0 | 42.7 | 48.6 |
| WebSailor* | ARM Agent | 50.4 | 59.4 | 57.6 | 22.0 | 47.4 | 51.9 |
| R1Searcher* | ARM Agent | 58.0 | 59.6 | 66.4 | 28.2 | 53.1 | 56.5 |
| SDAR | dLLM | / | / | / | / | / | / |
| Dream | dLLM | 11.0 | 13.6 | 12.0 | 3.8 | 10.1 | 10.1 |
| LLaDA | dLLM | 36.0 | 42.0 | 46.4 | 15.2 | 34.9 | 32.5 |
| DLLM-Searcher | dLLM Agent | 60.4 | 69.8 | 68.8 | 29.0 | 57.0 | 56.6 |
(*表示在修改的实验设置下获得的结果;/表示模型无法生成有效工具调用)
几个关键发现:
1. DLLM-Searcher是第一个超过ARM搜索代理的dLLM模型。 平均ACC_R 57.0%,超过最强ARM基线R1Searcher的53.1%(+3.9)。在2Wiki上的优势最大:69.8% vs 59.6%(+10.2)。
2. 原始dLLM在搜索任务上近乎无用。 SDAR完全失败(全部/),Dream只有10.1%,LLaDA好一些但也只有34.9%。经过两阶段后训练,DLLM-Searcher从LLaDA基线的34.9%跃升到57.0%——提升了22.1个绝对百分点。
3. Musique是所有模型的难点。 不管是ARM还是dLLM,在Musique上的分数都显著低于其他三个基准。DLLM-Searcher的29.0%虽然是dLLM中最高的,但和2Wiki上的69.8%差距巨大。Musique的多跳推理链更长更复杂,这是当前搜索代理的共性瓶颈。
消融实验:SFT和VRPO各贡献了多少?
| 数据集 | 指标 | SFT | VRPO | 提升 |
|---|---|---|---|---|
| HotpotQA | ACC_R | 57.2 | 60.4 | +3.2 |
| HotpotQA | ACC_L | 58.8 | 62.4 | +3.6 |
| 2Wiki | ACC_R | 66.4 | 69.8 | +3.4 |
| 2Wiki | ACC_L | 61.6 | 64.6 | +3.0 |
| Bamboogle | ACC_R | 64.6 | 68.8 | +4.2 |
| Bamboogle | ACC_L | 64.0 | 69.6 | +5.6 |
| Musique | ACC_R | 24.4 | 29.0 | +4.6 |
| Musique | ACC_L | 26.6 | 29.8 | +3.2 |
VRPO在每个数据集上都稳定带来3-5.6个百分点的提升。提升最大的是Bamboogle的ACC_L(+5.6),最小的是2Wiki的ACC_L(+3.0)。这说明偏好优化阶段确实让模型学会了在"对的轨迹"和"错的轨迹"之间做出更好的区分。
论文还做了一个有趣的错误分析,看基础SDAR模型到底是怎么挂的:
| 错误类型 | 数量 | 占比 |
|---|---|---|
| 空输出 | 156 | 31.2% |
| 不调用工具 | 142 | 28.4% |
| 思考格式错误 | 89 | 17.8% |
| 工具调用格式错误 | 35 | 7.0% |
超过77%的错误是格式层面的——模型根本不知道该怎么输出搜索代理的标准格式。这也验证了Agentic SFT的必要性:第一步就是教会dLLM"说人话"(代理格式的话)。
P-ReAct的加速效果
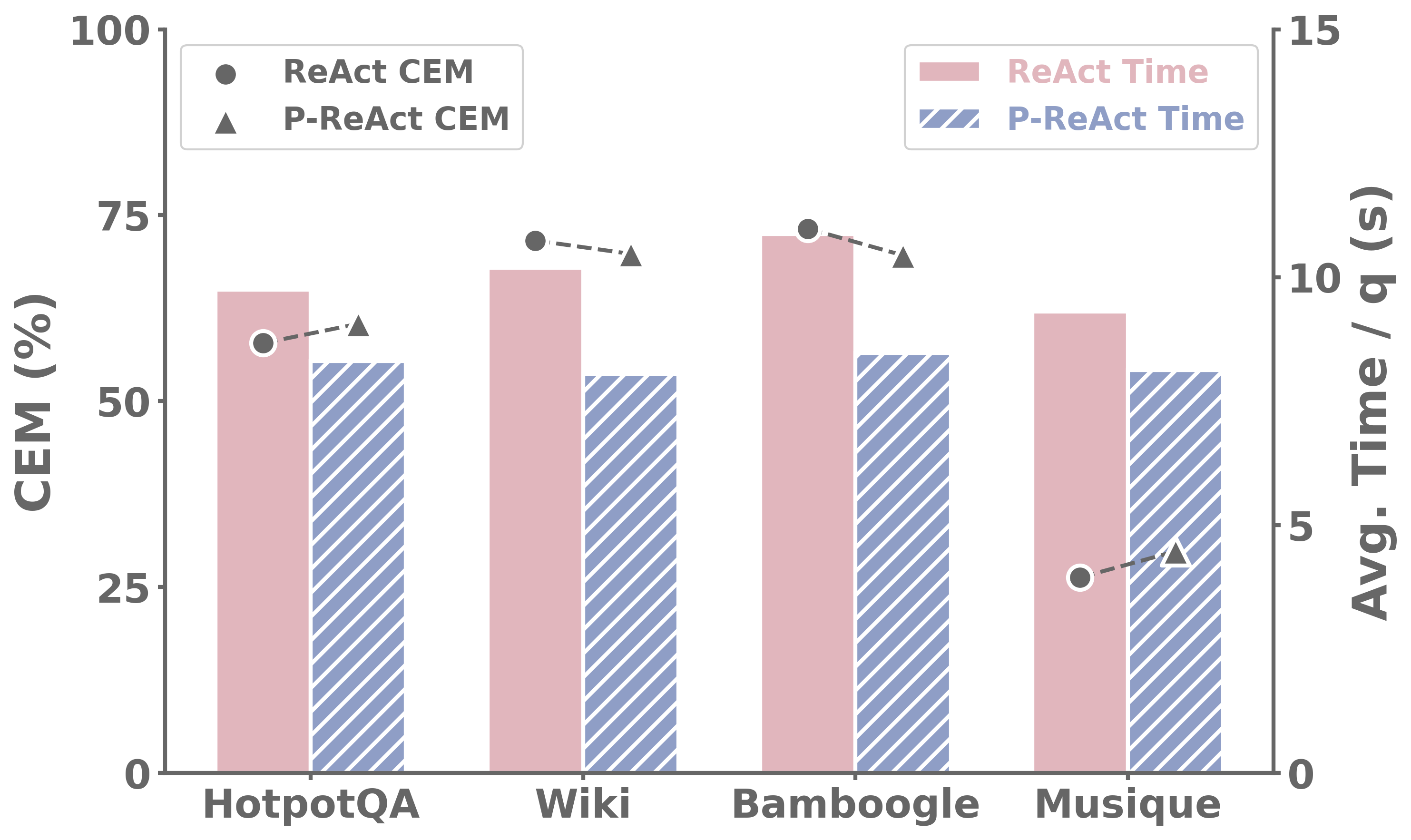
图3:标准ReAct和P-ReAct在四个基准上的推理时间对比
P-ReAct在四个基准上分别减少了: - HotpotQA:14.77% - 2Wiki:21.00% - Bamboogle:22.08% - Musique:12.67%
加速比例在12-22%之间,平均约17.6%。这个加速是"免费"的——不需要任何额外训练,纯粹靠解码策略的调整。而且,P-ReAct在加速的同时性能没有下降,甚至在HotpotQA和Musique上ACC_R还略有提升。
为什么Musique的加速最小?因为Musique的搜索轮次最多,每轮的搜索等待时间在总耗时中的占比相对较低——推理本身的时间占了更大比重。
dLLM vs ARM:改变生成顺序的鲁棒性
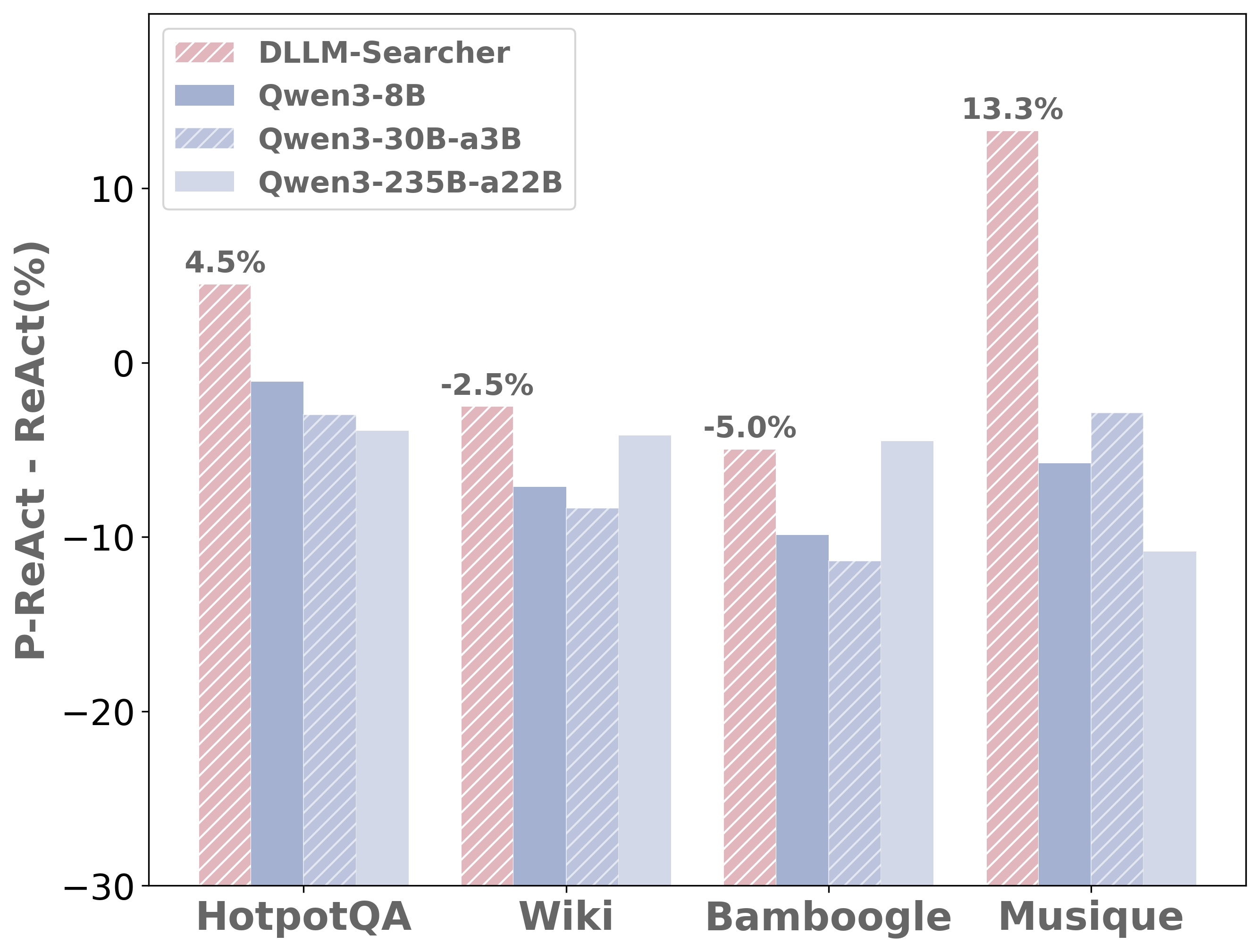
图4:强制优先生成tool_call时,dLLM和ARM的性能变化对比
这张图是全文最有说服力的实验之一。
当强制让模型优先生成tool_call(而不是按自然顺序先think再tool_call)时: - ARM模型(Qwen3系列):性能显著下降,某些数据集上跌幅超过10个点 - DLLM-Searcher:性能波动极小,在HotpotQA和Musique上甚至还有提升
这个结果揭示了dLLM在代理场景的核心优势:双向注意力机制让dLLM能做"隐式推理"。即使先解码了工具调用指令,模型在后续解码推理文本时仍然能通过双向注意力"回看"之前解码的内容——它不受因果遮罩的限制。ARM做不到这一点,因为因果注意力遮罩让每个位置只能看到左边的内容。
💡 我的思考
扩散语言模型在代理场景的独特价值
过去一年,dLLM领域的讨论主要集中在"它能不能追上ARM的生成质量"。DLLM-Searcher给出了一个新的视角:不用追上,用差异化赢。dLLM在生成质量上可能暂时不如同参数量的ARM,但它的并行解码和灵活生成顺序在代理场景有天然优势。
搜索代理的瓶颈不是单次生成的质量,而是"想一步搜一下"这个串行循环的累积延迟。P-ReAct用一种极其简洁的方式(两个推理技巧,不到20行代码)把这个延迟砍掉了15-22%。随着搜索轮次增多,节省的时间会线性累积。
Agentic Noising的设计很聪明
防止信息泄露这个问题在ARM中根本不存在——因果注意力自动保证了"未来信息不可见"。但dLLM的双向注意力打开了潘多拉魔盒。Agentic Noising的解法很精巧:根据工具响应在块内的相对位置,动态决定是遮掩还是保留。这个设计不局限于搜索场景——任何涉及"模型生成 + 环境反馈"交替的代理场景都会遇到同样的问题。
当前的局限
- 基座模型受限:论文用的是SDAR(基于LLaDA),参数量和训练量都不算大。如果换成更强的dLLM基座,上限会高多少?没有实验。
- 评估范围偏窄:四个多跳问答基准,没有测试更复杂的搜索场景(如BrowseComp这种需要数十轮搜索的长时程任务)。在更长轨迹上P-ReAct的优势是否会放大?
- 和闭源模型的差距仍然很大:论文的baseline里没有GPT-5、Seed1.8这些闭源巨头,也没有和REDSearcher、Kimi K2.5这类最新的开源搜索代理对比。DLLM-Searcher是"dLLM做代理"这条路的先行者,但离实际部署还有距离。
- P-ReAct的加速来源单一:目前只利用了"工具调用等待时间"这一部分。如果搜索引擎响应很快(毫秒级),加速效果会大幅缩减。
未来方向
这篇论文开了一个口子:不是所有AI代理都必须用自回归模型来做。dLLM的灵活解码机制还有很多可以挖掘的地方——比如在多工具并行调用场景中,dLLM可以同时解码多个工具调用指令;比如在多代理协作中,dLLM可以在等待其他代理响应的同时继续推理。P-ReAct只是第一步。
📝 总结
DLLM-Searcher证明了一件事:扩散语言模型不是自回归模型的低配替代品,而是在特定场景下有独特优势的不同范式。通过Agentic SFT + Agentic VRPO的两阶段训练,它把一个不会搜索的dLLM(基础模型SDAR搜索任务成功率为0)训练到了超过最强ARM搜索代理的水平(ACC_R 57.0% vs R1Searcher 53.1%)。P-ReAct用不到20行代码的推理策略修改,实现了15-22%的加速,且不损失精度。
Agentic Noising和Agentic ELBO这两个设计解决了dLLM做代理时特有的信息泄露问题,是把扩散训练范式适配到"模型生成+环境反馈"交替场景的通用方案。这套方法论不局限于搜索代理——代码执行、数据库查询、API调用等任何涉及工具交互的代理场景,都可能从中受益。